
Dataphin可以自动做维度退化吗? 或者手动配置维度退化,还是需要在事实表内手动地加上冗余的维度
Dataphin可以自动做维度退化吗? 或者手动配置维度退化,还是需要在事实表内手动地加上冗余的维度属性,那么如果我根据经验, 希望把一些维度属性字段(比如商品名称)冗余在事实表中, 是应该手动在事实表内添加字段, 关联上对应的(如商品名称)维表, 这种做法可以吗? 在创建派生指标的时候, 统计粒度选择时, 同一个维度就会有多个选项, 没关系吧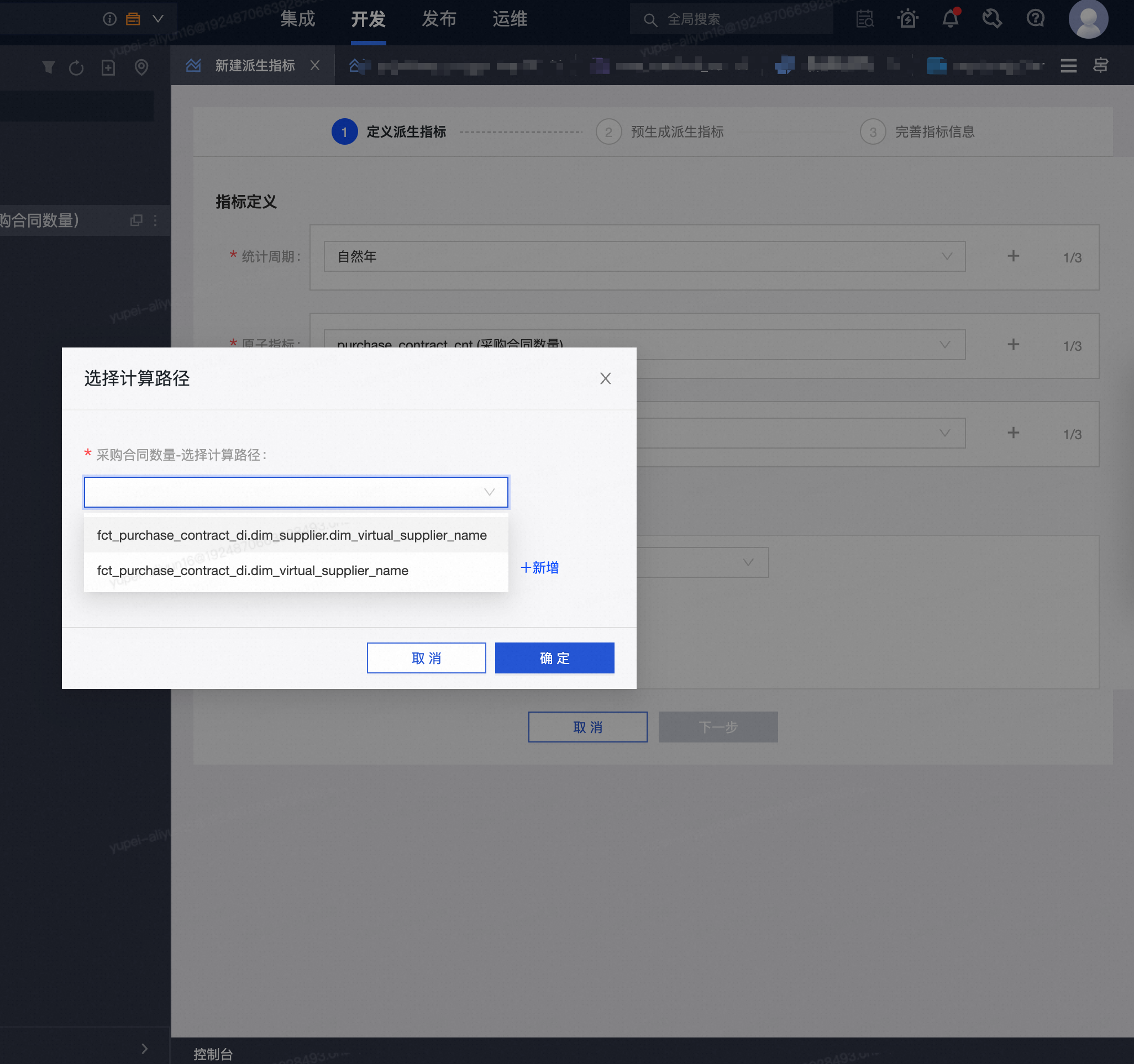
比如图中的供应商名称, 事实表和供应商维度表中都有该字段, 都关联了供应商名称维表的主键, 那么这里选择统计粒度的计算路径时, 上下两个应该都可以吧
-

在Dataphin中,维度退化是需要手动配置的。您可以选择在事实表中手动添加冗余的维度属性,并与对应的维表进行关联。这种做法是可行的,可以根据业务需求和数据模型的设计选择是否在事实表中添加冗余字段。
在创建派生指标时,统计粒度选择时可能会出现多个选项,这是因为根据数据模型的设计,有不同层级的统计粒度可供选择。这个根据具体情况来看,您可以选择适合您业务需求的统计粒度进行配置。
2023-07-27 22:38:26赞同 展开评论 打赏 -
 北京阿里云ACE会长
北京阿里云ACE会长在 Dataphin 中,维度退化是一种常见的数据建模技术,可以将高基数的维度属性从维度表中冗余到事实表中,以提高查询性能和降低数据模型的复杂度。Dataphin 并没有提供自动做维度退化的功能,但可以通过手动配置来实现维度退化。
如果希望将某些维度属性冗余到事实表中,可以手动在事实表中添加对应的字段,并关联上对应的维度表。在创建派生指标时,可以根据需要选择不同的统计粒度,如果同一个维度出现了多个选项,可以根据具体情况选择合适的统计粒度。
2023-07-27 11:00:49赞同 展开评论 打赏 -
 云端行者觅知音, 技术前沿我独行。 前言探索无边界, 阿里风光引我情。
云端行者觅知音, 技术前沿我独行。 前言探索无边界, 阿里风光引我情。在Dataphin中,可以通过手动配置维度退化或在事实表中添加冗余的维度属性来实现维度退化。这种做法是常见的数据建模技术之一,可以根据具体的业务需求和数据分析场景来决定是否采用。
如果您希望在事实表中冗余一些维度属性(如商品名称),并与对应的维表进行关联,这是一种常见的做法。通过在事实表中添加冗余字段,可以提高查询性能和简化查询操作,避免频繁地关联维度表。
在创建派生指标时,如果选择了不同的统计粒度,会出现多个选项。这是因为不同的统计粒度可能需要不同的维度属性来支持计算。您可以根据具体的业务需求和分析要求,选择适当的统计粒度和相关的维度属性。
需要注意的是,冗余维度属性可能会增加数据冗余和维护成本。在使用冗余维度属性时,需要确保数据的一致性和更新机制,以避免数据不一致的问题。
手动在事实表中添加冗余的维度属性是一种常见的做法,可以根据具体的业务需求和数据分析场景来决定是否采用。在使用冗余维度属性时,需要综合考虑性能、数据一致性和维护成本等因素。
2023-07-25 18:59:03赞同 展开评论 打赏 -

在阿里云Dataphin中,维度退化是一种常见的数据建模技术,可以帮助您简化数据模型和提高查询效率。通常情况下,如果一个维度表中的属性在事实表中只被用作过滤条件,而不需要进行聚合计算,那么这些属性可以被称为“维度退化”,并直接冗余到事实表中。
在Dataphin中,您可以手动配置维度退化,将维度表中的属性冗余到事实表中。具体来说,您可以在事实表中手动添加冗余的维度属性字段,并关联上对应的维度表。这样做的好处是可以减少关联操作和提高查询效率,但是也会增加数据冗余和维护成本。
在创建派生指标时,统计粒度选择同一个维度会出现多个选项是正常的。这是因为不同的统计粒度需要不同的维度属性组合,例如按照年、月、日进行统计时需要不同的日期属性组合。您可以根据具体的业务需求选择合适的统计粒度和维度属性组合。
2023-07-24 23:51:27赞同 展开评论 打赏 -

在Dataphin中,维度退化是指将某些维度属性冗余到事实表中,以减少与维度表的关联查询次数,提高查询性能。您可以手动在事实表中添加冗余字段,并关联对应的维度表来实现这种冗余。
如果您希望将维度属性(如商品名称)冗余在事实表中,并关联对应的维度表,这种做法是可行的。通过在事实表中添加字段并存储冗余的维度属性,可以避免每次查询都需要进行关联操作,从而提升查询效率。
当创建派生指标时,统计粒度选择时可能会出现多个选项,这是因为系统会自动识别出可能的统计粒度,包括原始维度表和可能存在的冗余字段。您可以根据需求选择适合的统计粒度。
请注意,在进行维度退化时,需要权衡数据冗余和存储成本之间的平衡,并确保数据一致性。此外,还要考虑数据更新和维护的复杂性。如果您有任何疑问或需要进一步的指导,请咨询Dataphin团队或参考Dataphin平台文档,以获得更具体和准确的解决方案。
2023-07-24 15:47:12赞同 展开评论 打赏 -
目前还不支持维度退化。可以进行关联,事实表关联维度表,是关联的维表的主键,统计粒度中选择的也是维表的主键。这样配置是可以的,第一个粒度更细一些;需要看看计算结果值是否符合预期,,此回答整理自钉群“Dataphin公共云答疑群”
2023-07-24 15:12:47赞同 展开评论 打赏


版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。






