
DataWorks改了后现在第10列的数据传到了本该第11列的位置去了,我oss文件名是中文名,?
DataWorks改了后现在第10列的数据传到了本该第11列的位置去了,我oss文件名是中文名,这个有影响吗要改成英文吗?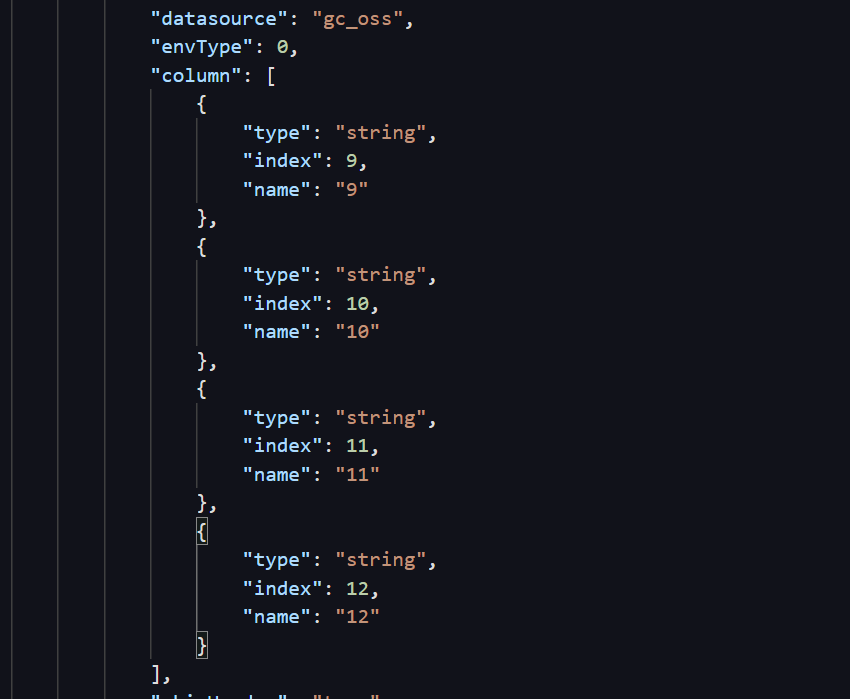
K是第10列撒,0开始计数的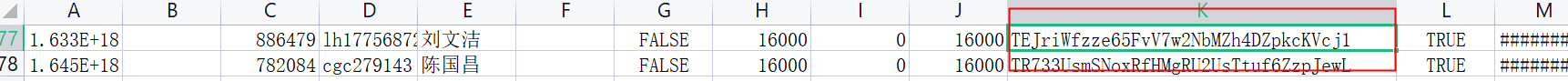
我把文件改为英文名也是一样的问题,还是不行
-
 北京阿里云ACE会长
北京阿里云ACE会长在DataWorks中,如果你的数据在写入过程中发生了列位置错位的问题,并且你的OSS文件名是中文名,可能是由于以下原因导致的:
字符编码问题:中文文件名可能涉及到字符编码的处理。在数据写入过程中,如果字符编码设置不正确,可能导致数据读取和解析错误,从而导致列位置错位。请确保在数据写入过程中正确设置字符编码,以适应中文文件名的读取和解析。
数据源读取设置:在DataWorks中,数据源读取的设置也可能影响到数据的解析和列位置。请检查数据源读取的设置,包括分隔符、引号包裹等,确保与实际数据的格式一致,以正确解析数据并将其写入到指定的列位置。
列映射设置:在数据写入过程中,可能需要设置列映射,将文件中的列与目标表中的列进行对应。请检查列映射的设置,确保将第10列的数据正确映射到目标表的第11列。
数据格式转换:如果数据源中的数据格式与目标表中列的数据类型不匹配,可能导致数据写入错误的列位置。请确保在数据写入过程中进行必要的数据格式转换,以保证数据类型的一致性。
2023-07-30 17:23:59赞同 展开评论 打赏 -

当在DataWorks中进行数据处理或转换时,如果出现数据位置错乱的情况,并且您的OSS文件名是中文名,可能是由以下原因引起的:
字符编码问题:如果OSS文件名包含非ASCII字符(如中文),请确保您在DataWorks中正确地指定了文件名的字符编码格式。一般来说,应该选择UTF-8编码以支持中文字符。
数据解析错误:如果在数据处理过程中使用了某种解析方法或规则来读取OSS文件并将其转换成表格数据,可能存在解析错误导致数据位置错乱。请检查您的数据解析逻辑和转换规则是否正确,并确保它们适用于包含中文文件名的场景。
字段分隔符问题:如果您的OSS文件是以某个字段分隔符作为列之间的分隔符,而该字段分隔符与中文文件名冲突,可能会导致数据位置错乱。请确保您选择了正确的分隔符,并适配了中文文件名的情况。
数据清洗问题:在数据处理过程中,如果执行了数据清洗操作(例如删除特定字符、替换数据等),请确保您的清洗逻辑没有影响到数据位置。
建议您仔细检查以上可能的原因,并逐一排除,以确定导致数据位置错乱的具体原因。如果问题仍然存在,建议您联系DataWorks技术支持或阿里云客服人员,提供详细的操作步骤和错误信息,以便他们帮助您进一步解决问题。
2023-07-23 13:01:46赞同 展开评论 打赏 -

index从0开始计算,按照这个红线脚本里 index是不是要填 4 5 6 3
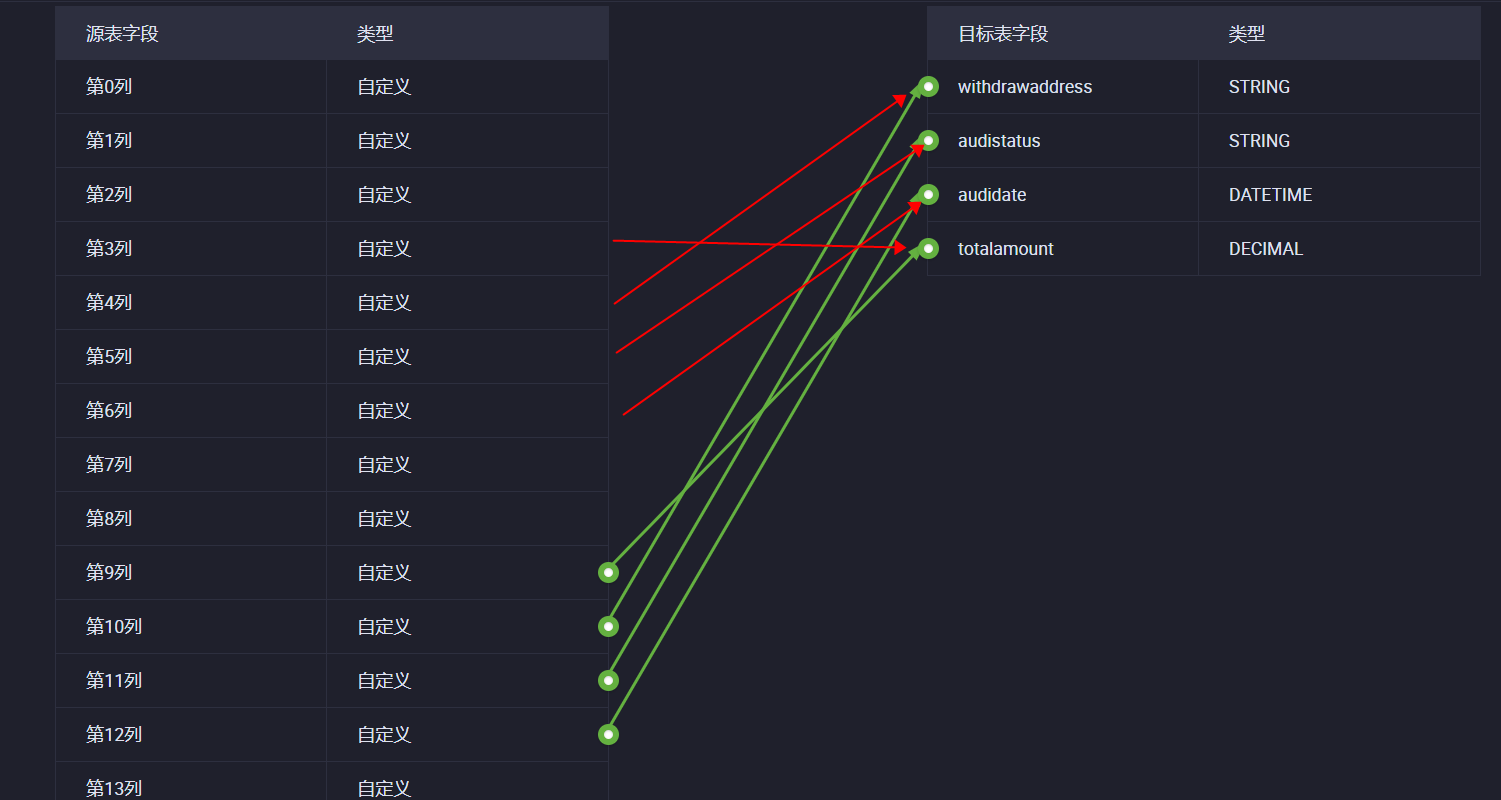
红线是运行出来的结果,我本来应该是对应的是10,11,12,9,此回答整理自钉群“DataWorks交流群(答疑@机器人)”2023-07-22 16:26:37赞同 展开评论 打赏

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。

DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。





