
flinkcdc 表和源表能分开部署么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink CDC的设计理念,表和源表是紧密相关的,它们通常是在同一个数据库中。Flink CDC通过订阅数据库的变更日志来捕获数据的变化,因此源表的变更日志是Flink CDC的输入。如果将表和源表分开部署,可能会导致无法正常获取源表的变更日志,从而影响Flink CDC的正常运行。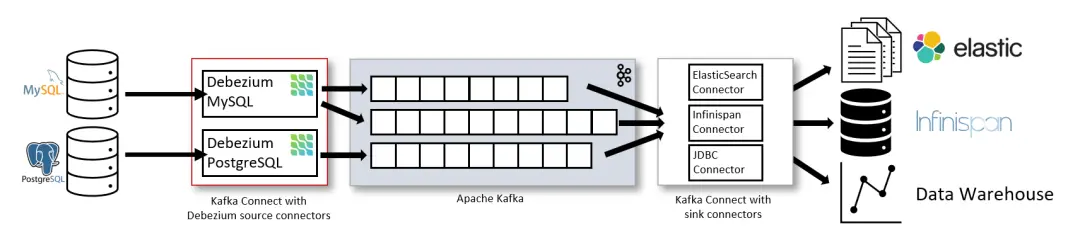
如果您有特殊的需求,需要将表和源表分开部署,可以考虑以下两种方案:
1、使用数据库的复制或同步机制,将源表的变更日志同步到另一个数据库中,然后在该数据库上运行Flink CDC。
2、自定义开发一个数据采集工具,将源表的变更信息以其他形式传输到Flink CDC的输入端。
需要注意的是,这些方案可能会引入额外的复杂性和延迟,并且需要根据具体的场景和要求进行详细的设计和实现。
楼主你好,可以分开部署。在使用阿里云Flink CDC时,可以将数据源表和CDC表分别部署在不同的数据库实例中。这样做的好处是减少对源表的影响,并且可以提高CDC任务的可靠性和性能。具体来说,可以将源表部署在一个数据库实例中,将CDC表部署在另一个数据库实例中,通过Flink的CDC功能来实现数据的实时同步。
是的,Flink CDC 的表和源表可以在不同的部署环境中进行分开部署。这意味着您可以将 Flink CDC 作为一个独立的组件运行,并且可以从一个或多个源表中捕获变更数据。
通过将 Flink CDC 和源表分开部署,您可以实现以下优势:
解耦:将 Flink CDC 与源表分开部署可以实现逻辑的解耦。您可以单独管理和扩展 Flink CDC 组件,而不会对源表的部署和管理造成干扰。
灵活性:您可以根据需求灵活地部署 Flink CDC 组件以及源表。这样,您可以根据负载、容量、可用性和性能等因素,对 Flink CDC 和源表进行独立的调整和优化。
可维护性:将 Flink CDC 和源表分开部署还有助于提高系统的可维护性。例如,当需要升级或维护 Flink CDC 组件时,您可以单独操作而无需中断源表的正常运行。
请注意,在将 Flink CDC 与源表分开部署时,您需要确保 Flink CDC 可以访问到源表的变更数据。这可能需要配置适当的网络连接、权限和访问凭证等。
可以分开部署,Flink CDC 任务的表和源表可以分开部署。在这种情况下,你需要在两个不同的 Flink 节点上分别运行 CDC 任务和数据源任务。这样做的好处是,你可以将不同的任务分别部署在不同的节点上,以提高任务的可扩展性和容错性。
当你将 CDC 任务和数据源任务分开部署时,你需要确保它们之间的数据同步是可靠的。一种常见的做法是,你可以在数据源任务和 CDC 任务之间使用一个 Kafka 或其他消息队列系统,以实现数据的可靠传输。这样做的好处是,如果数据源任务或 CDC 任务出现故障,你可以通过重试或其他机制来保证数据的可靠性。
在将 CDC 任务和数据源任务分开部署时,你需要仔细考虑如何设置参数和配置,以确保 CDC 任务能够正确地收集和处理数据。例如,你需要考虑如何设置 log.mining.batch.size.max 参数的值,以控制 CDC 任务对数据源的采集速率。此外,你还需要考虑如何设置 CDC 任务的输出格式和目标表的结构,以确保数据能够正确地写入目标表中。
在 Flink CDC 中,源表和目标表(或称为结果表)是紧密相关的,它们通常需要在同一个 Flink Job 中进行配置和处理。因此,一般情况下,源表和目标表需要在同一个 Flink 集群中部署。
源表是指需要进行数据变更捕获的表,通常是数据库中的某个表。而目标表是指捕获到的数据变更经过处理后写入到的表或者其他目的地。
Flink CDC 通过监控数据库的 binlog 或者其他方式来捕获源表的数据变更,并将变更数据传递给 Flink Job 进行处理。因此,源表需要与 Flink Job 所在的集群保持连接,并确保数据变更能够被 Flink CDC 捕获到。
另一方面,Flink Job 在接收到源表的数据变更后,会对数据进行处理和转换,最终写入到目标表或者其他目的地。因此,目标表也需要与 Flink Job 所在的集群保持连接,并确保 Flink Job 可以将结果写入到目标表。
可以,Flink CDC 表和源表可以分开部署。
Flink CDC 是一种实时数据同步工具,它能够捕获源数据库的变更数据,并将这些数据实时同步到目标系统。在Flink CDC的架构中,源数据库和Flink集群是独立的,不需要部署在一起。
要实现Flink CDC 表和源表的分开部署,需要遵循以下步骤:
在Flink集群中配置Flink CDC源,以捕获源数据库的变更数据。
将捕获的变更数据实时同步到目标系统,例如HDFS、HBase、Elasticsearch等。
是的,Flink CDC支持将表和源表分开部署。您可以将Flink CDC任务部署到一个独立的集群上,将源表部署到另一个集群上,或者将Flink CDC任务和源表部署到不同的虚拟机或容器中。
需要注意的是,如果您将Flink CDC任务和源表分开部署,那么您需要在两个集群之间建立数据同步通道,以保证Flink CDC任务能够读取到源表的数据。您可以使用Flink CDC提供的TableFunction接口,自定义一个TableFunction实现类,对读取到的数据进行特殊过滤,以避免出现表字段变少的情况。

