
老师请问下,StructBERT FAQ问答-中文-通用领域-base这个模型,加载自己本地数据训练,格式是什么啊?
StructBERT是一种基于BERT的预训练模型,用于处理结构化数据。如果您想在本地加载自己的数据进行训练,您需要将数据转换为适当的格式。
以下是一些常见的结构化数据格式:
JSON:JSON是一种轻量级的数据交换格式,通常用于Web应用程序中。您可以将您的数据保存为JSON文件,并将其用作StructBERT的输入。
CSV:CSV是一种逗号分隔值文件格式,通常用于存储表格数据。您可以将您的数据保存为CSV文件,并将其用作StructBERT的输入。
XML:XML是一种标记语言,通常用于存储和传输结构化数据。您可以将您的数据保存为XML文件,并将其用作StructBERT的输入。
无论您选择哪种格式,您需要确保您的数据包含适当的标签和字段,以便StructBERT可以正确地解析和处理它们。您可以使用Python中的pandas库来读取和处理这些文件。
以下是一个使用pandas读取CSV文件的示例代码:
import pandas as pd
# 读取CSV文件
data = pd.read_csv('your_data.csv')
# 将数据转换为DataFrame格式
df = pd.DataFrame(data)
# 将DataFrame作为StructBERT的输入
input_ids = df['input_id'].tolist()
attention_masks = df['attention_mask'].tolist()
segments = df['segments'].tolist()
labels = df['label'].tolist()
input_ids = torch.tensor(input_ids).unsqueeze(0)
attention_masks = torch.tensor(attention_masks).unsqueeze(0)
segments = torch.tensor(segments).unsqueeze(0)
labels = torch.tensor(labels).unsqueeze(0)
请注意,这只是一个简单的示例代码,您需要根据您的具体需求进行修改和调整。
StructBERT是一种预训练模型,它结合了BERT和结构化信息的特点,用于问答任务。要加载自己的本地数据进行训练,你需要按照一定的格式准备你的数据。下面是加载自己本地数据进行训练时的数据格式说明:
例如,一个包含两个样本的数据集可能如下所示:
[ {"question": "什么是人工智能?", "answer": "人工智能是一门研究如何使计算机可以智能地思考和行动的学科。"}, {"question": "机器学习是什么?", "answer": "机器学习是一种人工智能的分支,它关注计算机系统如何通过经验学习提高性能。"} ]
一旦你准备好了数据,你可以使用StructBERT提供的训练脚本来加载数据并进行训练。具体的代码实现细节和使用方法可以参考StructBERT的官方文档或示例代码。请注意,具体的实现可能会因不同的代码库或框架而有所差异,因此你需要参考相关文档以获得准确的指导。
StructBERT FAQ问答-中文-通用领域-base模型是基于预训练的语言模型StructBERT,在通用领域下用于问答任务的模型。如果你想要加载自己本地的数据对该模型进行微调训练,你需要准备符合特定格式的训练数据。
StructBERT模型用于问答任务,一般的数据格式应该是类似于问答对(Question-Answer)的形式。以下是一个简单的示例:
{
"data": [
{
"paragraphs": [
{
"context": "这是一段文本,包含问题和答案的上下文。",
"qas": [
{
"question": "问题1",
"answers": [
{
"text": "答案1",
"answer_start": 12
}
]
},
{
"question": "问题2",
"answers": [
{
"text": "答案2",
"answer_start": 30
}
]
}
]
}
]
}
]
}
在上述示例中,你可以看到数据以JSON格式表示。每个样本包含一个段落(paragraphs),其中包含一个上下文文本(context)和相关的问题(qas)。每个问题下又包含一个或多个答案(answers),每个答案有答案文本(text)和答案在上下文中的起始位置(answer_start)。
你可以根据自己的数据集将其转换为上述的JSON格式,并根据需要创建多个段落和问题。请确保数据格式正确,并与模型的输入相匹配。
需要注意的是,训练数据的准备可能因不同的训练框架和库而有所差异。在使用具体的深度学习框架进行微调训练时,你可能需要参考相应的框架文档或示例代码来了解如何准备和加载数据。
另外,微调训练需要一定的训练代码和步骤。你可以参考StructBERT模型的文档、官方示例或相关的开源项目来了解更多关于微调训练的细节和实现方法。
如果您想要使用StructBERT模型进行自己本地数据的训练,您需要准备以下格式的数据:
问题和答案对:每个样本包含一个问题和一个对应的答案。您可以将问题和答案分别存储在两个文件中,每行一个样本,例如:
# 问题文件
你好吗?
你叫什么名字?
今天天气怎么样?
# 答案文件
我很好,谢谢。
我叫StructBERT。
今天天气晴朗,适合出门。
标注的实体和关系:如果您想要训练StructBERT模型来识别实体和关系,您需要准备标注好的实体和关系数据。您可以将实体和关系分别存储在两个文件中,每行一个样本,例如:
# 实体文件
{"text": "苹果公司", "start": 0, "end": 4, "type": "company"}
{"text": "蒂姆·库克", "start": 5, "end": 11, "type": "person"}
# 关系文件
{"head": 0, "tail": 1, "relation": "CEO"}
在准备好数据之后,您可以使用Python代码来加载数据并进行训练。具体的代码实现和使用方法可以参考StructBERT官方文档中的示例代码。
如果您想使用 StructBERT FAQ问答-中文-通用领域-base 模型针对自己的数据集进行训练,需要将您的数据集以固定格式构造成文本序列对的形式。通常来说,每个文本序列对都由以下两个部分组成:
问题(Question):是指用户提出的问题或要求,通常是一个短语或一个问题句子。
回答(Answer):是指与问题相对应的答案或响应,通常是一个短语、一个完整句子或一个多句子段落。
在准备数据集时,您需要至少有一个包含问题和回答的数据文件。每个文件都应该是一个文本文件,其中每一行都包含一个单独的问题和答案序列对,且问题和答案使用制表符(\t)分隔。例如:
问题1 回答1
问题2 回答2
问题3 回答3
如果您的数据集有多个文件,您需要为每个文件构造一个训练样本文件。在每个训练样本文件中,问题和答案序列对应该以类似上述格式的形式出现。您可以使用 Python 或其他编程语言来处理文本文件,并将其转换为适合模型训练的数据格式,例如 JSON、tsv 或 CSV 等。例如,下面是将上述数据格式转换为 JSON 格式的代码片段:
import json
# 读取数据文件并转换为序列对列表
with open('data_file.txt', 'r', encoding='utf-8') as f:
samples = [line.strip().split('\t') for line in f]
# 将数据格式转换为 JSON 格式
json_data = [{'question': sample[0], 'answer': sample[1]} for sample in samples]
# 将 JSON 数据写入 JSON 文件
with open('data_file.json', 'w', encoding='utf-8') as f:
f.write(json.dumps(json_data, ensure_ascii=False))
生成的 JSON 格式数据文件可以直接传递给模型进行训练。请注意,这只是一个例子,具体文件格式和处理方式取决于您的数据集和代码实现。
StructBERT FAQ问答-中文-通用领域-base模型是一个基于StructBERT模型进行训练的中文问答模型,适用于通用领域的问答任务。要加载自己本地数据进行训练,您需要提供以下格式的数据:
训练数据应以JSON格式存储,每个样本对应一个JSON对象。每个JSON对象包含以下字段:
"query": 表示问题或查询的文本。
"answers": 表示问题的答案或回答的列表。每个回答都具有以下字段:
以下是一个示例训练数据的JSON格式:
json
[
{
"query": "什么是人工智能?",
"answers": [
{
"text": "人工智能(Artificial Intelligence,简称AI)指的是使机器像人类一样具备智能的能力。",
"type": "user"
}
]
},
{
"query": "结构化预训练有什么优势?",
"answers": [
{
"text": "结构化预训练能够捕捉到语言中的结构信息,并在特定任务上取得更好的效果。",
"type": "generated"
}
]
},
...
]
可以根据实际情况准备大量的问答数据,并按照上述格式存储为JSON文件。然后,使用该训练数据对StructBERT模型进行训练。
如果您想要使用 StructBERT FAQ问答-中文-通用领域-base 模型在自己的本地数据上进行微调,您需要将数据转化为模型要求的格式,即JSON格式。
具体地,每个训练样本应包含以下字段:
qid:问题ID,一个字符串或数字类型的唯一标识符。 question:问题文本,一个字符串类型的字段,表示待回答的问题。 paragraphs:段落列表,一个列表类型的字段,包含每个段落的文本和是否答案的信息。 text:段落文本,一个字符串类型的字段,表示段落的文本内容。 is_selected:是否答案,一个布尔类型的字段,表示该段落是否为正确答案。 示例代码如下:
[{
"qid": "001",
"question": "什么是人工智能?",
"paragraphs": [
{
"text": "人工智能(Artificial Intelligence)简称AI,是由人工制造出来的智能,是指通过计算机等科技手段实现的智能。",
"is_selected": false
},
{
"text": "人工智能(AI)是一种模拟人类智能的技术,通俗地说,就是让计算机具有像人类一样的思维和行为的能力。",
"is_selected": true
}
]
}]
在训练时,您需要指定模型的输入数据格式,并使用适当的数据加载器将数据加载至模型中。一般来说,您可以使用PyTorch中的Dataset和DataLoader等工具来加载数据并进行训练。 另外,为了保证训练效果和泛化能力,建议您在进行数据训练时,采用训练集、验证集和测试集的方式进行,并对模型进行定期评估和调整。 总之,如果您想要在自己本地数据上进行 StructBERT FAQ问答-中文-通用领域-base 模型的微调,需要将数据转化为JSON格式,并使用PyTorch等工具将数据加载至模型中进行训练
StructBERT FAQ 问答 - 中文 - 通用领域-base 这个模型使用的是预训练的 BERT 模型,可以通过 API 接口进行调用,支持多种数据格式,包括 CSV、JSON、HDFS 等。
如果您想使用本地数据进行训练,可以使用 StructBERT FAQ 问答 - 中文 - 通用领域-base 模型的 API 接口,将本地数据文件作为输入,并指定数据文件的路径。在调用 API 接口时,需要指定数据文件的格式 (如 CSV、JSON 等),以及输入和输出的格式。
在使用 StructBERT FAQ 问答 - 中文 - 通用领域-base 模型进行本地数据训练时,建议您使用高质量的数据集,并尽可能减少噪声和错误数据的影响。同时,您还需要注意数据的格式和大小,以确保模型能够高效地训练。
StructBERT是一个基于BERT的模型,用于自然语言处理任务,包括问答系统。如果您想要使用StructBERT模型来训练自己的数据,您需要将数据转换为适当的格式。以下是一些可能有用的步骤1. 准备数据:您需要准备一个包含问题和答案的数据集。每个问题和答案应该是一个文本字符串。您可以使用任何格式来存储数据,例如CSV、JSON或TXT。
数据预处理:在将数据传递给StructBERT模型之前,您需要对其进行预处理。这包括将文本转换为数字表示形式,例如使用词嵌入或字符嵌入。您还需要将数据划分为训练集、验证集和测试集。
加载数据:在训练StructBERT模型之前,您需要将数据加载到模型中。您可以使用Python中的数据加载器来完成这个任务。例如,您可以使用PyTorch的DataLoader类来加载数据。
训练模型:一旦您的数据已经准备好并加载到模型中,您可以开始训练StructBERT模型。您可以使用Python中的深度学习框架,例如PyTorch或TensorFlow,来训练模型。
需要注意的是,StructBERT模型是一个预训练模型,需要大量的数据和计算资源来进行训练。如果您没有足够的数据和计算资源,您可以考虑使用已经训练好的模型进行微调,以适应您的特定任务。
StructBERT FAQ问答-中文-通用领域-base模型是一个预训练模型,如果你想要使用该模型来进行问答任务,需要先对自己本地的数据进行微调或者训练。微调或训练的数据应该是符合SQuAD格式的数据集,即包含了问题、文本和答案的数据集。
具体来说,SQuAD格式的数据集应该是一个JSON文件,包含了以下字段:
{
"data": [
{
"title": "文章标题",
"paragraphs": [
{
"context": "文章段落",
"qas": [
{
"question": "问题",
"id": "问题ID",
"answers": [
{
"text": "答案",
"answer_start": "答案在文章段落中的起始位置"
}
]
}
]
}
]
},
...
]
}
其中,"data"字段表示整个数据集,包含了多个"paragraphs"段落,每个段落都包含了"context"文章段落和"qas"问题答案对。每个问题答案对包含了"question"问题、"id"问题ID和"answers"答案,答案包括"answer_start"答案在文章段落中的起始位置和"answer_text"答案文本。
如果你已经有符合SQuAD格式的数据集,可以使用相应的工具将数据集转换成BERT模型所需的输入格式,然后使用该数据集对StructBERT模型进行微调或训练。
StructBERT是一种基于BERT(Bidirectional Encoder Representations from Transformers)的自然语言处理模型,它通过引入语言结构信息(如句子顺序和单词顺序)来改进BERT。这种模型通常用于各种NLP任务,如文本分类、命名实体识别(NER)、问答(QA)等。
一般来说,训练StructBERT或者BERT这类模型,数据集的格式通常是一行一个文本样本的纯文本文件,也就是.txt格式。这个文本文件中,每一行都应该是一个独立的文本样本,也就是一个句子或者一段文本。例如:
我喜欢吃苹果。
苹果是一种水果。
天气真好。
另外,如果你正在进行特定的任务,如文本分类或命名实体识别,那么你的数据可能需要更复杂的标注。例如,对于文本分类任务,你可能需要一个.csv或.tsv文件,其中每一行包含一个文本样本和其对应的类别标签。
需要注意的是,每个NLP任务可能都有其特定的数据格式要求。具体的格式要求,你需要参考你正在使用的StructBERT实现的具体文档。
不过我建议您查阅StructBERT的官方文档或相关的GitHub仓库,那里通常会有关于如何准备和格式化数据的具体指导
如果您想要使用 StructBERT FAQ问答-中文-通用领域-base 模型,加载自己本地数据进行训练,您需要准备相应的训练数据,并将其转换成模型所需的格式。
StructBERT 模型在训练时需要输入两个文本序列,分别为问题和回答。在进行训练之前,您需要将这些文本序列转换成模型所需的输入格式,即 token ID 和 segment ID。
以下是一些常见的步骤和建议:
准备数据集:您首先需要准备一个包含问题和回答的数据集。每个样本应该由一个问题和一个正确的答案组成,您可以将它们分别存储在两个不同的文件中,或者使用一个文件来表示。
分词和编码:对于每个文本序列,您需要先进行中文分词,然后将分词结果转换成对应的 token ID(例如使用 BERT tokenizer)。同时,还需要为每个文本序列生成相应的 segment ID,以区分问题序列和回答序列。
组装数据集:对于每个样本,您需要将它们的问题和回答分别转换成 token ID 和 segment ID,并将它们组装成模型所需的输入格式。
# 示例代码
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
def convert_example_to_feature(question, answer, max_seq_length):
question_tokens = tokenizer.tokenize(question)
answer_tokens = tokenizer.tokenize(answer)
# Truncate to avoid exceeding the maximum sequence length
while len(question_tokens) + len(answer_tokens) > max_seq_length - 3:
if len(question_tokens) > len(answer_tokens):
question_tokens.pop()
else:
answer_tokens.pop()
tokens = ["[CLS]"] + question_tokens + ["[SEP]"] + answer_tokens + ["[SEP]"]
segment_ids = [0] * (len(question_tokens) + 2) + [1] * (len(answer_tokens) + 1)
input_ids = tokenizer.convert_tokens_to_ids(tokens)
# Pad up to the maximum sequence length
padding_length = max_seq_length - len(input_ids)
input_ids += [0] * padding_length
segment_ids += [0] * padding_length
return {"input_ids": input_ids, "segment_ids": segment_ids}
存储数据集:最后,您需要将转换后的数据保存到相应的文件中,以便在模型训练时加载使用。
# 示例代码
examples = [
{"question": "问题1", "answer": "答案1"},
{"question": "问题2", "answer": "答案2"},
# ...
]
features = []
for example in examples:
feature = convert_example_to_feature(example["question"], example["answer"], max_seq_length=256)
features.append(feature)
with open("train_data.json", "w") as f:
json.dump(features, f)
在实际使用时,您需要根据自己的需求和数据格式进行相应的调整和优化。如果您遇到任何问题或需要进一步了解相关技术和方法,请及时向 StructBERT 官方客服或技术支持团队咨询。
StructBERT FAQ问答-中文-通用领域-base模型是基于Transformers模型库中的BERT模型进行Fine-tuning得到的。如果您希望使用自己本地的数据进行Fine-tuning,需要准备以下格式的数据集:
数据集应该是一个包含了许多问题和答案对的表格,每一行包含一组qa对,第一列是问题,第二列是答案,中间用\t隔开。例如: 我该怎么做才能失眠? 多喝水,保持心情稳定等可以帮助您改善睡眠质量。 您会什么编程语言? 我熟练使用Python、Java和C++等多种编程语言。 上述表格中的数据需要保存成txt文件格式,并且保证列与列之间用\t隔开,每条qa对占一行,如果有多条qa对,就将它们一行一行放入,并且证保证每行qa对之间不要有空行。
将以上数据集保存到本地,并使用类似open()函数的方法进行读取即可供模型训练使用。
请注意,在使用自己本地数据进行Fine-tuning前,您需要了解如何使用Transformers库加载并Fine-tuning BERT模型。另外,还需要使用适当的GPU资源来提高训练速度。
StructBERT FAQ问答-中文-通用领域-base这个模型需要使用特定的格式进行训练,这个格式包括了问题和答案对。具体的格式要求如下:
数据集需要按照问答对的形式组织,每个问答对包含问题和对应的答案。 每个问答对需要保存在一个单独的文本文件中,文件名需要按照“问题ID_问题内容.txt”的格式命名,其中问题ID可以是任意字符串,用于标识不同的问答对。 每个文本文件中需要包含两个部分,第一行为问题内容,第二行开始为对应的答案。 多个问答对可以保存在同一个文件夹中,文件夹名可以任意命名。 数据集需要按照一定的命名规范进行组织,具体的命名规范可以参考StructBERT的官方文档。 需要注意的是,StructBERT FAQ问答-中文-通用领域-base这个模型是基于StructBERT框架构建的,因此在加载和训练模型时需要使用StructBERT框架提供的API。
StructBERT FAQ问答-中文-通用领域-base模型是基于预训练模型StructBERT的一个FAQ问答模型,可以用于中文的常见问题答案生成。如果您想要使用自己本地的数据对这个模型进行微调,需要按照特定的格式处理数据。 StructBERT FAQ问答-中文-通用领域-base 模型的微调数据应该具备以下格式: 每条数据应该包含以下两个字段:
"question": 问题文本. "answer": 问题的对应答案.
数据集要求以json文件的形式保存,并遵循以下格式:
[
{
"question": "问题 1",
"answer": "答案 1"
},
{
"question": "问题 2",
"answer": "答案 2"
},
...
{
"question": "问题 n",
"answer": "答案 n"
}
]
其中,“问题”和“答案”应该使用字符串形式,并且格式要与源数据的格式保持一致。另外,为了保证微调的效果,您可能需要仔细选择微调数据的规模和质量,并进行数据清洗和预处理等操作。 微调数据的格式处理完成后,您可以使用类似于以下代码的方式将其加载到模型中进行微调训练:
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("StructBERT/StructBERT_FAQ_Chinese_base")
model = AutoModelForSequenceClassification.from_pretrained("StructBERT/StructBERT_FAQ_Chinese_base")
# 加载微调数据
train_dataset = torch.load("train_dataset.pth")
#微调
model.train_model(train_dataset)
具体的路径以及参数可根据您的数据的存储方式进行适当调整。希望可以帮助到您。
要加载自己本地数据进行训练,需要将数据格式转换为模型支持的格式。对于StructBERT FAQ问答-中文-通用领域-base模型,其输入格式为:
{
"input_ids": [[1, 2, 3, ..., 0, 0], [1, 2, 3, ..., 0, 0], ..., [1, 2, 3, ..., 0, 0]],
"token_type_ids": [[0, 0, 0, ..., 0, 0], [0, 0, 0, ..., 0, 0], ..., [0, 0, 0, ..., 0, 0]],
"attention_mask": [[1, 1, 1, ..., 0, 0], [1, 1, 1, ..., 0, 0], ..., [1, 1, 1, ..., 0, 0]]
}
其中,input_ids表示输入的token序列,token_type_ids表示token所属的句子编号(在单句输入时全为0),attention_mask表示哪些位置需要注意,哪些位置是填充的(0表示填充,1表示需要注意)。在使用时,需要将数据转换为这种格式,并按照batch进行划分,送入模型进行训练。
如果您想使用 StructBERT FAQ问答-中文-通用领域-base 模型,加载自己本地数据进行训练,您需要将您的数据转换成适当的格式,并处理成相应的输入和输出格式。下面是一些可能有用的格式和处理步骤:
数据格式 StructBERT FAQ问答-中文-通用领域-base 模型是一个基于自然语言处理的问答模型,它需要输入一个问题和一个文本段落,以预测文本段落中与问题相关的答案。因此,您需要将您的数据转换成包含问题和文本段落的格式。具体来说,您可以将每个问题和文本段落组合成一个样本,并将其保存为一个 CSV 或 JSON 格式的文件。
例如,您可以创建一个 CSV 文件,其中每一行包含一个问题和一个文本段落,以及相应的标签(即答案)。文件格式如下:
Copy question,context,label "什么是深度学习","深度学习是一种机器学习技术","深度学习" "人工智能有哪些应用场景?","人工智能可以用于图像识别、语音识别、自然语言处理等领域。","图像识别" 数据处理 在将数据输入到模型中进行训练之前,您需要对数据进行一些处理和转换,以适应模型的输入和输出格式。具体来说,您需要将每个样本转换成模型需要的输入和输出格式。
对于 StructBERT FAQ问答-中文-通用领域-base 模型,您需要将每个样本转换成包含以下字段的格式:
input_ids: 包含问题和文本段落的 token ID 序列。 token_type_ids: 标识问题和文本段落的 token 类型序列。 attention_mask: 标识有效 token 的注意力掩码序列。 start_positions: 答案在文本段落中的起始位置。 end_positions: 答案在文本段落中的结束位置。 您可以使用一些工具和库来进行数据处理和转换,例如 Transformers 库、Hugging Face Datasets 库等。具体的数据处理和转换代码可以参考这些库的文档和示例。
这个模型使用StructBERT网络模型进行训练,其格式要求可能因使用的训练数据集和编码格式而有所不同。如果你已经有自己的数据集并准备使用该模型进行训练,建议先阅读模型的文档或相关资料,了解数据集和格式的要求。在训练模型时,也要确保数据集和模型保持一致,并使用模型要求的数据集格式进行加载。


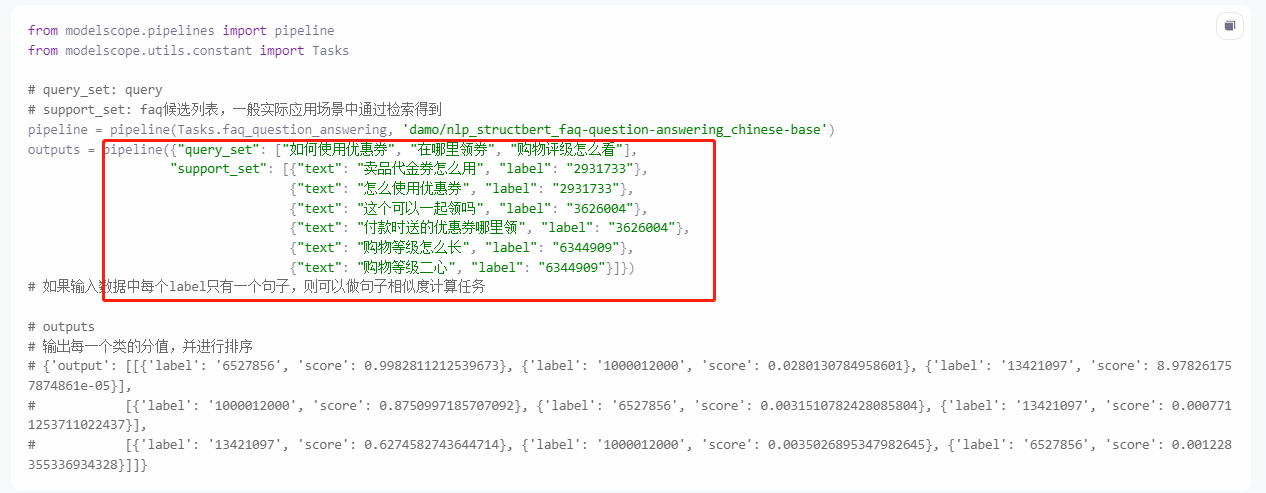 或者你也可以到模型体验页面:
或者你也可以到模型体验页面: