
快速理解文本识别模型CRNN
-
前言 文本识别就是将目标区域中包含的文本进行识别提取的过程。对于文本识别,CRNN+CTC的方法取得了很好的结果,它是白翔老师团队2015年提出的方法,尽管已经过去了很久,但由于其准确率高,现在依然被广泛地采用。本文将对其网络结构及原理进行介绍。
-
网络结构 CRNN的网络结构模型包括三个部分,分别称作卷积层、循环层以及转录层。
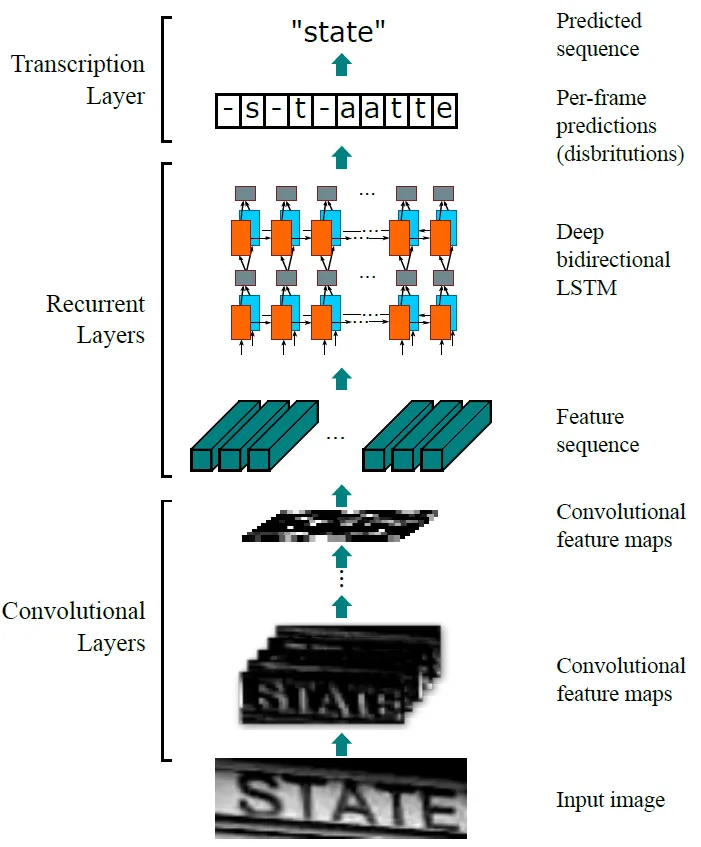
卷积层由CNN构成,它的作用是从输入的图像中提取特征。提取的特征图将会输入到接下来的循环层中,循环层由RNN构成,它将输出对特征序列每一帧的预测。最后转录层将得到的预测概率分布转换成标记序列,得到最终的识别结果,它实际上就是模型中的损失函数。通过最小化损失函数,训练由CNN和RNN组成的网络。
2.1 卷积层 CRNN模型中的卷积层由一系列的卷积层、池化层、BN层构造而成。就像其他的CNN模型一样,它将输入的图片转化为具有特征信息的特征图,作为后面循环层的输入。当然,为了使提取的特征图尺寸相同,输入的图像事先要缩放到固定的大小。
由于卷积神经网络中卷积层和最大池化层的存在,使其具有平移不变性的特点。卷积神经网络中的感受野指的是经过卷积层输出的特征图中每个像素对应的原输入图像区域的大小,它与特征图上的像素从左到右,从上到下是一一对应的
虽然卷积神经网络以其强大的优势被广泛应用到视觉领域中,但是由于其往往需要将输入图像缩放到统一尺寸,所以对于那些尺寸变化较大的数据比如文本信息便不能起到很好的效果。为此,在这里模型在卷积层的后面添加了由RNN组成的循环层,用来更好地处理序列信息。
CRNN的卷积层具体的网络结构,它是在VGG网络的基础上改造而成。卷积层对于VGG主要对两个地方进行了改动:
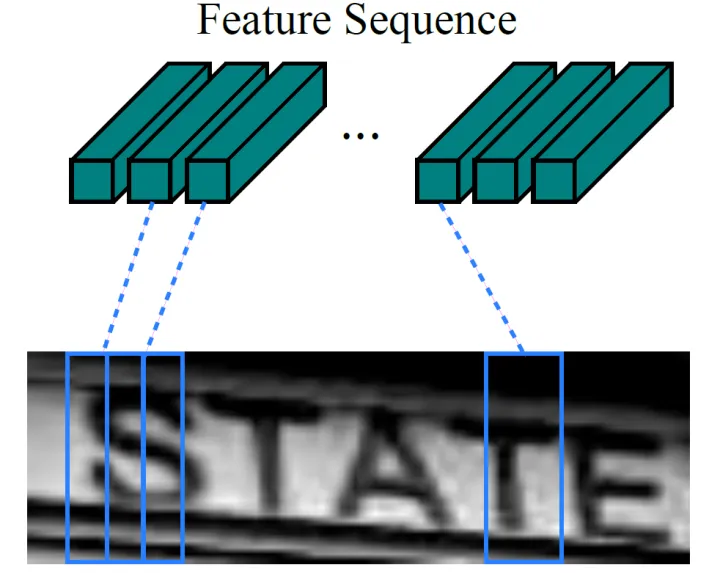
将第2层和第3层的MaxPooling的卷积核的大小从 改成了 。 这是为了最后提取的特征图可以输入到循环层RNN中。从CRNN的结构图可以看出,当图片输入CRNN之前,图片的大小会统一放缩至 ,即长宽比保持不变,高度固定为32。假如有一张图片的大小为 ,里面包含10个字符,那么经过CRNN的卷积层后,将得到尺寸为 的特征图。忽略掉维度1,将该特征图转化为大小为 的输出向量 。该向量的长度为25,每一个分量 的维度等于通道数,对应原输入图片的一块矩形区域,可以表示对应该区域的提取特征。处理后的向量 可作为循环层的输入进行进一步的计算。
第5层和第6层的卷积层后面都添加了一个BN(Batch Normalization)层。因为BN层可以对输入数据进行归一化,加速网络的收敛速度。 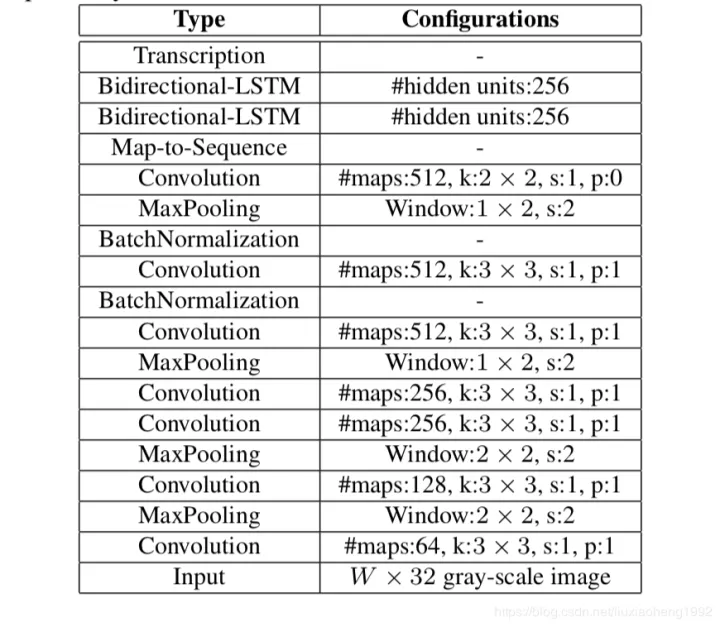
图3 卷积层网络配置
2.2 循环层 在卷积层的后面,是由双向递归神经网络(RNN)构成的循环层,它将卷积层得到的特征序列 中的每一个分量 都产生一个标签分布 。之所以要采用循环层,主要考虑了三点因素。第一,卷积层不能很好地提取序列的上下文信息,而RNN恰好能解决这个问题。第二,经过循环层得到的误差在反向传播时可以传回卷积层,所以循环层和卷积层可以共同训练。第三,也是最重要的一点就是,RNN可以处理长短不一的序列,而这是卷积层所不具备的。
普通的RNN有很大的局限性,比如如果序列过长会存在梯度消失或梯度爆炸的问题,这一方面限制了能捕获的上下文信息,同时也加大了训练难度。所以这里使用LSTM来代替传统的RNN,他是RNN的一种变体,通过门机制将短时记忆和长时记忆结合到一次,在一定程度上解决了这问题。由于序列中的某个变量既和之前的信息有关,也和它后面的信息有关,所以使用双向的LSTM能够更加充分地利用上下文信息,同时测试表明增加BiLSTM的层数可以有效的提升识别的准确率,这里使用了两层的BiLSTM,在实际应用当中可以根据自身的情况适当进行改变。
卷积层得到的特征序列经过循环层两个BiLSTM的处理后,进一步结合了上下文的语义信息,可以对图片中的文本信息进行更好地识别。这里需要说明的是,由于卷积层的输入的维度和LSTM的输入并不完全相同,所以还需要构造线性层进行维度的转换,作为卷积层和循环层的过渡,使其满足循环层的输入要求。
2.3 转录层 转录层的作用是将前面通过CNN层和RNN层得到的预测序列转换成标记序列,得到最终的识别结果。简单来说,就是选取预测序列中每个分量中概率最大的索引对应的符号作为识别结果,最终组成序列作为最终的识别序列。本文采用CTC中定义的条件概率来处理序列的转换问题。
实际在应用时,它对应的就是CRNN模型的损失函数。目前新版的pytorch已经集成了ctc算法torch.nn.CTCLoss,不过之前的版本存在bug,不知道最新版有没有修复;另一个常用的实现是百度开源的warp-ctc, 这个应该是没问题的。
- 总结 以上就是CRNN的全部内容,可以看到整体的模型结构还是比较简洁的,但是实际的效果确实很不错,这也是其提出了这么长时间依然被广泛使用的原因吧。另一种文本识别算法是基于CNN+Attention的方法,感兴趣的同学可以自己去了解。
