
阿里云E-MapReducePython 编写 Flink UDAF 如何注册到SQL上下文呢?
阿里云E-MapReducePython 编写 Flink UDAF ,UDF是已经可以跑通的,如何通过sqlclient注册到SQL上下文呢? 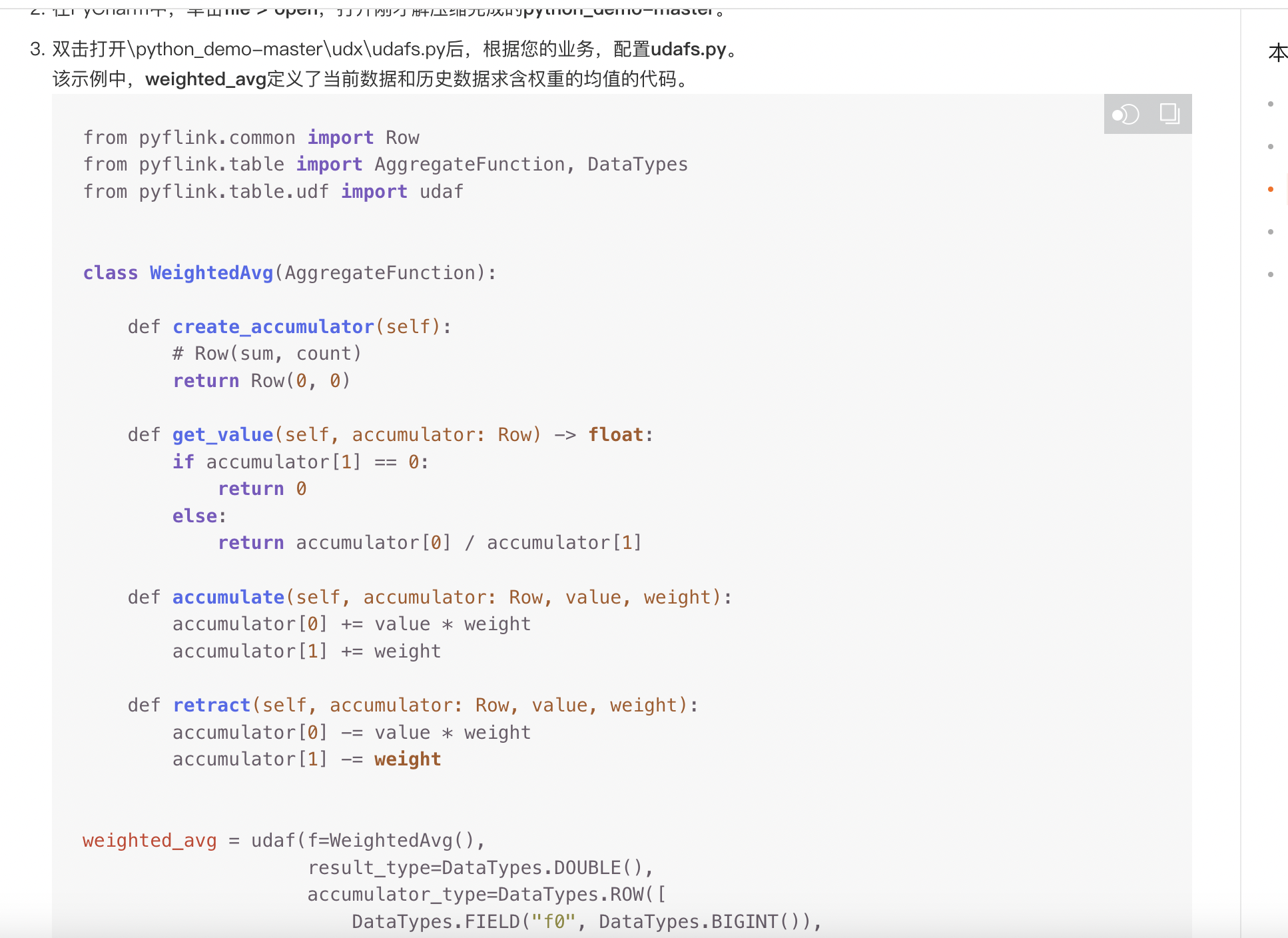
-

您可以通过以下方法注册UDAF到SQL上下文中:
首先在Flink程序中通过registerFunction方法注册UDAF。
from pyflink.table.udf import udaf
定义UDAF函数
@udaf(input_types=[DataTypes.BIGINT(), DataTypes.BIGINT()], result_type=DataTypes.BIGINT()) def my_udaf(a, b): return a + b
在SQL上下文中注册UDAF函数
t_env.register_function("my_udaf", my_udaf) 然后在SQL语句中使用UDAF函数。
使用UDAF函数
t_env.sql_query("SELECT my_udaf(col1, col2) FROM t1") 希望这些信息能帮助您解决问题。
2022-12-31 11:19:31赞同 展开评论 打赏

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
阿里云EMR是云原生开源大数据平台,为客户提供简单易集成的Hadoop、Hive、Spark、Flink、Presto、ClickHouse、StarRocks、Delta、Hudi等开源大数据计算和存储引擎,计算资源可以根据业务的需要调整。EMR可以部署在阿里云公有云的ECS和ACK平台。
热门讨论
热门文章


相关电子书
更多

