
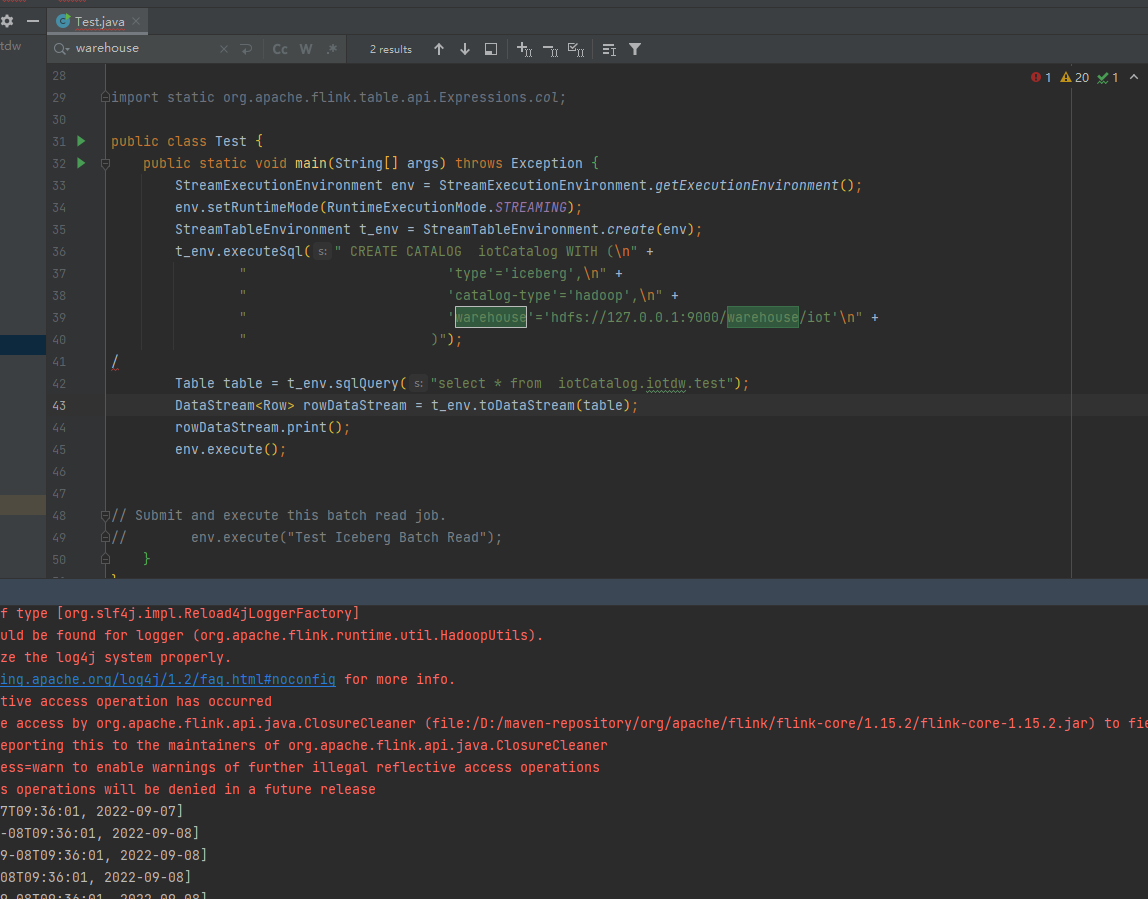
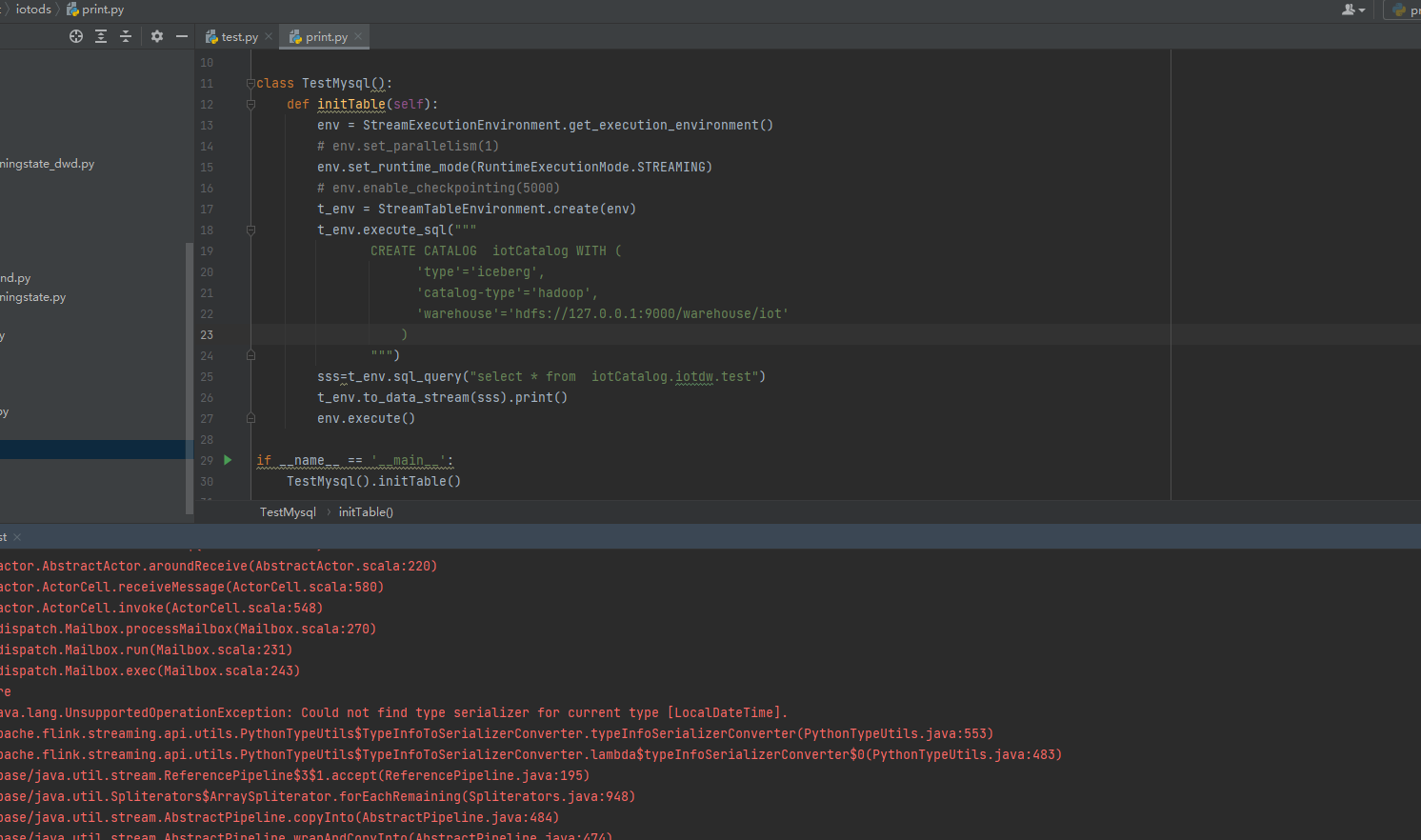
pyflink1.15 同样的代码报错,在java里面不报错能正常运行,知道是什么原因吗
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
公众号:网络技术联盟站,InfoQ签约作者,阿里云社区签约作者,华为云 云享专家,BOSS直聘 创作王者,腾讯课堂创作领航员,博客+论坛:https://www.wljslmz.cn,工程师导航:https://www.wljslmz.com
在阿里云实时计算 Flink中,PyFlink 1.15 与 Java Flink 可能存在一些细微的语法差异或 API 的不同导致的报错。请注意代码中的类型转换等问题。常见的可能导致报错的问题包括:
- 类型转换问题:当使用 PyFlink 编写代码时,需要特别注意类型转换,例如从字符串转换为数字或日期。在某些情况下,这些类型转换可能与 Java Flink 内部的逻辑不兼容,导致 PyFlink 代码无法正常运行。
- 接口的不同:Java Flink 中的某些接口在 PyFlink 中可能会有所不同,需要根据适当的方式进行更改。例如,在 Java Flink 中,您可能需要编写无返回值的函数,但在 PyFlink 中,您可能需要使用 Python None 返回值。
- Python 版本问题:PyFlink 需要使用特定版本的 Python 运行库。如果运行库版本不兼容,可能会导致代码无法正常运行。
2023-05-05 20:41:35赞同 展开评论 -
在 PyFlink 1.15 中,与以前版本相比,对于 Flink Java API 的 Python 封装程度更高,因此在 PyFlink 1.15 中,可能会更容易发现一些 Flink Java API 中的问题。建议您先检查您的代码是否符合 Flink Java API 的语法和要求,并且检查您使用的 PyFlink 版本是否与您所依赖的 Flink 版本兼容。 还可以查看 PyFlink 的错误日志,详细了解错误的起因和可能的解决方案。
2023-05-05 18:18:12赞同 展开评论 -
云端行者觅知音, 技术前沿我独行。 前言探索无边界, 阿里风光引我情。
如果您在使用Python编写Flink程序时遇到了错误,而同样的代码在Java中没有问题,可能是因为Python的一些特性和限制导致的。例如,Python是一种动态类型语言,而Java是一种静态类型语言,这意味着在Python中可能会出现类型错误,而在Java中这些错误会在编译时被捕获。 另外,Flink的Python API相对于Java API来说还比较新,可能存在一些不稳定性和兼容性问题。因此,如果您需要在Flink中编写稳定和可靠的程序,建议使用Java编写。
2023-05-04 18:36:46赞同 展开评论 -
从事java行业9年至今,热爱技术,热爱以博文记录日常工作,csdn博主,座右铭是:让技术不再枯燥,让每一位技术人爱上技术
根据错误描述,相同的处理逻辑在java代码下可以运行但是在python代码下运行报错,建议排查一下python的版本是否符合当前使用的Flink版本对应的python版本,另外检查一下python依赖包的导入是否有问题。
2023-05-04 17:59:12赞同 展开评论 -
看错误可能是由于flink版本不兼容或者依赖包版本不匹配导致的。建议您检查一下项目中flink和protobuf的版本是否匹配,同时检查数据类型的定义是否正确。
通常情况下,这个错误会在flink序列化Row类型数据时出现,可能是由于flink本身的版本升级导致序列化机制发生了变化,但是项目中的protobuf依赖包并没有进行相应的更新,导致序列化出现错误。
解决这个问题的方法是,通过更新项目中的依赖包版本来解决。一般情况下,更新flink和protobuf的版本到最新的版本可以解决这个问题。如果还是无法解决,可以考虑升级或者降级flink和protobuf以达到版本兼容的目的。
2023-05-03 08:05:09赞同 展开评论 -
根据这一行 "Invalid protocol buffer descriptor for type org.apache.flink.types.Row" 这个错误提示通常出现在使用 Apache Flink 进行流处理时,涉及到 protobuf 序列化的过程中。可能的原因有:
-
在 Flink 应用程序中使用了不兼容的 protobuf 版本。确保 Flink 应用程序和您使用的 protobuf 版本兼容。
-
Flink 应用程序中定义的 Row 类型与 protobuf 序列化器所期望的 protobuf 描述符不匹配。请确保您定义的 Row 类型与 protobuf 序列化器所期望的相匹配。
-
Flink 应用程序使用了不兼容的序列化器。请确保您使用的序列化器与 Flink 应用程序兼容。
2023-04-28 20:03:28赞同 展开评论 -
-
值得去的地方都没有捷径
看到你的错误提示 "Invalid protocol buffer descriptor for type org.apache.flink.types.Row",不太可能和PyFlink 版本有关系。
根据错误提示来看,可能是序列化相关的问题。也就是说,当将Row数据序列化为Protocol Buffer时发生了错误。这个错误可能会导致PyFlink作业无法执行。
这个错误可能是由编译时依赖项不一致导致的。一种可能是PyFlink 1.15 依赖的Protocol Buffer版本与你的代码依赖的版本不一致,导致类加载时出现问题。
建议检查你的代码中使用的所有依赖项,并确保所有依赖项都是兼容的。如果错误仍然存在,建议尝试更新PyFlink和相应的依赖项,以查看是否可以解决该问题。
2023-04-26 14:38:48赞同 展开评论 -
天下风云出我辈,一入江湖岁月催,皇图霸业谈笑中,不胜人生一场醉。
由于 PyFlink 是基于 Java 实现的,因此在理论上可以在 Java 环境下运行的代码在 PyFlink 中也应该可以正常运行。但实际情况可能存在差异,可能是因为 PyFlink 与 Java API 的实现方式或语法略有不同,或者 PyFlink 的一些限制或缺陷导致代码无法正常工作。
如果您的代码在 Java API 中能够正常工作,但在 PyFlink 中出现了问题,我建议您先检查一下 PyFlink 的文档、示例或社区上相关的讨论,看是否有类似的问题或解决方案。如果没有,或者您确信这是 PyFlink 的问题,可以考虑提交一个 PyFlink Issue,详细说明问题,包括完整的错误信息和堆栈跟踪,以便开发人员更好地理解和排除问题。
另外,有时可能是因为您的 Python 环境或依赖项版本不兼容或存在缺陷,导致代码无法正常工作。您可以尝试更新或升级相关依赖项,或者使用其他 Python 环境或版本进行测试。
2023-04-26 11:00:10赞同 展开评论 -
十分耕耘,一定会有一分收获!
楼主你好,根据你的描述,是因为序列化问题引起的,你可以排查一下序列化时候的配置设置是否有问题,然后在排查一下flink sql对应的语法使用是否正确。
2023-04-24 23:11:23赞同 展开评论 -
在 PyFlink 1.15 中,与 Java API 相比,有一些语法和 API 的差异。如果您的代码在 Java API 中可以正常运行,但在 PyFlink 中报错,可能是以下原因之一:
-
代码错误:请检查代码中的语法错误、拼写错误、缩进等问题,确保代码正确无误。
-
Python 版本问题:请确保您使用的是 Python 3.x 版本,而非 Python 2.x 版本。
-
PyFlink 版本问题:请确保您使用的是与 Flink 版本对应的 PyFlink 版本,例如,如果您使用的是 Flink 1.15.0 版本,则应该使用 PyFlink 1.15.0 版本。
-
API 差异:在 PyFlink 中,与 Java API 相比,存在一些语法和 API 的差异,例如,Python 中的字符串需要使用双引号,而不是单引号。因此,您需要根据 PyFlink 的 API 文档来编写代码。
2023-04-24 18:28:14赞同 展开评论 -
-
全栈JAVA领域创作者
根据错误提示,可能是因为 Invalid protocol buffer descriptor for type org.apache.flink.types.Row。这个错误通常是因为序列化的问题导致的,可能是 Python 的序列化和 Java 的序列化方式不一致所导致的。
建议检查一下代码中的序列化相关配置是否正确。同时,可以尝试将代码的序列化方式改为 Avro 或 JSON,看看是否能够解决问题。
2023-04-23 23:29:16赞同 展开评论 -
热爱开发
如果您的Python代码在使用PyFlink 1.15时报错,而Java代码在相同环境下没有问题,可能是因为不同语言的代码实现不同,或者是因为不同语言的调用方式不同而导致的。建议检查Python代码和Java代码中的参数、数据类型、函数库以及语法等是否一致,并确保正确地处理异常和错误。
此外,可以尝试从PyFlink的日志或错误信息中获取更多详细信息,例如堆栈跟踪和错误消息,以便更好地了解问题所在。如果问题依然存在,请提供相关代码、日志和错误信息等更详细的信息,以便我们更好地帮助您分析和解决问题。
2023-04-23 17:42:08赞同 展开评论 -
您在 PyFlink 1.15 中运行一个 Flink SQL 查询时出现了错误。这个错误提示是因为 Flink SQL 中的字符列需要用单引号或双引号括起来,而您在查询中使用的是反引号,这不符合 Flink SQL 的语法要求。 为了解决这个问题,您可以将查询语句中的反引号改为单引号或双引号,例如:
t_env.execute_sql("CREATE TABLE users (id INT, name STRING, age INT) WITH ('connector' = 'filesystem', 'path' = '/path/to/users')") t_env.execute_sql("CREATE TABLE orders (id INT, user_id INT, total_amount DOUBLE) WITH ('connector' = 'filesystem', 'path' = '/path/to/orders')") t_env.execute_sql("SELECT u.name, o.total_amount FROM users u JOIN orders o ON u.id = o.user_id WHERE u.age > 18") 同时,如果您使用 Flink 1.15 版本的 Java API 进行相同的操作,那么您不会出现这个错误,因为 Java API 中的 SQL 解析器会自动将反引号转换为双引号。
2023-04-23 17:09:15赞同 展开评论


实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
