
目录
基于2022年6月最新上证指数数据集结合Pytorch框架利用GRU算法预测最新股票上证指数实现回归预测
# 2.4、构造时序性矩阵数据集:基于y重新设计训练集——符合时序性
# 3.4、基于GRU模型预测:基于训练好的GRU模型,预测test数据集
相关文章
DL之GRU(Pytorch框架):基于2022年6月最新上证指数数据集利用GRU算法预测最新股票上证指数实现回归预测
DL之GRU(Pytorch框架):基于2022年6月最新上证指数数据集利用GRU算法预测最新股票上证指数实现回归预测实现
基于2022年6月最新上证指数数据集结合Pytorch框架利用GRU算法预测最新股票上证指数实现回归预测
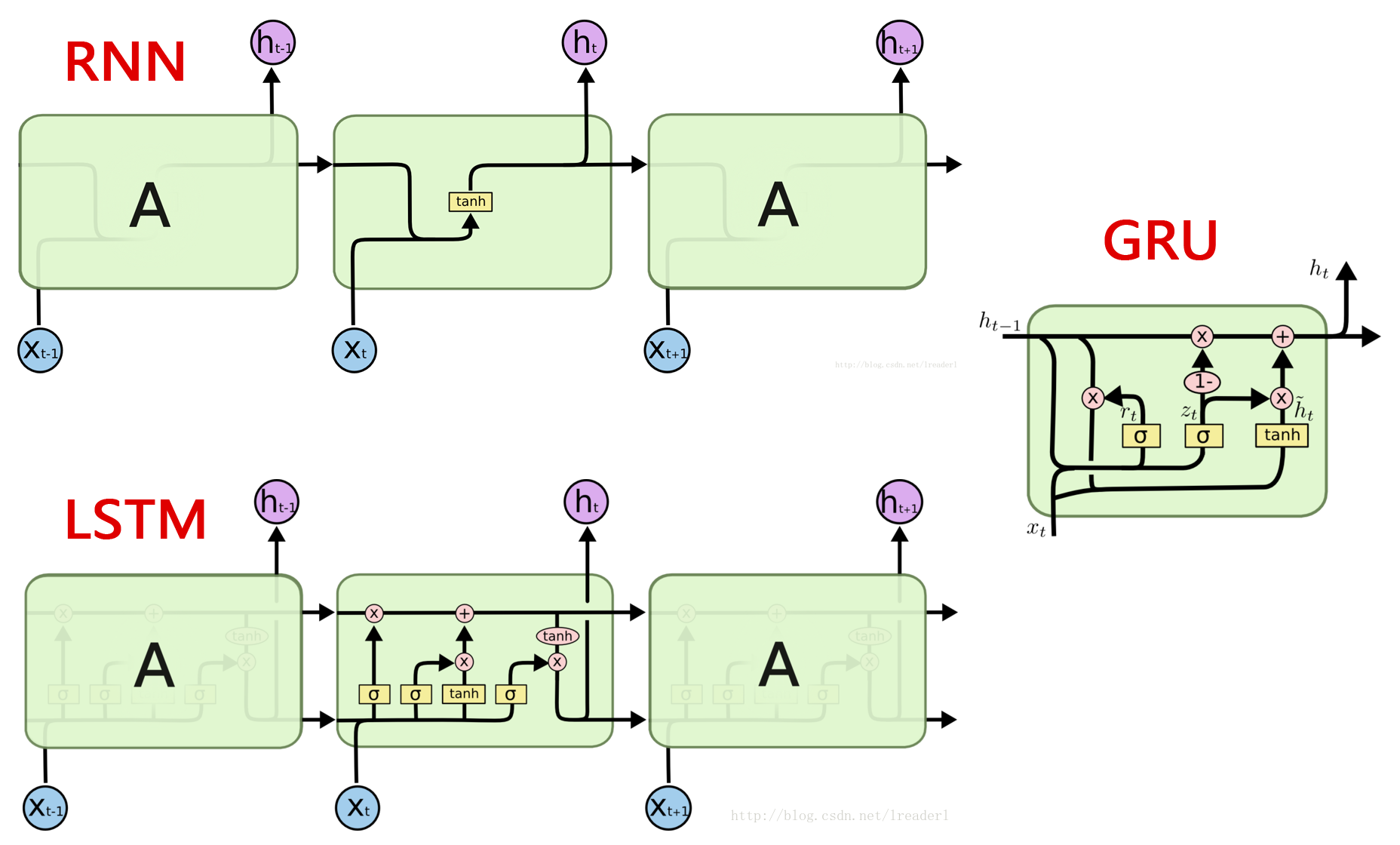
# 0、数据集预整理
# 数据集下载地址:上证指数(000001)历史交易数据_股票行情_网易财经

# 1、读取数据集
(7700, 11)
| 日期 | 股票代码 | 名称 | 收盘价 | 最高价 | 最低价 | 开盘价 | 前收盘 | 涨跌额 | 涨跌幅 | 成交量 | 成交金额 |
| 1990/12/19 | '000001 | 上证指数 | 99.98 | 99.98 | 95.79 | 96.05 | None | None | None | 1260 | 494000 |
| 1990/12/20 | '000001 | 上证指数 | 104.39 | 104.39 | 99.98 | 104.3 | 99.98 | 4.41 | 4.4109 | 197 | 84000 |
| 1990/12/21 | '000001 | 上证指数 | 109.13 | 109.13 | 103.73 | 109.07 | 104.39 | 4.74 | 4.5407 | 28 | 16000 |
| 1990/12/24 | '000001 | 上证指数 | 114.55 | 114.55 | 109.13 | 113.57 | 109.13 | 5.42 | 4.9666 | 32 | 31000 |
| 1990/12/25 | '000001 | 上证指数 | 120.25 | 120.25 | 114.55 | 120.09 | 114.55 | 5.7 | 4.976 | 15 | 6000 |
| 1990/12/26 | '000001 | 上证指数 | 125.27 | 125.27 | 120.25 | 125.27 | 120.25 | 5.02 | 4.1746 | 100 | 53000 |
| 1990/12/27 | '000001 | 上证指数 | 125.28 | 125.28 | 125.27 | 125.27 | 125.27 | 0.01 | 0.008 | 66 | 104000 |
| 1990/12/28 | '000001 | 上证指数 | 126.45 | 126.45 | 125.28 | 126.39 | 125.28 | 1.17 | 0.9339 | 108 | 88000 |
| 1990/12/31 | '000001 | 上证指数 | 127.61 | 127.61 | 126.48 | 126.56 | 126.45 | 1.16 | 0.9174 | 78 | 60000 |
| 1991/1/2 | '000001 | 上证指数 | 128.84 | 128.84 | 127.61 | 127.61 | 127.61 | 1.23 | 0.9639 | 91 | 59000 |
| 1991/1/3 | '000001 | 上证指数 | 130.14 | 130.14 | 128.84 | 128.84 | 128.84 | 1.3 | 1.009 | 141 | 93000 |
| 1991/1/4 | '000001 | 上证指数 | 131.44 | 131.44 | 130.14 | 131.27 | 130.14 | 1.3 | 0.9989 | 420 | 261000 |
| 1991/1/7 | '000001 | 上证指数 | 132.06 | 132.06 | 131.45 | 131.99 | 131.44 | 0.62 | 0.4717 | 217 | 141000 |
| 1991/1/8 | '000001 | 上证指数 | 132.68 | 132.68 | 132.06 | 132.62 | 132.06 | 0.62 | 0.4695 | 2926 | 1806000 |
| 1991/1/9 | '000001 | 上证指数 | 133.34 | 133.34 | 132.68 | 133.3 | 132.68 | 0.66 | 0.4974 | 5603 | 3228000 |
| 1991/1/10 | '000001 | 上证指数 | 133.97 | 133.97 | 133.34 | 133.93 | 133.34 | 0.63 | 0.4725 | 9990 | 5399000 |
| 1991/1/11 | '000001 | 上证指数 | 134.6 | 134.61 | 134.51 | 134.61 | 133.97 | 0.63 | 0.4703 | 13327 | 7115000 |
| 1991/1/14 | '000001 | 上证指数 | 134.67 | 135.19 | 134.11 | 134.11 | 134.6 | 0.07 | 0.052 | 12530 | 6883000 |
| 1991/1/15 | '000001 | 上证指数 | 134.74 | 134.74 | 134.19 | 134.21 | 134.67 | 0.07 | 0.052 | 1446 | 1010000 |
| 1991/1/16 | '000001 | 上证指数 | 134.24 | 134.74 | 134.14 | 134.19 | 134.74 | -0.5 | -0.3711 | 509 | 270000 |
# 2、数据预处理
# 2.1、数据清洗
# 2.2、时间格式数据标准化
利用strptime()函数,将时间改为%Y-%m-%d格式
# 2.3、定义y_train
y_train shape: (7200,)
# 2.4、构造时序性矩阵数据集:基于y重新设计训练集——符合时序性
1. data_all_train shape: (7190, 11) 2. data_all_train 3. label_0 label_1 label_2 ... label_8 label_9 y 4. 0 99.9800 104.3900 109.1300 ... 127.6100 128.8400 130.1400 5. 1 104.3900 109.1300 114.5500 ... 128.8400 130.1400 131.4400 6. 2 109.1300 114.5500 120.2500 ... 130.1400 131.4400 132.0600 7. 3 114.5500 120.2500 125.2700 ... 131.4400 132.0600 132.6800 8. 4 120.2500 125.2700 125.2800 ... 132.0600 132.6800 133.3400 9. ... ... ... ... ... ... ... ... 10. 7185 2870.3422 2868.4587 2875.4176 ... 2846.5473 2836.8036 2846.2217 11. 7186 2868.4587 2875.4176 2898.5760 ... 2836.8036 2846.2217 2852.3512 12. 7187 2875.4176 2898.5760 2883.7378 ... 2846.2217 2852.3512 2915.4311 13. 7188 2898.5760 2883.7378 2867.9237 ... 2852.3512 2915.4311 2921.3980 14. 7189 2883.7378 2867.9237 2813.7654 ... 2915.4311 2921.3980 2923.3711 15. 16. [7190 rows x 11 columns]
| label_0 | label_1 | label_2 | label_3 | label_4 | label_5 | label_6 | label_7 | label_8 | label_9 | y | |
| 0 | 99.98 | 104.39 | 109.13 | 114.55 | 120.25 | 125.27 | 125.28 | 126.45 | 127.61 | 128.84 | 130.14 |
| 1 | 104.39 | 109.13 | 114.55 | 120.25 | 125.27 | 125.28 | 126.45 | 127.61 | 128.84 | 130.14 | 131.44 |
| 2 | 109.13 | 114.55 | 120.25 | 125.27 | 125.28 | 126.45 | 127.61 | 128.84 | 130.14 | 131.44 | 132.06 |
| 3 | 114.55 | 120.25 | 125.27 | 125.28 | 126.45 | 127.61 | 128.84 | 130.14 | 131.44 | 132.06 | 132.68 |
| 4 | 120.25 | 125.27 | 125.28 | 126.45 | 127.61 | 128.84 | 130.14 | 131.44 | 132.06 | 132.68 | 133.34 |
| 5 | 125.27 | 125.28 | 126.45 | 127.61 | 128.84 | 130.14 | 131.44 | 132.06 | 132.68 | 133.34 | 133.97 |
| 6 | 125.28 | 126.45 | 127.61 | 128.84 | 130.14 | 131.44 | 132.06 | 132.68 | 133.34 | 133.97 | 134.6 |
| 7 | 126.45 | 127.61 | 128.84 | 130.14 | 131.44 | 132.06 | 132.68 | 133.34 | 133.97 | 134.6 | 134.67 |
| 8 | 127.61 | 128.84 | 130.14 | 131.44 | 132.06 | 132.68 | 133.34 | 133.97 | 134.6 | 134.67 | 134.74 |
| 9 | 128.84 | 130.14 | 131.44 | 132.06 | 132.68 | 133.34 | 133.97 | 134.6 | 134.67 | 134.74 | 134.24 |
| 10 | 130.14 | 131.44 | 132.06 | 132.68 | 133.34 | 133.97 | 134.6 | 134.67 | 134.74 | 134.24 | 134.25 |
| 11 | 131.44 | 132.06 | 132.68 | 133.34 | 133.97 | 134.6 | 134.67 | 134.74 | 134.24 | 134.25 | 134.24 |
| 12 | 132.06 | 132.68 | 133.34 | 133.97 | 134.6 | 134.67 | 134.74 | 134.24 | 134.25 | 134.24 | 134.24 |
| 13 | 132.68 | 133.34 | 133.97 | 134.6 | 134.67 | 134.74 | 134.24 | 134.25 | 134.24 | 134.24 | 133.72 |
| 14 | 133.34 | 133.97 | 134.6 | 134.67 | 134.74 | 134.24 | 134.25 | 134.24 | 134.24 | 133.72 | 133.17 |
| 15 | 133.97 | 134.6 | 134.67 | 134.74 | 134.24 | 134.25 | 134.24 | 134.24 | 133.72 | 133.17 | 132.61 |
| 16 | 134.6 | 134.67 | 134.74 | 134.24 | 134.25 | 134.24 | 134.24 | 133.72 | 133.17 | 132.61 | 132.05 |
| 17 | 134.67 | 134.74 | 134.24 | 134.25 | 134.24 | 134.24 | 133.72 | 133.17 | 132.61 | 132.05 | 131.46 |
| 18 | 134.74 | 134.24 | 134.25 | 134.24 | 134.24 | 133.72 | 133.17 | 132.61 | 132.05 | 131.46 | 130.95 |
| 19 | 134.24 | 134.25 | 134.24 | 134.24 | 133.72 | 133.17 | 132.61 | 132.05 | 131.46 | 130.95 | 130.44 |
| 20 | 134.25 | 134.24 | 134.24 | 133.72 | 133.17 | 132.61 | 132.05 | 131.46 | 130.95 | 130.44 | 129.97 |
| 21 | 134.24 | 134.24 | 133.72 | 133.17 | 132.61 | 132.05 | 131.46 | 130.95 | 130.44 | 129.97 | 129.51 |
# 2.5、对训练集进行 Z_score标准归一化处理
1. data_all_tr2arr_mean: 1964.7695519269184 2. data_all_tr2arr_std: 1068.4654234837196
# 2.6、将训练集的df格式转为tensor格式
1. train_loader: 2. <torch.utils.data.dataloader.DataLoader object at 0x0000014BB5A68AC8>
# 3、模型训练
# 3.1、模型建立:定义GRU模型、优化器、损失函数
采用GRU+Fully Connected Layer, hidden_size=64
# 3.2、模型训练:及时保存训练过程中的模型

1. 1 tensor(0.3308, grad_fn=<MseLossBackward>) 2. 2 tensor(0.1350, grad_fn=<MseLossBackward>) 3. 3 tensor(0.0127, grad_fn=<MseLossBackward>) 4. 4 tensor(0.0110, grad_fn=<MseLossBackward>) 5. 5 tensor(0.0114, grad_fn=<MseLossBackward>) 6. 6 tensor(0.0099, grad_fn=<MseLossBackward>) 7. 7 tensor(0.0222, grad_fn=<MseLossBackward>) 8. 8 tensor(0.0130, grad_fn=<MseLossBackward>) 9. 9 tensor(0.0150, grad_fn=<MseLossBackward>) 10. 10 tensor(0.0133, grad_fn=<MseLossBackward>) 11. 11 tensor(0.0057, grad_fn=<MseLossBackward>) 12. 12 tensor(0.0163, grad_fn=<MseLossBackward>) 13. 13 tensor(0.0216, grad_fn=<MseLossBackward>) 14. 14 tensor(0.0193, grad_fn=<MseLossBackward>) 15. 15 tensor(0.0333, grad_fn=<MseLossBackward>) 16. 16 tensor(0.0146, grad_fn=<MseLossBackward>) 17. 17 tensor(0.0118, grad_fn=<MseLossBackward>) 18. 18 tensor(0.0052, grad_fn=<MseLossBackward>) 19. 19 tensor(0.0046, grad_fn=<MseLossBackward>) 20. 20 tensor(0.0033, grad_fn=<MseLossBackward>) 21. 21 tensor(0.0078, grad_fn=<MseLossBackward>) 22. 22 tensor(0.0088, grad_fn=<MseLossBackward>) 23. 23 tensor(0.0049, grad_fn=<MseLossBackward>) 24. 24 tensor(0.0085, grad_fn=<MseLossBackward>) 25. 25 tensor(0.0044, grad_fn=<MseLossBackward>) 26. 26 tensor(0.0034, grad_fn=<MseLossBackward>) 27. 27 tensor(0.0050, grad_fn=<MseLossBackward>) 28. 28 tensor(0.0070, grad_fn=<MseLossBackward>) 29. 29 tensor(0.0072, grad_fn=<MseLossBackward>) 30. 30 tensor(0.0065, grad_fn=<MseLossBackward>) 31. 31 tensor(0.0037, grad_fn=<MseLossBackward>) 32. 32 tensor(0.0054, grad_fn=<MseLossBackward>) 33. 33 tensor(0.0033, grad_fn=<MseLossBackward>) 34. 34 tensor(0.0314, grad_fn=<MseLossBackward>) 35. 35 tensor(0.0035, grad_fn=<MseLossBackward>) 36. 36 tensor(0.0063, grad_fn=<MseLossBackward>) 37. 37 tensor(0.0080, grad_fn=<MseLossBackward>) 38. 38 tensor(0.0028, grad_fn=<MseLossBackward>) 39. 39 tensor(0.0068, grad_fn=<MseLossBackward>) 40. 40 tensor(0.0040, grad_fn=<MseLossBackward>) 41. 41 tensor(0.0021, grad_fn=<MseLossBackward>) 42. 42 tensor(0.0031, grad_fn=<MseLossBackward>) 43. 43 tensor(0.0017, grad_fn=<MseLossBackward>) 44. 44 tensor(0.0040, grad_fn=<MseLossBackward>) 45. 45 tensor(0.0025, grad_fn=<MseLossBackward>) 46. 46 tensor(0.0018, grad_fn=<MseLossBackward>) 47. 47 tensor(0.0041, grad_fn=<MseLossBackward>) 48. 48 tensor(0.0025, grad_fn=<MseLossBackward>) 49. 49 tensor(0.0013, grad_fn=<MseLossBackward>) 50. 50 tensor(0.0034, grad_fn=<MseLossBackward>) 51. 51 tensor(0.0014, grad_fn=<MseLossBackward>) 52. 52 tensor(0.0045, grad_fn=<MseLossBackward>) 53. 53 tensor(0.0051, grad_fn=<MseLossBackward>) 54. 54 tensor(0.0036, grad_fn=<MseLossBackward>) 55. 55 tensor(0.0019, grad_fn=<MseLossBackward>) 56. 56 tensor(0.0046, grad_fn=<MseLossBackward>) 57. 57 tensor(0.0032, grad_fn=<MseLossBackward>) 58. 58 tensor(0.0033, grad_fn=<MseLossBackward>) 59. 59 tensor(0.0033, grad_fn=<MseLossBackward>) 60. 60 tensor(0.0025, grad_fn=<MseLossBackward>) 61. 61 tensor(0.0021, grad_fn=<MseLossBackward>) 62. 62 tensor(0.0021, grad_fn=<MseLossBackward>) 63. 63 tensor(0.0036, grad_fn=<MseLossBackward>) 64. 64 tensor(0.0018, grad_fn=<MseLossBackward>) 65. 65 tensor(0.0075, grad_fn=<MseLossBackward>) 66. 66 tensor(0.0074, grad_fn=<MseLossBackward>) 67. 67 tensor(0.0010, grad_fn=<MseLossBackward>) 68. 68 tensor(0.0018, grad_fn=<MseLossBackward>) 69. 69 tensor(0.0039, grad_fn=<MseLossBackward>) 70. 70 tensor(0.0009, grad_fn=<MseLossBackward>) 71. 71 tensor(0.0035, grad_fn=<MseLossBackward>) 72. 72 tensor(0.0035, grad_fn=<MseLossBackward>) 73. 73 tensor(0.0011, grad_fn=<MseLossBackward>) 74. 74 tensor(0.0047, grad_fn=<MseLossBackward>) 75. 75 tensor(0.0020, grad_fn=<MseLossBackward>) 76. 76 tensor(0.0008, grad_fn=<MseLossBackward>) 77. 77 tensor(0.0019, grad_fn=<MseLossBackward>) 78. 78 tensor(0.0019, grad_fn=<MseLossBackward>) 79. 79 tensor(0.0025, grad_fn=<MseLossBackward>) 80. 80 tensor(0.0013, grad_fn=<MseLossBackward>) 81. 81 tensor(0.0023, grad_fn=<MseLossBackward>) 82. 82 tensor(0.0028, grad_fn=<MseLossBackward>) 83. 83 tensor(0.0020, grad_fn=<MseLossBackward>) 84. 84 tensor(0.0017, grad_fn=<MseLossBackward>) 85. 85 tensor(0.0010, grad_fn=<MseLossBackward>) 86. 86 tensor(0.0011, grad_fn=<MseLossBackward>) 87. 87 tensor(0.0048, grad_fn=<MseLossBackward>) 88. 88 tensor(0.0008, grad_fn=<MseLossBackward>) 89. 89 tensor(0.0008, grad_fn=<MseLossBackward>) 90. 90 tensor(0.0015, grad_fn=<MseLossBackward>) 91. 91 tensor(0.0024, grad_fn=<MseLossBackward>) 92. 92 tensor(0.0036, grad_fn=<MseLossBackward>) 93. 93 tensor(0.0030, grad_fn=<MseLossBackward>) 94. 94 tensor(0.0017, grad_fn=<MseLossBackward>) 95. 95 tensor(0.0005, grad_fn=<MseLossBackward>) 96. 96 tensor(0.0014, grad_fn=<MseLossBackward>) 97. 97 tensor(0.0037, grad_fn=<MseLossBackward>) 98. 98 tensor(0.0048, grad_fn=<MseLossBackward>) 99. 99 tensor(0.0022, grad_fn=<MseLossBackward>) 100. 100 tensor(0.0006, grad_fn=<MseLossBackward>) 101. 101 tensor(0.0005, grad_fn=<MseLossBackward>) 102. 102 tensor(0.0027, grad_fn=<MseLossBackward>) 103. 103 tensor(0.0015, grad_fn=<MseLossBackward>) 104. 104 tensor(0.0014, grad_fn=<MseLossBackward>) 105. 105 tensor(0.0029, grad_fn=<MseLossBackward>) 106. 106 tensor(0.0011, grad_fn=<MseLossBackward>) 107. 107 tensor(0.0082, grad_fn=<MseLossBackward>) 108. 108 tensor(0.0017, grad_fn=<MseLossBackward>) 109. 109 tensor(0.0034, grad_fn=<MseLossBackward>) 110. 110 tensor(0.0010, grad_fn=<MseLossBackward>) 111. 111 tensor(0.0015, grad_fn=<MseLossBackward>) 112. 112 tensor(0.0017, grad_fn=<MseLossBackward>) 113. 113 tensor(0.0016, grad_fn=<MseLossBackward>) 114. 114 tensor(0.0006, grad_fn=<MseLossBackward>) 115. 115 tensor(0.0023, grad_fn=<MseLossBackward>) 116. 116 tensor(0.0006, grad_fn=<MseLossBackward>) 117. 117 tensor(0.0018, grad_fn=<MseLossBackward>) 118. 118 tensor(0.0013, grad_fn=<MseLossBackward>) 119. 119 tensor(0.0016, grad_fn=<MseLossBackward>) 120. 120 tensor(0.0007, grad_fn=<MseLossBackward>) 121. 121 tensor(0.0007, grad_fn=<MseLossBackward>) 122. 122 tensor(0.0043, grad_fn=<MseLossBackward>) 123. 123 tensor(0.0038, grad_fn=<MseLossBackward>) 124. 124 tensor(0.0011, grad_fn=<MseLossBackward>) 125. 125 tensor(0.0025, grad_fn=<MseLossBackward>) 126. 126 tensor(0.0013, grad_fn=<MseLossBackward>) 127. 127 tensor(0.0005, grad_fn=<MseLossBackward>) 128. 128 tensor(0.0013, grad_fn=<MseLossBackward>) 129. 129 tensor(0.0021, grad_fn=<MseLossBackward>) 130. 130 tensor(0.0011, grad_fn=<MseLossBackward>) 131. 131 tensor(0.0034, grad_fn=<MseLossBackward>) 132. 132 tensor(0.0022, grad_fn=<MseLossBackward>) 133. 133 tensor(0.0019, grad_fn=<MseLossBackward>) 134. 134 tensor(0.0020, grad_fn=<MseLossBackward>) 135. 135 tensor(0.0009, grad_fn=<MseLossBackward>) 136. 136 tensor(0.0100, grad_fn=<MseLossBackward>) 137. 137 tensor(0.0009, grad_fn=<MseLossBackward>) 138. 138 tensor(0.0012, grad_fn=<MseLossBackward>) 139. 139 tensor(0.0009, grad_fn=<MseLossBackward>) 140. 140 tensor(0.0003, grad_fn=<MseLossBackward>) 141. 141 tensor(0.0007, grad_fn=<MseLossBackward>) 142. 142 tensor(0.0017, grad_fn=<MseLossBackward>) 143. 143 tensor(0.0027, grad_fn=<MseLossBackward>) 144. 144 tensor(0.0149, grad_fn=<MseLossBackward>) 145. 145 tensor(0.0027, grad_fn=<MseLossBackward>) 146. 146 tensor(0.0024, grad_fn=<MseLossBackward>) 147. 147 tensor(0.0013, grad_fn=<MseLossBackward>) 148. 148 tensor(0.0011, grad_fn=<MseLossBackward>) 149. 149 tensor(0.0006, grad_fn=<MseLossBackward>) 150. 150 tensor(0.0008, grad_fn=<MseLossBackward>) 151. save success! F:\File_Python\……\20220627_models/RNN_GRU_Model_300_150.pkl
# 3.3、对标签数据单独进行归一化
1. y2arr_normal: 2. [-1.74529705 -1.74116964 -1.73673337 ... 1.26852879 1.29623048 3. 1.32378233]
# 3.4、基于GRU模型预测:基于训练好的GRU模型,预测test数据集
cut_train_test: 7700 7200
# 3.5、模型评估
1. cut_train_test: 7700 7400 2. RNN_GRU_Model_300 R2 value: 0.8737662561295777 3. RNN_GRU_Model_300 MAE value: 48.39948391799124 4. RNN_GRU_Model_300 MSE value: 3773.501360880409
# 对比真实值VS预测值曲线




