小程序数据缓存相关知识
数据缓存:缓存数据,从而在小程序退出后再次打开时,可以从缓存中读取上次保存的数据,常用的数据缓存API如下表所示:
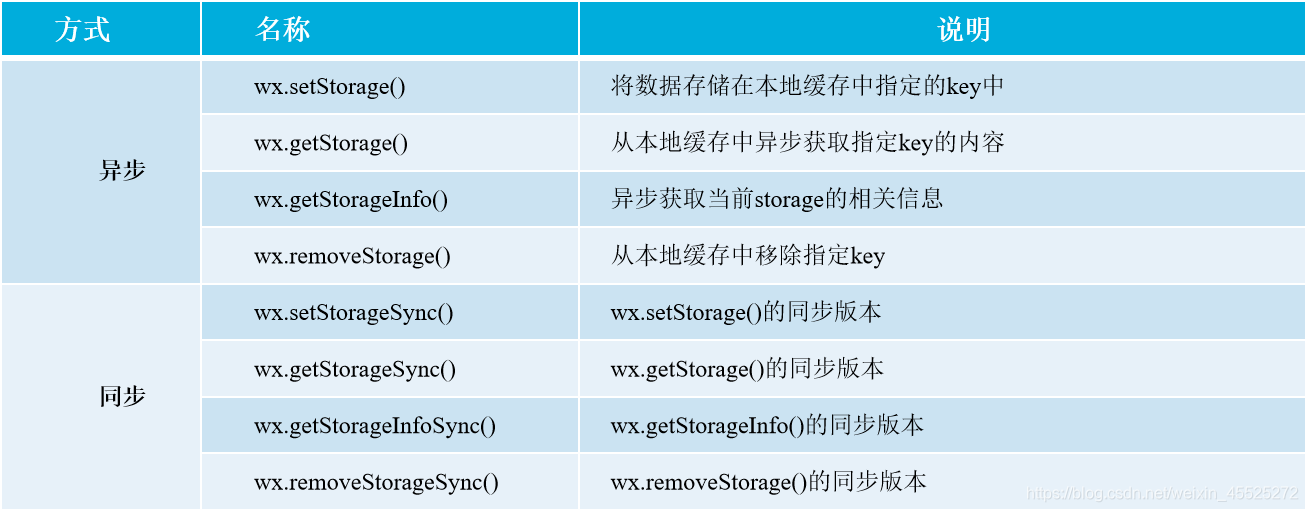
注意:将数据存储在本地缓存中指定的 key 中。会覆盖掉原来该 key 对应的内容。除非用户主动删除或因存储空间原因被系统清理,否则数据都一直可用。单个 key 允许存储的最大数据长度为 1MB,所有数据存储上限为 10MB。
参数
详细参数请见
https://developers.weixin.qq.com/miniprogram/dev/api/storage/wx.setStorage.html
保存数据缓存
// 保存数据缓存 wx.setStorage({ key: 'key', // 本地缓存中指定的key data: 'value', // 需要存储的内容(支持对象或字符串) success: res => {}, // 接口调用成功的回调函数 fail: res => {} // 接口调用失败的回调函数 })
获取数据缓存
// 获取数据缓存 wx.getStorage({ key: 'key', // 本地缓存中指定的 key success: res => { // 接口调用成功的回调函数 console.log(res.data) }, fail: res => {} // 接口调用失败的回调函数 })
示例:在onLoad中存入并获取
// pages/test/test.js Page({ onLoad: function(options) { // 保存数据缓存 wx.setStorage({ key: 'key', // 本地缓存中指定的key data: 'value', // 需要存储的内容(支持对象或字符串) success: res => { // 获取数据缓存 wx.getStorage({ key: 'key', // 本地缓存中指定的 key success: res => { // 接口调用成功的回调函数 console.log(res.data) }, fail: res => { } // 接口调用失败的回调函数 }) }, // 接口调用成功的回调函数 fail: res => {} // 接口调用失败的回调函数 }) } })





