1. 数仓与BI
- 数据仓库(Data Warehouse)
数据仓库是一个各种数据的中心存储系统(包括历史数据和当前数据),是BI的核心组件。这里所说的数据包括来自企业内部的各种业务数据,例如订单,库存,交易流,账目,客户,供应商等,同时也包括从外部获取的各种数据,例如爬虫爬取的数据等。
- BI 商业智能(Business Intelligence)
商业智能通常被理解为将企业中现有的数据转换为知识,帮助企业做合理的,明智的经营决策工具,是企业数字化转型的关键系统。为了将数据转化为知识,需要利用数据仓库,联机分析处理(OLAP)工具和数据挖掘等技术
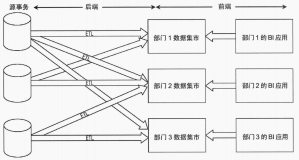
- 数仓和BI的关系

2. 数据处理系统
2.1 OLTP和OLAP的区别
- 联机事务处理OLTP(on-line transaction processing)- 事务驱动
OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
OLTP采用实体-联系ER模型和面向应用的数据库设计
- 联机分析处理OLAP(On-Line Analytical Processing)- 分析驱动
OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLAP采用星型或雪花模型和面向主题的数据库设计.
下表列出了OLTP与OLAP之间的比较:
| OLTP | OLAP | |
主要使用场景 |
在线业务服务 |
数据分析,挖掘,机器学习 |
| 涉及数据量 | 当前正在发生的业务数据 | 历史存档数据,可能时间跨度比较大 |
事务和数据完整性 |
对事务和数据一致性要求比较高 |
对事务能力没有要求,数据不一致也可重建数据 |
功能使用需求 |
简单的增删改查,要求相应极端 |
复杂的聚合和多数据源关联,查询执行时间可到分钟,小时,天级别 |
并发要求 |
高并发 |
低并发 |
技术实现方案 |
事务,索引,存储计算在一起 |
大量的scan,列式存储,存储计算可分离 |
数据模型/规约 |
关系模型,3NF范式 |
关系模型,维度模型,对范式要求低 |
总的来说,OLTP就是面向我们的应用系统数据库的,OLAP是面向数据仓库的。

2.2 OLTP和OLAP存储区别
⼀般来说OLTP数据库使⽤⾏式存储,OLAP数据库使⽤列式存储
- OLAP场景下列式存储更具优势


- OLTP场景下行式存储更具优势


2.3 OLAP分类
OLAP 是一种让用户可以用从不同视角方便快捷的分析数据的计算方法。
主流的 OLAP 可以分为3类:
多维 OLAP ( Multi-dimensional OLAP )、关系型 OLAP ( Relational OLAP ) 和混合 OLAP ( Hybrid OLAP ) 三大类。
- MOLAP 的优点和缺点
MOLAP的典型代表是:Druid,Kylin,Doris,MOLAP一般会根据用户定义的数据维度、度量(也可以叫指标)在数据写入时生成预聚合数据;Query查询到来时,实际上查询的是预聚合的数据而不是原始明细数据,在查询模式相对固定的场景中,这种优化提速很明显。
MOLAP 的优点和缺点都来自于其数据预处理 ( pre-processing ) 环节。
数据预处理,将原始数据按照指定的计算规则预先做聚合计算,这样避免了查询过程中出现大量的即使计算,提升了查询性能。
但是这样的预聚合处理,需要预先定义维度,会限制后期数据查询的灵活性;如果查询工作涉及新的指标,需要重新增加预处理流程,损失了灵活度,存储成本也很高;同时,这种方式不支持明细数据的查询,仅适用于聚合型查询(如:sum,avg,count)。
因此,MOLAP 适用于查询场景相对固定并且对查询性能要求非常高的场景。如广告主经常使用的广告投放报表分析。
- ROLAP 的优点和缺点
ROLAP的典型代表是:Presto,Impala,GreenPlum,Clickhouse,Elasticsearch,Hive,Spark SQL,Flink SQL
数据写入时,ROLAP并未使用像MOLAP那样的预聚合技术;ROLAP收到Query请求时,会先解析Query,生成执行计划,扫描数据,执行关系型算子,在原始数据上做过滤(Where)、聚合(Sum, Avg, Count)、关联(Join),分组(Group By)、排序(Order By)等,最后将结算结果返回给用户,整个过程都是即时计算,没有预先聚合好的数据可供优化查询速度,拼的都是资源和算力的大小。
ROLAP 不需要进行数据预处理 ( pre-processing ),因此查询灵活,可扩展性好。这类引擎使用 MPP 架构 ( 与Hadoop相似的大型并行处理架构,可以通过扩大并发来增加计算资源 ),可以高效处理大量数据。
但是当数据量较大或 query 较为复杂时,查询性能也无法像 MOLAP 那样稳定。所有计算都是即时触发 ( 没有预处理 ),因此会耗费更多的计算资源,带来潜在的重复计算。
因此,ROLAP 适用于对查询模式不固定、查询灵活性要求高的场景。如数据分析师常用的数据分析类产品,他们往往会对数据做各种预先不能确定的分析,所以需要更高的查询灵活性。
- 混合 OLAP ( HOLAP )
混合 OLAP,是 MOLAP 和 ROLAP 的一种融合。当查询聚合性数据的时候,使用MOLAP 技术;当查询明细数据时,使用 ROLAP 技术。在给定使用场景的前提下,以达到查询性能的最优化。
3. 离线数仓
3.1 离线数仓架构
离线数仓特点:
数据源通过离线的方式导入到离线数仓中
数据处理采用MapReduce,Hive,SparkSql等离线计算引擎
离线数仓内部分层计算
通过OLAP引擎和数据服务,对外提供计算之后的数据

3.2 离线数仓分层
ADS(Application Data Store)层:应用数据层
DWS(Data Warehouse Summary)层:高度汇总数据层。从ODS层中对用户的行为做一个初步的汇总,抽象出来一些通用的维度:时间、ip、id,并根据这些维度做一些统计值,比如用户每个时间段在不同登录ip购买的商品数等。这里做一层轻度的汇总会让计算更加的高效,在此基础上如果计算仅7天、30天、90天的行为的话会快很多。我们希望80%的业务都能通过我们的DWS层计算,而不是ODS。
DWM(Data Warehouse Middle)层:中间层, 对明细数据按照常用的维度,做轻度汇总
DWD(Data Warehouse Detail)层:明细数据层。这一层主要解决一些数据质量问题和数据的完整度问题。比如用户的资料信息来自于很多不同表,而且经常出现延迟丢数据等问题,为了方便各个使用方更好的使用数据,我们可以在这一层做一个屏蔽。(汇总多个表)
ODS(Operational Data Store)层: 离线或准实时数据接入层


3.3 典型案例

4. 实时数仓-Lambda架构
4.1 Lambda架构



4.2 Lambda架构的缺陷
- 使用两套大数据处理引擎,如果两套大数据处理引擎的API不同,有任何逻辑上的改动,需要在两边同步更新,维护成本高,后期的迭代时间周期长。
- 早期流处理层的结果只是近似准确。
5. 实时数仓-Kappa架构
Kafka的创始人Jay Kreps认为在很多场景下,维护一套Lambda架构的大数据处理平台耗时耗力,于是提出在某些场景下,没有必要维护一个批处理层,直接使用一个流处理层即可满足需求,即下图所示的Kappa架构。
5.1 Kappa架构


5.2 Kappa架构重处理过程
在Kappa架构中,即使流处理引擎再健壮,由于上游数据原因,仍然存在数据重新处理的需求。修改数据或历史数 据重新处理都通过上游重放完成(从数据源拉取数据重新计算⼀次)。
Kappa架构最⼤的问题是流式重新处理历史数据的吞吐能⼒会低于批处理,但这个可以通过增加计算资源来弥补。
重新处理是⼈们对Kappa架构最担⼼的点,但实际上并不复杂:
- 1. 选择⼀个具有重放功能的、能够保存历史数据并⽀持多消费者的消息队列,根据需求设置历史数据保存的时 ⻓,⽐如Kafka,可以保存全部历史数据。
- 2. 当某个或某些指标有重新处理的需求时,按照新逻辑写⼀个新作业,然后从上游消息队列的最开始重新消费, 把结果写到⼀个新的下游表中。
- 3. 当新作业赶上进度后,应⽤切换数据源,读取2中产⽣的新结果表。 4. 停⽌⽼的作业,删除⽼的结果表
6. Lambda vs Kappa架构

7. 离线数仓 vs 实时数仓