之前有粉丝让我爬取网上热搜话题,根据粉丝的这个提议,我想到了爬取不同平台的热搜话题并做成了一个:全网实时热搜话题『跑马灯』可视化。
特点:实时、可视化浏览
这里的热搜数据来源主要是:微博和知乎,选择这两个平台的目的:1.用户流量大、2.直接的热搜数据Api接口。
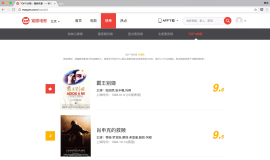
先看一下效果:

动图版:

1、获取数据
1.采集微博数据
微博的热搜数据Api接口如下:
https://s.weibo.com/top/summary/

网页分析
先看一下网页源码

数据列表在id为pl\_top\_realtimehot中,接着往下找tbody,tr是热点数据的列表,每一个tr中都有a标签,a标签中有热点标题和对应热点链接。
url = "https://s.weibo.com/top/summary/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; rv:85.0) Gecko/20100101 Firefox/85.0",
"Host": "s.weibo.com"
}
r = requests.get(url, headers=headers)
soup = bs(r.text, "lxml")
div = soup.find("div", {"id": "pl_top_realtimehot"}).find("tbody")
tr_tags = div.find_all("tr")
通过请求并对其进行提取网页源代码中的热搜数据(这里使用了BeautifulSoup库去解析网页源代码)
完整代码
###爬取微博热搜
def get_weibo():
url = "https://s.weibo.com/top/summary/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; rv:85.0) Gecko/20100101 Firefox/85.0",
"Host": "s.weibo.com"
}
r = requests.get(url, headers=headers)
soup = bs(r.text, "lxml")
div = soup.find("div", {"id": "pl_top_realtimehot"}).find("tbody")
tr_tags = div.find_all("tr")
# 为数据保存做准备
hot_text = []
hot_link = []
for tr in tr_tags:
a = tr.find("a")
hot_text.append(a.text)
# 获取链接
hot_link.append("https://s.weibo.com" + a.get("href"))
return hot_text, hot_link
将爬取微博热搜数据代码封装成函数get\_weibo,方便可视化代码进行调用,其中的hot\_text是热点标题,hot_link是热点的链接

2.采集知乎数据
知乎热搜api接口如下:
https://api.zhihu.com/topstory/hot-list?limit=10&reverse_order=0
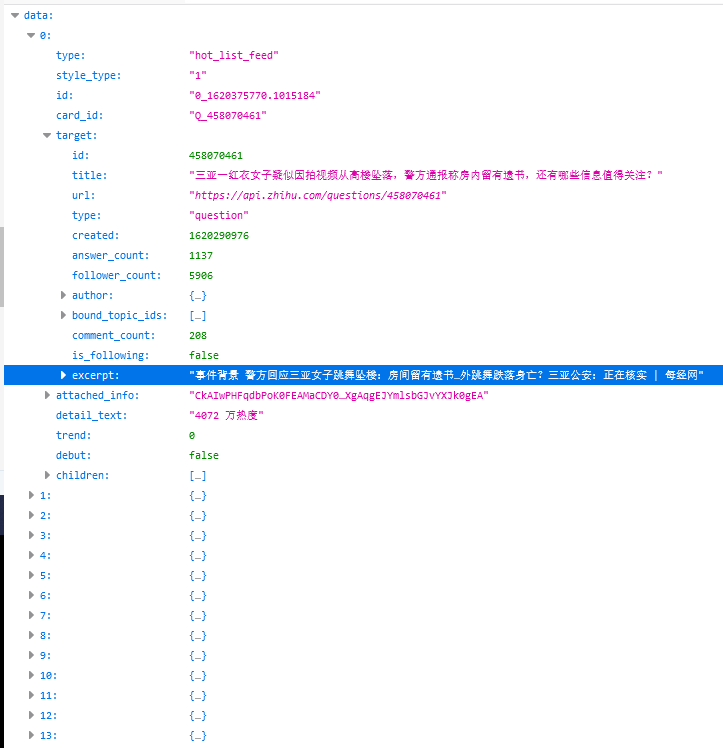
提取数据
这里直接返回的就是json数据,因此不需要进行网页分析,只需要知道json数据中,热搜标题和对应的热搜标题链接的key即可

数据在data里面,每一条数据的热搜标题和链接都在target下,热搜标题是title,热搜标题链接是url
###爬取知乎热搜数据
def get_zhihu():
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0'}
url = "https://api.zhihu.com/topstory/hot-list?limit=10&reverse_order=0"
text = requests.get(url, headers=headers).json()
# 为数据保存做准备
hot_text = []
hot_link = []
for i in text['data']:
hot_text.append(i['target']['title'])
hot_link.append(i['target']['url'])
return hot_text,hot_link
同样的,将爬取知乎热搜数据代码封装成函数get\_zhihu,方便可视化代码进行调用,其中的hot\_text是热点标题,hot_link是热点的链接

2、Flask后端
为了将采集和可视化网页结合,这里选择使用Flask框架去搭建网站。
跳转网页
#进入页面
@app.route('/')
def index():
return render_template('view.html')
制作API接口,方便获取数据并返回Json数据
###获取微博和知乎热搜数据
@app.route('/getdata')
def alldata():
wb_t, wb_u = get_weibo()
zh_t, zh_u = get_zhihu()
t = []
u = []
for i in range(0,len(wb_t)):
t.append(wb_t[i])
u.append(wb_u[i])
for i in range(0,len(zh_t)):
t.append(zh_t[i])
u.append(zh_u[i])
res = {}
res['title'] = t
res['url'] = u
return Response(json.dumps(res), mimetype='application/json')
为了方便大家直接运行,不需要改ip,这里就使用默认的本机ip(小伙伴拿到源码后直接运行就行),端口是80
if __name__ == "__main__":
"""初始化,debug=True"""
app.run(host='127.0.0.1', port=80,debug=True)

3、跑马灯可视化展示

这里是使用html网页制作的跑马灯滚动效果,核心代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<script src="../static/js/jquery-2.1.4.min.js"></script>
<title>全网实时热搜话题-李运辰(公众号:Python研究者)</title>
<style>
a{
text-decoration: none;
}
.f1{
color:"red";
}
</style>
</head>
<body>
<div id="textdata">
</div>
<!--获取微博和知乎热搜数据-->
<script type="text/javascript">
function getdata(){
$.ajax({
type: 'GET',
url: "http://127.0.0.1/getdata",
dataType: 'json',
success: function(data){}
}
});
}
setInterval("getdata()","15000");//1000表示1秒
这里设置了15秒采集一次数据(实现了实时效果)
4、启动
直接运行main.py文件

然后在浏览器访问
http://127.0.0.1
接着等待几秒就出现跑马灯可视化效果

gif动图版:

5、小结
为了大家方便学习,辰哥已经把本文的完整源码上传,需要的在同名公号回复:热搜跑马灯
本文也是应粉丝要求,爬取热搜话题,最后我制作出来了实时热搜『跑马灯』可视化效果。
特点:实时、可视化浏览