
大家好,我是辰哥~~~
前提:在学习本文采集小程序数据之前,相信大家都掌握了抓取数据包的技能,比如使用Mitmproxy进行抓取数据包。如果看到这里的你还没有掌握的话,可以参与辰哥之前的写的一篇关于mitmproxy使用的文章(实战|手把手教你如何使用抓包神器MitmProxy)。
本文目标:利用Mitmproxy抓取某程小程序景点数据,并实现翻页(下一页)循环爬取。
思路:1、利用Mitmproxy抓取数据包,并进行分析
2、利用分析的结果,编写Python代码进行提取数据,并进行实现下一页采集
01、mitmproxy抓取数据包
1.启动mitmproxy
先配置好手机的代理IP和启动mitmproxy

在终端中启动mitmweb
mitmweb

在浏览器中查看数据包(输入mitmweb会自动在浏览器中打开网页,如果没有打开的则手动输入)
http://127.0.0.1:8081/#/flows
2.访问小程序
打开同程旅行小程序,点击全部景点

可以看到页面中出现了景点列表:
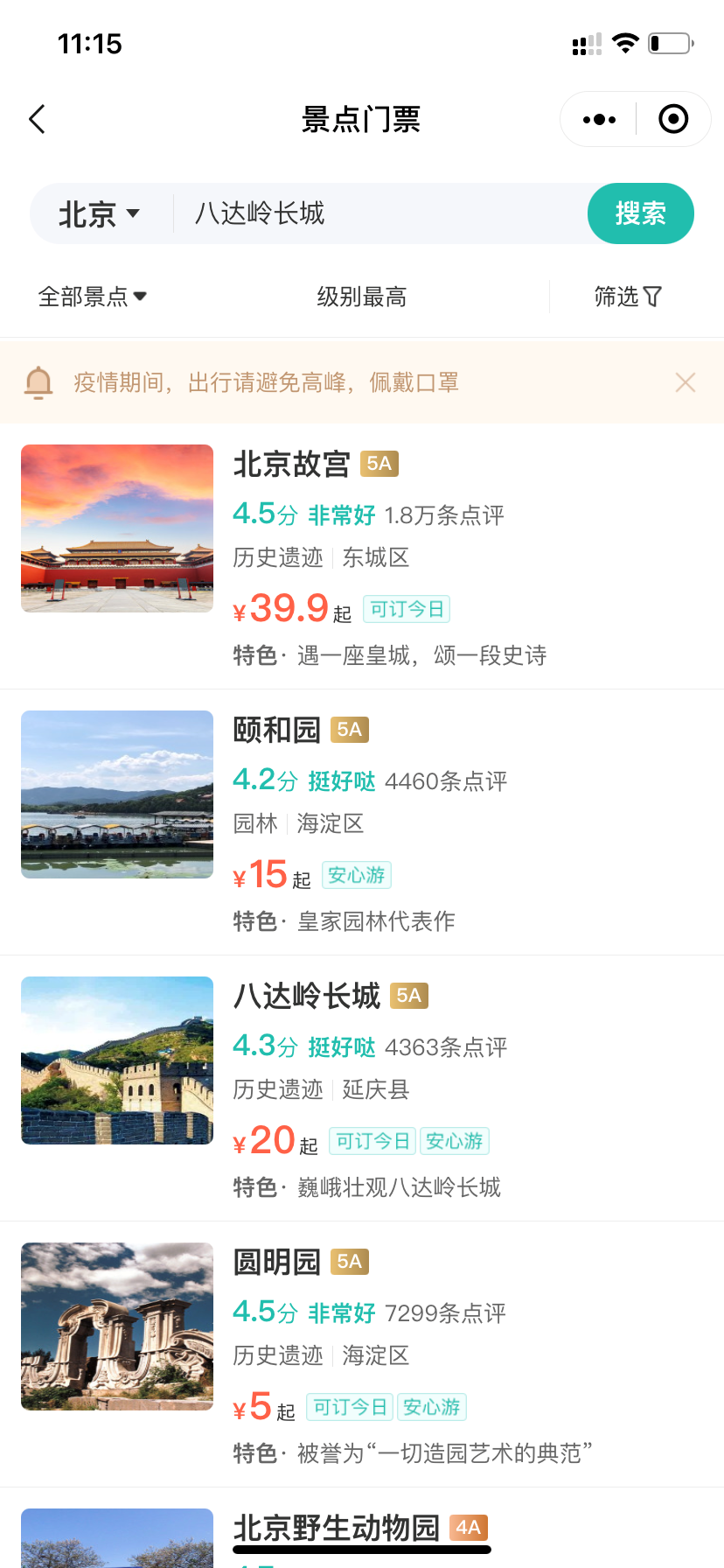
3.浏览器中查看数据包

上图中红框部分是景点列表的api接口,点击response查看返回的数据。

02、Python解析数据包
1.分析接口
经过分析,发现该接口是没有反爬(签名验证),因此通过这个接口可以直接爬取多页数据,比如修改接口链接中的参数
参数:page页数
PageSize条数
CityId城市
keyword关键词
...
因此通过修改page就可以获取全部景点数据。

得知接口链接,在python中通过requests请求去获取数据,这种方式我们都会。
import requests
### 获取第1页~第10页数据
for p in range(1,11):
# 页数
url = "https://wx.17u.cn/scenery/json/scenerylist.html?PosCityId=78&CityId=53&page="+str(p)+"&sorttype=0&PageSize=20&IsSurrounding=1&isSmallPro=1&isTcSmallPro=1&isEncode=0&Lon=113.87234497070312&Lat=22.90543556213379&issearchbytimenow=0&IsNeedCount=1&keyword=&IsPoi=0&status=2&CityArea=5&Grades=&IsSearchKeyWordScenery=1"
response = requests.get(url).json()
print(response)
今天我们用另一种方式去获取数据,这种方式可以用于绕过接口签名验证的反爬,比如sign或者x-sign等签名加密参数。
2.直接解析数据包
相信看了辰哥的这篇文章(实战|手把手教你如何使用抓包神器MitmProxy)的读者都知道,mitmproxy抓取的数据包,除了在浏览器可以查看外,还可以编写的python代码一边抓取数据包,一边进行解析。
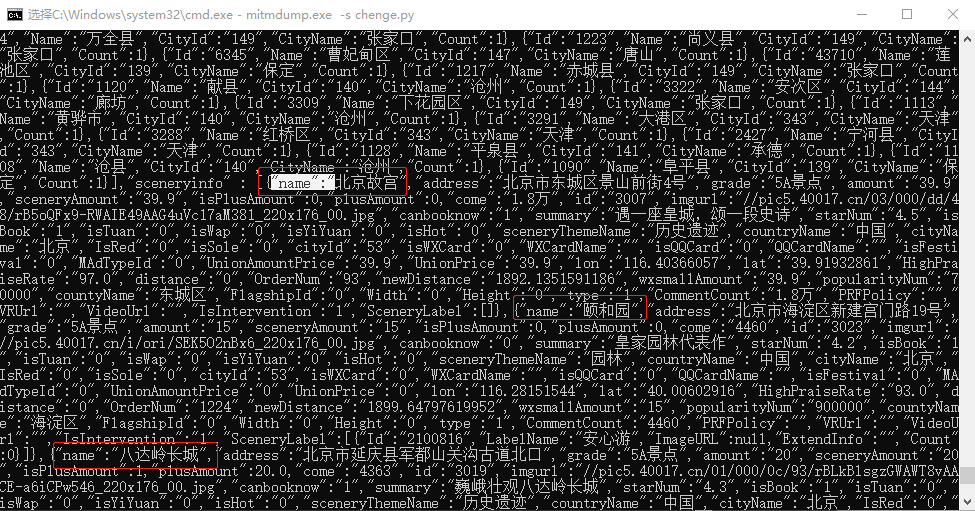
先看一下python可以获取数据包的那些数据(下图仅写成部分常用的)

在终端中调用上面的py代码,结果如下:
下面开始真正编写python代码,将景点数据直接保存在txt中。

在chenge.py文件中,修改response函数部分(如上图)
启动程序:
mitmdump.exe -s chenge.py


api接口返回的数据前面包含了:"state":"100","error":"查询成功"
因此判断响应的数据中包含这个内容说明是含有景点列表的

景点列表数据在json数据的sceneryinfo字段中。我们将字段(name、address、grade)的内容取出来保存到txt文件中,并命名为景点.txt

在小程序中向下滑动,加载更多数据,同时mitmproxy继续抓包,对应的python程序将继续保存数据到txt中。
ps:这里仅讲述技术的使用,就没有去将数据完整爬取下来,并且为了演示数据可以保存,也暂时保存到txt,读者可以根据需要保存到数据库或者excel。
03、小结
本文目标:利用Mitmproxy抓取某程旅行小程序景点数据,并实现翻页(下一页)循环爬取。并且还讲述了如何通过mitmproxy绕过接口签名验证的反爬,比如sign或者x-sign等签名加密参数(虽然本文没有加密参数,但是技术大家可以先掌握,在遇到的时可以使用)
不会的小伙伴,感觉动手练习!!!!最后说一声:原创不易,求给个赞!
