HTTP 内容协商
什么是内容协商
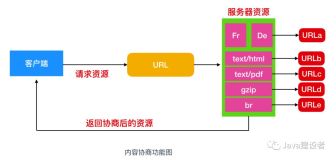
在 HTTP 中,内容协商是一种用于在同一 URL 上提供资源的不同表示形式的机制。内容协商机制是指客户端和服务器端就响应的资源内容进行交涉,然后提供给客户端最为适合的资源。内容协商会以响应资源的语言、字符集、编码方式等作为判断的标准。

内容协商的种类
内容协商主要有以下3种类型:
服务器驱动协商(Server-driven Negotiation)
这种协商方式是由服务器端进行内容协商。服务器端会根据请求首部字段进行自动处理
客户端驱动协商(Agent-driven Negotiation)
这种协商方式是由客户端来进行内容协商。
透明协商(Transparent Negotiation)
是服务器驱动和客户端驱动的结合体,是由服务器端和客户端各自进行内容协商的一种方法。
内容协商的分类有很多种,主要的几种类型是 Accept、Accept-Charset、Accept-Encoding、Accept-Language、Content-Language。
一般来说,客户端用 Accept 头告诉服务器希望接收什么样的数据,而服务器用 Content 头告诉客户端实际发送了什么样的数据。
为什么需要内容协商
我们为什么需要内容协商呢?在回答这个问题前我们先来看一下 TCP 和 HTTP 的不同。
在 TCP / IP 协议栈里,传输数据基本上都是 header+body 的格式。但 TCP、UDP 因为是传输层的协议,它们不会关心 body 数据是什么,只要把数据发送到对方就算是完成了任务。
而 HTTP 协议则不同,它是应用层的协议,数据到达之后需要告诉应用程序这是什么数据。当然不告诉应用这是哪种类型的数据,应用也可以通过不断尝试来判断,但这种方式无疑十分低效,而且有很大几率会检查不出来文件类型。
所以鉴于此,浏览器和服务器需要就数据的传输达成一致,浏览器需要告诉服务器自己希望能够接收什么样的数据,需要什么样的压缩格式,什么语言,哪种字符集等;而服务器需要告诉客户端自己能够提供的服务是什么。
所以我们就引出了内容协商的几种概念,下面依次来进行探讨
内容协商标头
Accept
接受请求 HTTP 标头会通告客户端自己能够接受的 MIME 类型
那么什么是 MIME 类型呢?在回答这个问题前你应该先了解一下什么是 MIME
MIME: MIME (Multipurpose Internet Mail Extensions) 是描述消息内容类型的因特网标准。MIME 消息能包含文本、图像、音频、视频以及其他应用程序专用的数据。
也就是说,MIME 类型其实就是一系列消息内容类型的集合。那么 MIME 类型都有哪些呢?
文本文件:text/html、text/plain、text/css、application/xhtml+xml、application/xml
图片文件:image/jpeg、image/gif、image/png
视频文件:video/mpeg、video/quicktime
应用程序二进制文件:application/octet-stream、application/zip
比如,如果浏览器不支持 PNG 图片的显示,那 Accept 就不指定image/png,而指定可处理的 image/gif 和 image/jpeg 等图片类型。
一般 MIME 类型也会和 q 这个属性一起使用,q 是什么?q 表示的是权重,来看一个例子
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
这是什么意思呢?若想要给显示的媒体类型增加优先级,则使用 q= 来额外表示权重值,没有显示权重的时候默认值是1.0 ,我给你列个表格你就明白了
| q | MIME |
| 1.0 | text/html |
| 1.0 | application/xhtml+xml |
| 0.9 | application/xml |
| 0.8 | * / * |
也就是说,这是一个放置顺序,权重高的在前,低的在后,application/xml;q=0.9 是不可分割的整体。
Accept-Charset
Accept-charset 属性规定服务器处理表单数据所接受的字符编码;Accept-charset 属性允许你指定一系列字符集,服务器必须支持这些字符集,从而得以正确解释表单中的数据。
Accept-Charset 没有对应的标头,服务器会把这个值放在 Content-Type中用 charset=xxx来表示,
例如,浏览器请求 GBK 或 UTF-8 的字符集,然后服务器返回的是 UTF-8 编码,就是下面这样
Accept-Charset: gbk, utf-8 Content-Type: text/html; charset=utf-8
Accept-Language
首部字段 Accept-Language 用来告知服务器用户代理能够处理的自然语言集(指中文或英文等),以及自然语言集的相对优先级。可一次指定多种自然语言集。和 Accept 首部字段一样,按权重值 q= 来表示相对优先级。
Accept-Language: en-US,en;q=0.5
Accept-Encoding
表示 HTTP 标头会标明客户端希望服务端返回的内容编码,这通常是一种压缩算法。Accept-Encoding 也是属于内容协商 的一部分,使用并通过客户端选择 Content-Encoding 内容进行返回。
即使客户端和服务器都能够支持相同的压缩算法,服务器也可能选择不压缩并返回,这种情况可能是由于这两种情况造成的:
- 要发送的数据已经被压缩了一次,第二次压缩并不会导致发送的数据更小
- 服务器过载,无法承受压缩带来的性能开销,通常,如果服务器使用 CPU 超过 80% ,
Microsoft则建议不要使用压缩
下面是 Accept-Encoding 的使用方式
Accept-Encoding: gzip Accept-Encoding: compress Accept-Encoding: deflate Accept-Encoding: br Accept-Encoding: identity Accept-Encoding: * Accept-Encoding: deflate, gzip;q=1.0, *;q=0.5
上面的几种表述方式就已经把 Accept-Encoding 的属性列全了
gzip: 由文件压缩程序 gzip 生成的编码格式,使用Lempel-Ziv编码(LZ77)和32位CRC的压缩格式,感兴趣的同学可以读一下 (https://en.wikipedia.org/wiki/LZ77_and_LZ78#LZ77)compress: 使用Lempel-Ziv-Welch(LZW)算法的压缩格式,有兴趣的同学可以读 (https://en.wikipedia.org/wiki/LZW)deflate: 使用 zlib 结构和 deflate 压缩算法的压缩格式,参考 (https://en.wikipedia.org/wiki/Zlib) 和 (https://en.wikipedia.org/wiki/DEFLATE)br: 使用 Brotli 算法的压缩格式,参考 (https://en.wikipedia.org/wiki/Brotli)- 不执行压缩或不会变化的默认编码格式
*: 匹配标头中未列出的任何内容编码,如果没有列出Accept-Encoding,这就是默认值,并不意味着支
持任何算法,只是表示没有偏好;q=采用权重 q 值来表示相对优先级,这点与首部字段 Accept 相同。
Content-Type
Content-Type 实体标头用于指示资源的 MIME 类型。作为响应,Content-Type 标头告诉客户端返回的内容的内容类型实际上是什么。Content-type 有两种值 : MIME 类型和字符集编码,例如
Content-Type: text/html; charset=UTF-8
在某些情况下,浏览器将执行 MIME 嗅探,并且不一定遵循此标头的值;为防止此行为,可以将标头 X-Content-Type-Options 设置为 nosniff。
Content-Encoding
Content-Encoding 实体标头用于压缩媒体类型,它让客户端知道如何进行解码操作,从而使客户端获得 Content-Type 标头引用的 MIME 类型。表示如下
Content-Encoding: gzip Content-Encoding: compress Content-Encoding: deflate Content-Encoding: identity Content-Encoding: br Content-Encoding: gzip, identity Content-Encoding: deflate, gzip
Content-Language
Content-Language 实体标头用于描述面向受众的语言,以便使用户根据用户自己的首选语言进行区分。例如
Content-Language: de-DE Content-Language: en-US Content-Language: de-DE, en-CA
下面根据内容协商对应的请求/响应标头,我列了一张图供你参考,注意其中 Accept-Charset 没有对应的 Content-Charset ,而是通过 Content-Type 来表示。

HTTP 认证
HTTP 提供了用于访问控制和身份认证的功能,下面就对 HTTP 的权限和认证功能进行介绍
通用 HTTP 认证框架
RFC 7235 定义了 HTTP 身份认证框架,服务器可以根据其文档的定义来检查客户端请求。客户端也可以根据其文档定义来提供身份验证信息。
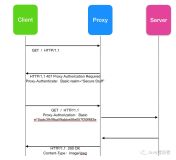
请求/响应的工作流程如下:服务器以401(未授权) 的状态响应客户端告诉客户端服务器需要认证信息,客户端提供至少一个 www-Authenticate 的响应标头进行授权信息的认证。想要通过服务器进行身份认证的客户端可以在请求标头字段中添加认证标头进行身份认证,一般的认证过程如下

首先客户端发起一个 HTTP 请求,不带有任何认证标头,服务器对此 HTTP 请求作出响应,发现此 HTTP 信息未带有认证凭据,服务器通过 www-Authenticate标头返回 401 告诉客户端此请求未通过认证。然后客户端进行用户认证,认证完毕后重新发起 HTTP 请求,这次 HTTP 请求带有用户认证凭据(注意,整个身份认证的过程必须通过 HTTPS 连接保证安全),到达服务器后服务器会检查认证信息,如果不符合服务器认证信息,会返回 403 Forbidden 表示用户认证失败,如果满足认证信息,则返回 200 OK。
我们知道,客户端和服务器之间的 HTTP 连接可以被代理缓存重新发送,所以认证信息也适用于代理服务器。