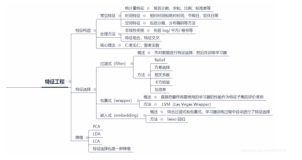
赛题介绍
赛题以医疗数据挖掘为背景,要求选手使用提供的心跳信号传感器数据训练模型并完成不同心跳信号的分类的任务。
赛事地址,目前长期赛已经开放,大家都可以前往报名参与学习:
https://tianchi.aliyun.com/competition/entrance/531883/introduction
赛事数据集解释
该数据来自某平台心电图数据记录,总数据量超过20万,主要为1列心跳信号序列数据,其中每个样本的信号序列采样频次一致,长度相等。数据集均为205维的心跳时序数据。
个人赛题理解
本次赛题实质是时序数据的分类问题。
数据集均为205维的心跳时序数据,且均进行脱敏和归一化处理,进行EDA后,不存在空值。
需要实现自定义评价函数,后处理函数。
医学上将形态学特征作为心电图信号诊断的主要分析依据之一,所以对于发现心电信号的形态学特性尤为重要。这里选择对形态学特征敏感的深度学习神经网络框架,并融合多个模型。
解决方案
自定义评价函数与后处理函数
预测结果与实际心跳类型结果进行对比,求预测的概率与真实值差值的绝对值(越小越好)。根据赛题评测标准,计算得分是心跳信号预测的概率与实际心跳类型结果差值之和,所以可以使用对概率做后处理来降低计算得分。
经测试,后处理函数阈值取值为0.5时,效果最佳。
# 自定义评价函数 def abs_sum(y_pre,y_tru): y_pre=np.array(y_pre) y_tru=np.array(y_tru) loss=sum(sum(abs(y_pre-y_tru))) return loss
# 自定义后处理函数 def postprocessing(test): temp=pd.DataFrame(test) for index, row in temp.iterrows(): row_max = max(list(row)[::]) row_min = min(list(row)[::]) if row_max > 0.5: # 最大值界限 for i in range(4): if row[i] > 0.5: temp.iloc[index,i] = 1 else: temp.iloc[index,i] = 0 elif row_min < 0.5: # 最小值界限 for i in range(4): if row[i] < 0.5: temp.iloc[index,i] = 0 num = np.nonzero(list(temp.iloc[index])) if len(num[0]) == 1: temp.iloc[index,num[0][0]] = 1 return temp
模型构建
为增强模型鲁棒性,选择5折交叉验证;
合理使用Dropout、BatchNormalization、callbacks 防止过拟合,增强预测效果
# 交叉验证分组 —— 5折 folds = 5 seed = 2021 #定义随机种子 kf = KFold(n_splits=folds, shuffle=True, random_state=seed) onehot_encoder = OneHotEncoder(sparse=False) # 用于标签 onehot 编码
CNN模型
# 定义 CNN 模型 def CNN_model(): nclass = 4 inp = Input(shape=(205, 1)) img_1 = Convolution1D(32, kernel_size=5, activation=activations.relu, padding="same")(inp) img_1 = Convolution1D(64, kernel_size=5, activation=activations.relu, padding="same")(img_1) img_1 = Convolution1D(128, kernel_size=5, activation=activations.relu, padding="same")(img_1) img_1 = MaxPool1D(pool_size=2)(img_1) img_1 = Dropout(rate=0.6)(img_1) img_1 = Flatten(name = 'flatten')(img_1) dense_1 = Dense(512, activation=activations.relu, name="dense_1")(img_1) dense_1 = Dense(1024, activation=activations.relu, name="dense_2")(dense_1) dense_1 = Dense(nclass, activation=activations.softmax, name="dense_3_mitbih")(dense_1) model = models.Model(inputs=inp, outputs=dense_1) opt = optimizers.Adam(0.001) model.compile(optimizer=opt, loss=losses.sparse_categorical_crossentropy, metrics=['acc']) # model.summary() return model
# 模型训练 for i, (train_index, valid_index) in enumerate(kf.split(x_train, y_train)): # 模型训练 print('************************************ {} ************************************'.format(str(i+1))) trn_x, trn_y, val_x, val_y = x_train.iloc[train_index], y_train[train_index], x_train.iloc[valid_index], y_train[valid_index] trn_x = np.array(trn_x)[..., np.newaxis] val_x = np.array(val_x)[..., np.newaxis] model_CNN = CNN_model() file_path = "baseline_cnn_datawhale_transfer_fullupdate_" + str(i+1) + ".h5" # 保存每轮训练的最优模型 checkpoint = ModelCheckpoint(file_path, monitor='val_acc', verbose=1, save_best_only=True, mode='max') early = EarlyStopping(monitor="val_acc", mode="max", patience=5, verbose=1) redonplat = ReduceLROnPlateau(monitor="val_acc", mode="max", patience=3, verbose=2) callbacks_list = [checkpoint, early, redonplat] # early model_CNN.load_weights("baseline_cnn_datawhale_1fold.h5", by_name=True) # 加载单折训练模型权重作为网络初始权重 history = model_CNN.fit(trn_x, trn_y, epochs=1000, verbose=2, callbacks=callbacks_list, validation_data=(val_x,val_y)) test_pred_CNN = model_CNN.predict(x_test) test_CNN = copy.deepcopy(test/kf.n_splits)
LSTM模型
# 定义 LSTM 模型 def CuDNNLSTM_model(): nclass = 4 model = models.Sequential() #需要使用 model.add(CuDNNLSTM(32, return_sequences=True, input_shape=(205, 1))) model.add(CuDNNLSTM(64, return_sequences = True)) model.add(CuDNNLSTM(128, return_sequences = True)) model.add(MaxPool1D(pool_size=2)) model.add(Dropout(0.6)) model.add(Flatten()) model.add(Dense(512, activation = 'relu')) model.add(Dense(1024, activation = 'relu')) model.add(Dense(nclass, activation=activations.softmax, name="dense_2_tianchi")) opt = optimizers.Adam(0.001) model.compile(optimizer=opt, loss=losses.sparse_categorical_crossentropy, metrics=['acc']) # model.summary() return model
# 模型训练 for i, (train_index, valid_index) in enumerate(kf.split(x_train, y_train)): # 模型训练 print('************************************ {} ************************************'.format(str(i+1))) trn_x, trn_y, val_x, val_y = x_train.iloc[train_index], y_train[train_index], x_train.iloc[valid_index], y_train[valid_index] trn_x = np.array(trn_x)[..., np.newaxis] val_x = np.array(val_x)[..., np.newaxis] model_CuDNNLSTM = CuDNNLSTM_model() file_path = "baseline_CuDNNLSTM_datawhale_transfer_fullupdate_" + str(i+1) + ".h5" # 保存每轮训练的最优模型 checkpoint = ModelCheckpoint(file_path, monitor='val_acc', verbose=1, save_best_only=True, mode='max') early = EarlyStopping(monitor="val_acc", mode="max", patience=5, verbose=1) redonplat = ReduceLROnPlateau(monitor="val_acc", mode="max", patience=3, verbose=2) callbacks_list = [checkpoint, early, redonplat] # early model_CuDNNLSTM.load_weights("baseline_CuDNNLSTM_datawhale_1fold.h5", by_name=True) # 加载单折训练模型权重作为网络初始权重 history = model_CuDNNLSTM.fit(trn_x, trn_y, epochs=1000, verbose=2, callbacks=callbacks_list, validation_data=(val_x,val_y)) test_pred_CuDNNLSTM = model_CuDNNLSTM.predict(x_test) test_CuDNNLSTM = copy.deepcopy(test/kf.n_splits)
ResNet50 模型
# 定义ResNet50 基本块 Identity Block:加深网络 def identity_block(input_tensor, kernel_size, filters, stage, block): filters1, filters2, filters3 = filters conv_name_base = 'res' + str(stage) + block + '_branch' bn_name_base = 'bn' + str(stage) + block + '_branch' # 降维 x = Convolution1D(filters1, 1, name=conv_name_base + '2a')(input_tensor) x = BatchNormalization(name=bn_name_base + '2a')(x) x = Activation('relu')(x) # 3*3卷积 x = Convolution1D(filters2, kernel_size,padding='same', name=conv_name_base + '2b')(x) x = BatchNormalization(name=bn_name_base + '2b')(x) x = Activation('relu')(x) # 升维 x = Convolution1D(filters3, 1, name=conv_name_base + '2c')(x) x = BatchNormalization(name=bn_name_base + '2c')(x) x = layers.add([x, input_tensor]) x = Activation('relu')(x) return x
# 定义ResNet50 基本块 Conv Block:改变网络的维度 def conv_block(input_tensor, kernel_size, filters, stage, block, strides=2): filters1, filters2, filters3 = filters conv_name_base = 'res' + str(stage) + block + '_branch' bn_name_base = 'bn' + str(stage) + block + '_branch' # 降维 x = Convolution1D(filters1, 1, strides=strides, name=conv_name_base + '2a')(input_tensor) x = BatchNormalization(name=bn_name_base + '2a')(x) x = Activation('relu')(x) # 3*3卷积 x = Convolution1D(filters2, kernel_size, padding='same', name=conv_name_base + '2b')(x) x = BatchNormalization(name=bn_name_base + '2b')(x) x = Activation('relu')(x) # 升维 x = Convolution1D(filters3, 1, name=conv_name_base + '2c')(x) x = BatchNormalization(name=bn_name_base + '2c')(x) # 残差边 shortcut = Convolution1D(filters3, 1, strides=strides, name=conv_name_base + '1')(input_tensor) shortcut = BatchNormalization(name=bn_name_base + '1')(shortcut) x = layers.add([x, shortcut]) x = Activation('relu')(x) return x
# 定义 ResNet50 模型 def ResNet50_model(input_shape=[205, 1],classes=4): img_input = Input(shape=input_shape) x = ZeroPadding1D(3)(img_input) x = Convolution1D(64, 7, strides=2, name='conv1')(x) # [102, 64] x = BatchNormalization(name='bn_conv1')(x) x = Activation('relu')(x) x = MaxPool1D(3, strides=2)(x) # [51, 64] # [51, 256] x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=1) x = identity_block(x, 3, [64, 64, 256], stage=2, block='b') x = identity_block(x, 3, [64, 64, 256], stage=2, block='c') # [25, 512] x = conv_block(x, 3, [128, 128, 512], stage=3, block='a') x = identity_block(x, 3, [128, 128, 512], stage=3, block='b') x = identity_block(x, 3, [128, 128, 512], stage=3, block='c') x = identity_block(x, 3, [128, 128, 512], stage=3, block='d') # [12, 1024] x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a') x = identity_block(x, 3, [256, 256, 1024], stage=4, block='b') x = identity_block(x, 3, [256, 256, 1024], stage=4, block='c') x = identity_block(x, 3, [256, 256, 1024], stage=4, block='d') x = identity_block(x, 3, [256, 256, 1024], stage=4, block='e') x = identity_block(x, 3, [256, 256, 1024], stage=4, block='f') # [6, 2048] x = conv_block(x, 3, [512, 512, 2048], stage=5, block='a') x = identity_block(x, 3, [512, 512, 2048], stage=5, block='b') x = identity_block(x, 3, [512, 512, 2048], stage=5, block='c') # 代替全连接层 x = AveragePooling1D(6, name='avg_pool')(x) # 进行预测 x = Flatten()(x) x = Dense(classes, activation='softmax', name='fc1000')(x) model = models.Model(img_input, x, name='resnet50') opt = optimizers.Adam(0.001) model.compile(optimizer=opt, loss=losses.sparse_categorical_crossentropy, metrics=['acc']) return model
for i, (train_index, valid_index) in enumerate(kf.split(x_train, y_train)): # if i in range(2): continue # 模型训练 print('************************************ {} ************************************'.format(str(i+1))) trn_x, trn_y, val_x, val_y = x_train.iloc[train_index], y_train[train_index], x_train.iloc[valid_index], y_train[valid_index] trn_x = np.array(trn_x)[..., np.newaxis] val_x = np.array(val_x)[..., np.newaxis] model_ResNet50 = ResNet50_model() file_path = "baseline_ResNet50_datawhale_transfer_fullupdate_" + str(i+1) + ".h5" # 保存每轮训练的最优模型 checkpoint = ModelCheckpoint(file_path, monitor='val_acc', verbose=1, save_best_only=True, mode='max') early = EarlyStopping(monitor="val_acc", mode="max", patience=5, verbose=1) redonplat = ReduceLROnPlateau(monitor="val_acc", mode="max", patience=3, verbose=2) callbacks_list = [checkpoint, early, redonplat] # early model_ResNet50.load_weights("baseline_ResNet50_datawhale_1fold.h5", by_name=True) # 加载单折训练模型权重作为网络初始权重 history = model_ResNet50.fit(trn_x, trn_y, epochs=1000, verbose=2, callbacks=callbacks_list, validation_data=(val_x,val_y)) test_pred_ResNet50 = model_ResNet50.predict(x_test) test_ResNet50 = copy.deepcopy(test/kf.n_splits)
模型融合
这里使用了简单的均值加权融合
temp_CNN = copy.deepcopy(test_CNN) temp_CuDNNLSTM = copy.deepcopy(test_CuDNNLSTM) temp_ResNet50 = copy.deepcopy(test_ResNet50) w = [1/3, 1/3, 1/3] test_pre = Weighted_method(temp_CNN, temp_CuDNNLSTM, temp_ResNet50, w) temp = postprocessing(test_pre)
不足
- EDA分析不够
- 未为对数据样本类别不均衡问题进行处理
- 单模型参数优化工作不够
- 模型融合太过简单
- ...
参赛感受和建议
第一次参加,还存在很多的不足之处,对于某些深度学习框架运用还不够熟练,有待提高。但是比赛还是收获颇丰。
比赛初期:学习Datawhale与天池联合推出的相关教学方案,跟着baseline的思路走,试了一下常见的树模型,XGBoost、LightGBM、Catboost,效果不是很理想,score在400到500之间,排行榜都进不了,当时100名为380.实话说,当时心态很差,继续调整。
比赛中期:尝试使用普通的神经网络方法,增加预测数据后处理函数,score能达到400到450之间,但依然上不了榜,甚至模型还存在过拟合现象。最后转移思路,寻找合适的深度学习方法,经过多种尝试选择了3种深度学习神经网络模型:CNN,LSTM,ResNet50。score达到300左右。顺利进入榜单中下区域。
比赛后期:针对三种单模型进行参数设置手动调优,对预测结果后处理函数进行手动阈值调优,最后选择均值加权融合,最后再A榜达到200分作用的成绩,于B榜得到226分的成绩,庆幸模型鲁棒性较好。
限于时间等相关原因,模型还存在很多不足。
通过此次比赛,收获颇丰,希望参加比赛的小伙伴们,不要因为模型结果不理想而轻易放弃,结合数据本身特征进行思考,也许换一个思路,豁然开朗,船到桥头自然直。最后感谢主办方给我们大家提供这么好,这么优秀的学习交流平台。


关注阿里云天池,人人都可以玩转大数据