本文介绍PolarDB-X的SQL执行器如何执行 SQL中无法下推的部分。
基本概念
SQL执行器是PolarDB-X中执行逻辑层算子的组件。对于简单的点查SQL,往往可以整体下推存储层MySQL执行,因而感觉不到执行器的存在,MySQL的结果经过简单的解包封包又被回传给用户。但是对于较复杂的SQL,往往无法将SQL中的算子全部下推,这时候就需要PolarDB-X执行器执行无法下推的计算。
例如,对于如下查询SQL:
SELECT l_orderkey, sum(l_extendedprice *(1 - l_discount)) AS revenue FROM CUSTOMER, ORDERS, LINEITEM WHERE c_mktsegment = 'AUTOMOBILE' and c_custkey = o_custkey and l_orderkey = o_orderkey and o_orderdate < '1995-03-13' and l_shipdate > '1995-03-13' GROUP BY l_orderkey;
通过EXPLAIN命令看到PolarDB-X的执行计划如下:
HashAgg(group="l_orderkey", revenue="SUM(*)") HashJoin(condition="o_custkey = c_custkey", type="inner") Gather(concurrent=true) LogicalView(tables="ORDERS_[0-7],LINEITEM_[0-7]", shardCount=8, sql="SELECT `ORDERS`.`o_custkey`, `LINEITEM`.`l_orderkey`, (`LINEITEM`.`l_extendedprice` * (? - `LINEITEM`.`l_discount`)) AS `x` FROM `ORDERS` AS `ORDERS` INNER JOIN `LINEITEM` AS `LINEITEM` ON (((`ORDERS`.`o_orderkey` = `LINEITEM`.`l_orderkey`) AND (`ORDERS`.`o_orderdate` < ?)) AND (`LINEITEM`.`l_shipdate` > ?))") Gather(concurrent=true) LogicalView(tables="CUSTOMER_[0-7]", shardCount=8, sql="SELECT `c_custkey` FROM `CUSTOMER` AS `CUSTOMER` WHERE (`c_mktsegment` = ?)")
如下图所示,LogicalView的SQL在执行时被下发给MySQL,而不能下推的部分(除LogicalView以外的算子)由PolarDB-X执行器进行计算,得到最终用户SQL需要的结果。

Volcano执行模型
PolarDB-X和很多数据库一样采用Volcano执行模型。所有算子都定义了open()、next()等接口,算子根据执行计划组合成一棵算子树,上层算子通过调用下层算子的next()接口的取出结果,完成该算子的计算。最终顶层算子产生用户需要的结果并返回给客户端。
下面的例子中,假设HashJoin算子已经完成构建哈希表。当上层的Project算子请求数据时,HashJoin首先向下层Gather请求一批数据,然后查表得到JOIN结果,再返回给Project算子。

某些情况下,算子需要将数据全部读取并缓存在内存中,该过程被称为物化,例如,HashJoin算子需要读取内表的全部数据,并在内存中构建出哈希表。其他类似的算子还有HashAgg(聚合)、MemSort(排序)等。
由于内存资源是有限的,如果物化的数据量超出单条查询限制,或者使用的总内存超出PolarDB-X节点内存限制,将会引起内存不足(OUT_OF_MEMORY)报错。
并行查询
并行查询(Parallel Query) 指利用多线程并行执行用户的复杂查询。
说明 该功能仅在PolarDB-X标准版及企业版上提供,入门版由于硬件规格限制,不提供该项功能。
并行查询的执行计划相比原来有所改动。例如,还是以上面的查询为例,它的并行执行计划如下所示:
Gather(parallel=true) ParallelHashAgg(group="o_orderdate,o_shippriority,l_orderkey", revenue="SUM(*)") ParallelHashJoin(condition="o_custkey = c_custkey", type="inner") LogicalView(tables="ORDERS_[0-7],LINEITEM_[0-7]", shardCount=8, sql="SELECT `ORDERS`.`o_custkey`, `ORDERS`.`o_orderdate`, `ORDERS`.`o_shippriority`, `LINEITEM`.`l_orderkey`, (`LINEITEM`.`l_extendedprice` * (? - `LINEITEM`.`l_discount`)) AS `x` FROM `ORDERS` AS `ORDERS` INNER JOIN `LINEITEM` AS `LINEITEM` ON (((`ORDERS`.`o_orderkey` = `LINEITEM`.`l_orderkey`) AND (`ORDERS`.`o_orderdate` < ?)) AND (`LINEITEM`.`l_shipdate` > ?))", parallel=true) LogicalView(tables="CUSTOMER_[0-7]", shardCount=8, sql="SELECT `c_custkey` FROM `CUSTOMER` AS `CUSTOMER` WHERE (`c_mktsegment` = ?)", parallel=true)

可以看出,并行执行计划中Gather算子的位置被拉高了,这也意味者Gather下方的算子都会以并行方式执行,直到Gather时才被汇总成在一起。
执行时,Gather下方的算子会实例化出多个执行实例,分别对应一个并行度。并行度默认等于单台机器的核心数,标准版实例默认并行度为8,企业版实例默认并行度为16。
执行过程的诊断分析
除了上文提到的EXPLAIN指令,还有如下几个指令能帮助分析性能问题:
EXPLAIN ANALYZE指令用于分析PolarDB-X Server中各算子执行的性能指标。EXPLAIN EXECUTE指令用于输出MySQL的EXPLAIN结果(并汇总输出)。
如下是以上文提到的查询为例,介绍如何分析一条查询的性能问题。
执行EXPLAIN ANALYZE得到如下结果(删除了一些无关的信息):
explain analyze select l_orderkey, sum(l_extendedprice *(1 - l_discount)) as revenue from CUSTOMER, ORDERS, LINEITEM where c_mktsegment = 'AUTOMOBILE' and c_custkey = o_custkey and l_orderkey = o_orderkey and o_orderdate < '1995-03-13' and l_shipdate > '1995-03-13' group by l_orderkey; HashAgg(group="o_orderdate,o_shippriority,l_orderkey", revenue="SUM(*)") ... actual time = 23.916 + 0.000, actual rowcount = 11479, actual memory = 1048576, instances = 1 ... HashJoin(condition="o_custkey = c_custkey", type="inner") ... actual time = 0.290 + 23.584, actual rowcount = 30266, actual memory = 1048576, instances = 1 ... Gather(concurrent=true) ... actual time = 0.000 + 23.556, actual rowcount = 151186, actual memory = 0, instances = 1 ... LogicalView(tables="ORDERS_[0-7],LINEITEM_[0-7]", shardCount=8, sql="SELECT `ORDERS`.`o_custkey`, `ORDERS`.`o_orderdate`, `ORDERS`.`o_shippriority`, `LINEITEM`.`l_orderkey`, (`LINEITEM`.`l_extendedprice` * (? - `LINEITEM`.`l_discount`)) AS `x` FROM `ORDERS` AS `ORDERS` INNER JOIN `LINEITEM` AS `LINEITEM` ON (((`ORDERS`.`o_orderkey` = `LINEITEM`.`l_orderkey`) AND (`ORDERS`.`o_orderdate` < ?)) AND (`LINEITEM`.`l_shipdate` > ?))") ... actual time = 0.000 + 23.556, actual rowcount = 151186, actual memory = 0, instances = 4 ... Gather(concurrent=true) ... actual time = 0.000 + 0.282, actual rowcount = 29752, actual memory = 0, instances = 1 ... LogicalView(tables="CUSTOMER_[0-7]", shardCount=8, sql="SELECT `c_custkey` FROM `CUSTOMER` AS `CUSTOMER` WHERE (`c_mktsegment` = ?)") ... actual time = 0.000 + 0.282, actual rowcount = 29752, actual memory = 0, instances = 4 ...
其中:
- actual time表示实际执行耗时(其中包含子算子的耗时),加号(+)左边表示open(准备数据)耗时,右边表示next(输出数据)耗时。
- actual rowcount表示输出的行数。
- actual memory表示算子使用的内存空间大小(单位为Bytes)。
- instances表示实例数,非并行查询时始终为1,对于并行算子每个并行度对应一个实例。如果实例数不等于1,actual time,actual rowcount,actual memory代表多个实例并行执行的总实际执行耗时、总输出行数、总内存使用量。
说明 当使用并行查询时,上述的算子耗时、输出行数等信息均为算子多个实例的累加。例如actual time = 20,instances = 8,表示该算子有8个实例并行执行,平均耗时为2.5s。
以上面的输出为例,解读如下:
- HashAgg算子open耗时为23.916s,用于获取下层HashJoin的输出、并对输出的所有数据做分组和聚合。其中的23.601s都用在了获取了下层输出上,只有约0.3s用于分组聚合。
- HashJoin算子open耗时0.290s,用于拉取右表(下方的Gather)数据并构建哈希表;next耗时23.584s,用于拉取左表数据以及查询哈希表得到JOIN结果。
- Gather算子仅仅用于汇总多个结果集,通常代价很低。
- 左侧(上方)的LogicalView拉取数据消耗了23.556s,可判断这里是查询的性能瓶颈。
- 右侧(下方)的LogicalView拉取数据消耗了0.282s。
综上,性能瓶颈在左边的LogicalView上。从执行计划中可以看到,它是对ORDERS、LINEITEM的JOIN查询,这条查询MySQL执行速度较慢。
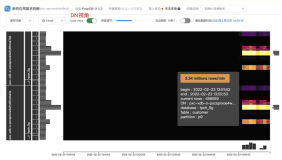
您可以通过如下EXPLAIN EXECUTE语句查看MySQL EXPLAIN结果:

上图中,红色方框对应左边的LogicalView的下推查询,蓝色方框对应右边LogicalView的下推查询。