竹翁,OceanBase 内核研发总监
杨志丰,花名竹翁,毕业于北京大学,长期从事分布式系统和数据库的研发工作,现于阿里巴巴/蚂蚁金服自主研发的分布式关系数据库 OceanBase 团队负责研发工作,致力于把设计先进的 HTAP 数据库系统打造成技术业内标杆的核心基础设施。在 OceanBase 系统中,他先后负责研究 OceanBase 的 SQL 引擎、分布式主控模块、多模数据库方向以及 OceanBase 的数据库平台产品研发,并于近期开始负责内核创新研发工作。竹翁对 C++、分布式系统原理、SQL 查询处理、事务处理、编译技术、工程效率等方面具有深入的理解。
引言
源码是OceanBase的“方向盘”,本系列主要围绕“源码解读”,通过文章阐述,帮助大家理清数据库的内在本质。带你读源码第一篇《戳这里回顾:OceanBase数据库源码解读之模块结构》为大家介绍了OceanBase数据库的整体架构,旨在帮助大家快速厘清OceanBase的模块构成以及各模块的功能。
本文为 OceanBase 数据库源码解读系列文章的第二篇,将主要为大家介绍 OceanBase 数据库中一条 SQL 的执行流程主路径,包括接收、处理、返回结果给客户端的过程,与开发者们一起探讨OceanBase的SQL引擎模块。
正文

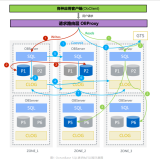
可以看到,在src/observer 目录下,内含三个子目录。其中,omt 中的 mt 表示multi-tenant,内部实现了 observer 线程模型的抽象 worker,每个租户在其有租户的节点上会创建一个线程池用于处理 SQL 请求。virtual_table 目录下是 sys 租户各个 __all_virtual 虚拟表的实现,“虚拟表”其实是 一种view,它把一些内存数据结构抽象成表接口暴露出来,用于诊断调试等。MySQL 目录则是 MySQL 协议层,实现了 MySQL 5. 6兼容的消息处理协议。

除了建立和断开连接,MySQL 协议大多是简单的请求响应模型。每种请求类似一个 COM_XXX 命令,每种命令的处理函数对应本目录一个相应的类,见下图。

比如最常用的COM _QUERY 表示一条SQL 请求,处理类位于 obmp_query.h/cpp 中。一般典型的交互过程是 connect、query、query... query、quit。
值得注意的是,所有的 SQL 语句类型,包括 DML、DDL 以及multi-statement 都是用 query 进行命令处理。
建立连接的过程在 obmp_connect,它执行用户认证鉴权,如果鉴权成功,系统则会创建一个 ObSQLSession 对象(位于 src/sql/session),用于表示唯一一个数据库的连接,所有其他命令处理都会访问该 session 对象。

上图是 query 的处理类ObMPQuery,它是一条 SQL一生的开始,process 方法为其指引入口。
Mpquery会在其入口的地方将类TraceId初始化。TraceId是一个工具类,放置于线程局部变量中,SQL语句在后续处理过程中所涉及的所有模块都可以全局访问。它是一条 SQL 一次处理过程的一个唯一标识,如果执行过程中切换了线程,或者执行了 RPC,都会带上TraceId。在 oblog 打印的所有调试日志中,都包含一个以 Y 开头的十六进制串(猜猜为什么以 Y 开头),这就是 TraceId,它可以把不同位置打印的日志串起来。OceanBase 研发同学查问题时都习惯 grep 到 TraceId 相关的所有日志。
如果一条 SQL 串的格式是stmt;stmt;,即 multi-statement,其表示的是 MySQL 协议的一种特殊优化,可以一次发送多条语句执行,并返回多个结果集(如果有的情况下)。根据SQL是否为多语句,observer会有不同的处理。如果是一个 autocommit=1 的 DML 单语句,由于系统要执行事务提交写日志,待执行完成才能响应客户端。为了尽快让出线程资源,observer会挂起相关上下文,在日志提交成功之后执行回调。这里一些特殊的代码逻辑就是在处理这个优化。
对于多语句的处理,首先ObParser通过一个快速解析入口 split_multiple_stmt 把每条语句拆分出来,再对每条语句进行process_single_stmt。事务控制逻辑我们可以暂时不做考虑,最后 通过do_process,observer进入了 SQL 模块。

一般而言,SQL 的模块划分非常清晰。总入口是 sql/ob_sql.h/cpp 的 ObSql 类。do_process 会调用这个类的 stmt_query 方法:输入 SQL 语句字符串,输出一个包含物理执行计划和元信息的 ResultSet。外层打开并迭代结果集,把每一行结果发送给客户端。所以,协议和执行计划处理本身是“流式”的,并不需要查询到全部结果才返回客户端。
SQL子模块
接下来我们再来看看 SQL 的子模块。parser 模块执行语法分析,把 SQL 字符串解析为一个 ParseNode 组成的抽象语法树。其接口类是 ObParser 类。parser 是由 bison 和flex 生成的 C 语言代码,OceanBase 的 C 语言代码就位于这里。parser 有一种快速解析模式,目标不是产生语法树,而是把 SQL 字符串参数化,具体原理我们将在后续的系列中进行详细的解释。

parser解析之后就交给了resolver。因为抽象语法树没有 SQL 语义,所以resolver 对它进行分析,结合数据字典元信息(OceanBase 的代码叫 schema 模块),赋予其 SQL 语义。大部分语义报错就是在这个阶段产生的,比如“表已经存在”,“主键长度超过限制”等。resolver 模块的接口类是ObResolver,它的输出是 ObStmt。这个模块是面向对象设计的,每种语句类型有一个 Resolver 和一个 Stmt。按照语句类型,分别位于不同的子目录,如dml、ddl、tcl 等。
对于非 SELECT 和 DML 之外的语句,如大多数 DDL 语句解析到这里便可以执行了。这类简单语句类型统称为“命令”,由 engine/cmd 目录下的 executor 直接执行。DDL 是通过 rootservice(RS)进行执行,所以其 executor 实际是发送 RPC,事务控制语句则在本机直接调用事务层。
对于 SELECT 和 DML 及带数据操作的 DDL,则需要产生执行计划。优化器(sql/optimizer)的接口类是 ObOptimizer,以上一步生成的 ObDMLStmt(含 SELECT)为输入,执行基于代价的优化,生成一个逻辑执行计划(ObLogPlan)。逻辑执行计划是由 OceanBase 的关系运算算子 ObLogicalOperator 组成的树状结构,改写(sql/rewrite)是优化器的一部分,执行等价的关系运算改写,产生潜在更好的执行计划候选。这里会涉及到一系列改写规则,改写规则的入口类是 ObTransformerImpl,输入输出都是 ObDMLStmt。
接下来,code_generator(cg) 模块负责把逻辑执行计划转换为能够高效执行的物理执行计划。它的接口类是 ObCodeGenerator,其中,比较复杂的是表达式的生成过程。engine 目录下是 SQL 执行引擎,也叫做物理执行计划(ObPhysicalPlan),它是由物理算子(ObPhyOperator)组成的树状结构,执行过程是一种火山模型的流水线。
同一个物理执行计划可以被多个线程并行执行,上一步cg 产生的物理执行计划一般会被保存到计划缓存(即 sql/plan_cache 目录)中。前文提及的parser 有一种特殊的快速解析模式,快速解析后的 SQL 会被尝试从计划缓存中直接“捞”可用的物理执行计划。如果没有合适的计划,observer才会执行上文所述的从 resolver 到 cg 的“硬解析”流程。
SQL 的一生很长,在这篇文章中,我们仅仅只是带大家粗略的走了个 “闭环”,在后续的源码解读第三篇我们将会带大家了解OceanBase的存储层,为大家讲透分区的一生,敬请期待。
如果您有任何疑问,可以通过以下方式与我们进行交流:
微信群:扫码添加小助手,将拉你进群哟~

github:https://github.com/oceanbase/oceanbase