背景知识
Linux层面
linux对于文件的读取,提供了不同的函数,引用资料如下:
当对同一文件句柄(在Windows下)或是文件描述符(在Linux下)进行随机读写操作时,会存在文件指针的定位与读/写俩个步骤,但由于这不是一个原子操作,就可能产生如下问题:进程A对某文件先定位到 f1 处,然后被中断,然后进程B对同一文件定位到 f2 处,然后被中断,进程A再次执行,从文件的当前指针处开始读或是写,于是这便产生了不是期望的结果了。(这里要注意,对同一文件的俩次打开,得到的将是俩个不同的句柄或是描述符,所以不用担心这种情况会出问题)
解决办法:
在Linux下,pread函数就好像是专门为上面的问题服务的,它本身就是原子性的操作,定位文件指针与读操作一气呵成,而且读操作并不改变文件指针。
总体来说,常用的有seek()+read() 和 pread()这2种方式,优劣如下:
seek()+read()非线程安全,但由于利用了文件描述符所保存的文件指针,不需要每次读取时都去定位,因此读取效率较高,应用层面多线程访问时则需要做同步;
pread()是原子操作,线程安全,但由于每次都需要定位文件指针,所以读取效率较低;
Hdfs层面
hdfs基于linux的不同函数,提供了不同的实现,对应issue如下(https://issues.apache.org/jira/browse/HADOOP-519):
HDFS File API should be extended to include positional read
HDFS Input streams should support positional read. Positional read (such as the pread syscall on linux) allows reading for a specified offset without affecting the current file offset. Since the underlying file state is not touched, pread can be used efficiently in multi-threaded programs.
Here is how I plan to implement it.
Provide PositionedReadable interface, with the following methods:
int read(long position, byte[] buffer, int offset, int length);
void readFully(long position, byte[] buffer, int offset, int length);
void readFully(long position, byte[] buffer);Abstract class FSInputStream would provide default implementation of the above methods using getPos(), seek() and read() methods. The default implementation is inefficient in multi-threaded programs since it locks the object while seeking, reading, and restoring to old state.
DFSClient.DFSInputStream, which extends FSInputStream will provide an efficient non-synchronized implementation for above calls.
In addition, FSDataInputStream, which is a wrapper around FSInputStream, will provide wrapper methods for above read methods as well.
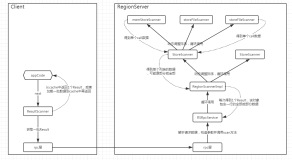
HBase中的应用
HBase中,定义了2种不同的ReadType:PREAD和STREAM,分别代表pread()和seek()+read():
@InterfaceAudience.Public
public enum ReadType {
DEFAULT, STREAM, PREAD
}读取hfile需要通过scanner,而创建StoreFileScanner的时候,会根据ReadType进入到不同的流程:
for (int i = 0, n = files.size(); i < n; i++) {
HStoreFile sf = sortedFiles.remove();
StoreFileScanner scanner;
if (usePread) {
scanner = sf.getPreadScanner(cacheBlocks, readPt, i, canOptimizeForNonNullColumn);
} else {
scanner = sf.getStreamScanner(canUseDrop, cacheBlocks, isCompaction, readPt, i,
canOptimizeForNonNullColumn);
}
scanners.add(scanner);
}其中,getPreadScanner会直接返回共享的reader对象,即底层共享同一个inputStream:
/**
* Get a scanner which uses pread.
* <p>
* Must be called after initReader.
*/
public StoreFileScanner getPreadScanner(boolean cacheBlocks, long readPt, long scannerOrder,
boolean canOptimizeForNonNullColumn) {
return getReader().getStoreFileScanner(cacheBlocks, true, false, readPt, scannerOrder,
canOptimizeForNonNullColumn);
}
/**
* @return Current reader. Must call initReader first else returns null.
* @see #initReader()
*/
public StoreFileReader getReader() {
return this.reader;
}而getStreamScanner会创建一个新的reader,在fileInfo.open方法中,会打开一个新的inputStream,然后读取hfile中相关元数据信息,如果启用了preFetchOnOpen也会触发读取数据块:
/**
* Get a scanner which uses streaming read.
* <p>
* Must be called after initReader.
*/
public StoreFileScanner getStreamScanner(boolean canUseDropBehind, boolean cacheBlocks,
boolean isCompaction, long readPt, long scannerOrder, boolean canOptimizeForNonNullColumn)
throws IOException {
return createStreamReader(canUseDropBehind).getStoreFileScanner(cacheBlocks, false,
isCompaction, readPt, scannerOrder, canOptimizeForNonNullColumn);
}
private StoreFileReader createStreamReader(boolean canUseDropBehind) throws IOException {
initReader();
StoreFileReader reader = fileInfo.open(this.fs, this.cacheConf, canUseDropBehind, -1L,
primaryReplica, refCount, false);
reader.copyFields(this.reader);
return reader;
} /**
* Open a Reader for the StoreFile
* @param fs The current file system to use.
* @param cacheConf The cache configuration and block cache reference.
* @return The StoreFile.Reader for the file
*/
public StoreFileReader open(FileSystem fs, CacheConfig cacheConf, boolean canUseDropBehind,
long readahead, boolean isPrimaryReplicaStoreFile, AtomicInteger refCount, boolean shared)
throws IOException {
FSDataInputStreamWrapper in;
FileStatus status;
final boolean doDropBehind = canUseDropBehind && cacheConf.shouldDropBehindCompaction();
if (this.link != null) {
// HFileLink
in = new FSDataInputStreamWrapper(fs, this.link, doDropBehind, readahead);
status = this.link.getFileStatus(fs);
} else if (this.reference != null) {
// HFile Reference
Path referencePath = getReferredToFile(this.getPath());
in = new FSDataInputStreamWrapper(fs, referencePath, doDropBehind, readahead);
status = fs.getFileStatus(referencePath);
} else {
in = new FSDataInputStreamWrapper(fs, this.getPath(), doDropBehind, readahead);
status = fs.getFileStatus(initialPath);
}
long length = status.getLen();
hdfsBlocksDistribution = computeHDFSBlocksDistribution(fs);
StoreFileReader reader = null;
if (this.coprocessorHost != null) {
reader = this.coprocessorHost.preStoreFileReaderOpen(fs, this.getPath(), in, length,
cacheConf, reference);
}
if (reader == null) {
if (this.reference != null) {
reader = new HalfStoreFileReader(fs, this.getPath(), in, length, cacheConf, reference,
isPrimaryReplicaStoreFile, refCount, shared, conf);
} else {
reader = new StoreFileReader(fs, status.getPath(), in, length, cacheConf,
isPrimaryReplicaStoreFile, refCount, shared, conf);
}
}
if (this.coprocessorHost != null) {
reader = this.coprocessorHost.postStoreFileReaderOpen(fs, this.getPath(), in, length,
cacheConf, reference, reader);
}
return reader;
}这里有2个疑问
1:共享reader是哪里来的
在open region或者由于flush和bulkload产生新的hfile时,都会open hfile,此时会创建一个reader进行元数据读取,此reader即为共享reader,其shared属性被设置为true;
StoreFileReader.java
// indicate that whether this StoreFileReader is shared, i.e., used for pread. If not, we will
// close the internal reader when readCompleted is called.
@VisibleForTesting
final boolean shared;2:pread和stream分别什么时候使用
默认情况下,get请求使用pread,compact scan使用stream;
对于user scan,则有以下规则:
- 如果客户端明确指定readType,则直接使用
- 如果客户端未指定,则服务端会以pread方式开始,读取超过4个blocksize大小数据时,切换为stream方式,该阈值通过hbase.storescanner.pread.max.bytes进行配置
- 如果不希望服务端进行上述切换,而固定使用pread,可将hbase.storescanner.use.pread配置为true
另外,在读取完成,关闭scanner时,会调用readCompleted方法,该方法会判断shared来决定是否关闭所使用的reader:
StoreFileScanner.java
@Override
public void close() {
if (closed) return;
cur = null;
this.hfs.close();
if (this.reader != null) {
this.reader.readCompleted();
}
closed = true;
}
StoreFileReader.java
/**
* Indicate that the scanner has finished reading with this reader. We need to decrement the ref
* count, and also, if this is not the common pread reader, we should close it.
*/
void readCompleted() {
refCount.decrementAndGet();
if (!shared) {
try {
reader.close(false);
} catch (IOException e) {
LOG.warn("failed to close stream reader", e);
}
}
}问题和优化
以上为2.0版本中的代码,其中有个很明显的问题,就是很多scan都重复执行了fileInfo.open方法,而该方法包含的逻辑过多,造成了很多不必要的读取,影响了scan性能且浪费系统资源,社区较新的版本对此处进行了优化,相关的issue为https://issues.apache.org/jira/browse/HBASE-22888;