本讲义出自Frank Zhao、Fenghao Zhang与 Yusong Lv在Hadoop Summit Tokyo 2016上的演讲,主要介绍了分布式流系统的相关概念,可靠性处理、Apache Storm的解决方案以及面对的挑战、新提出的方法以及 Apache Storm的原型和基准。





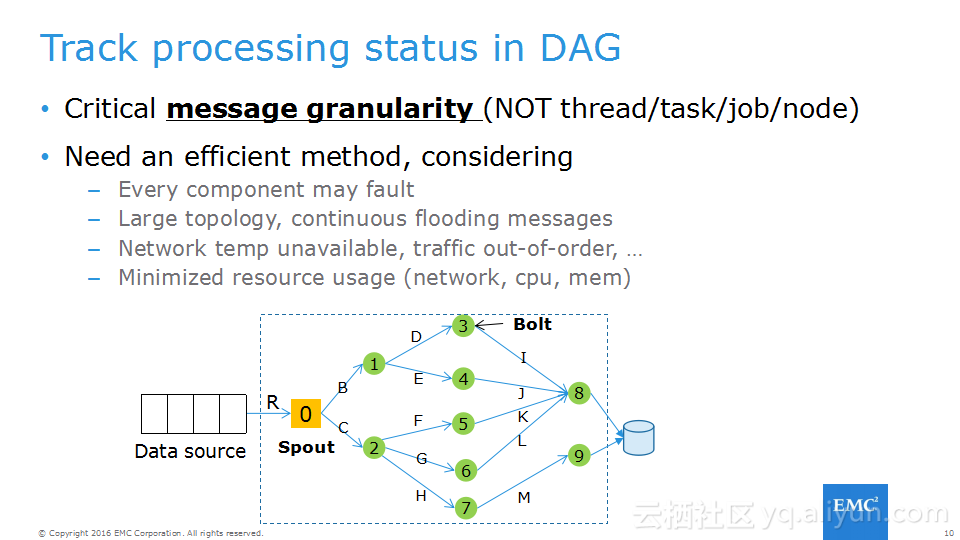

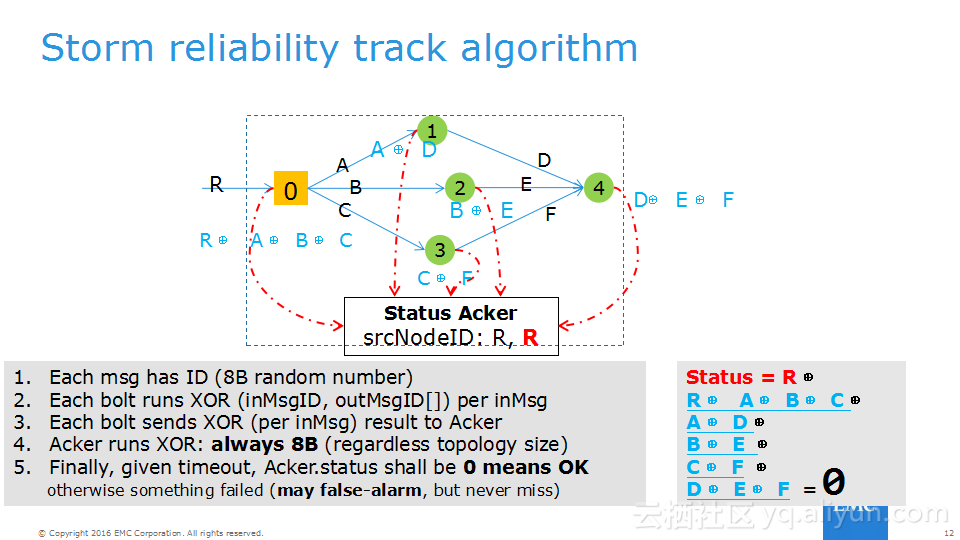

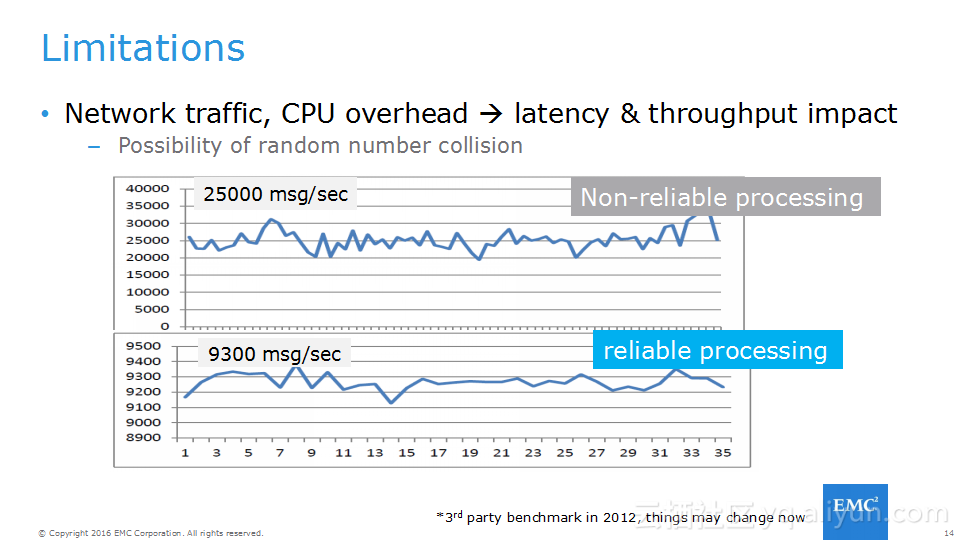
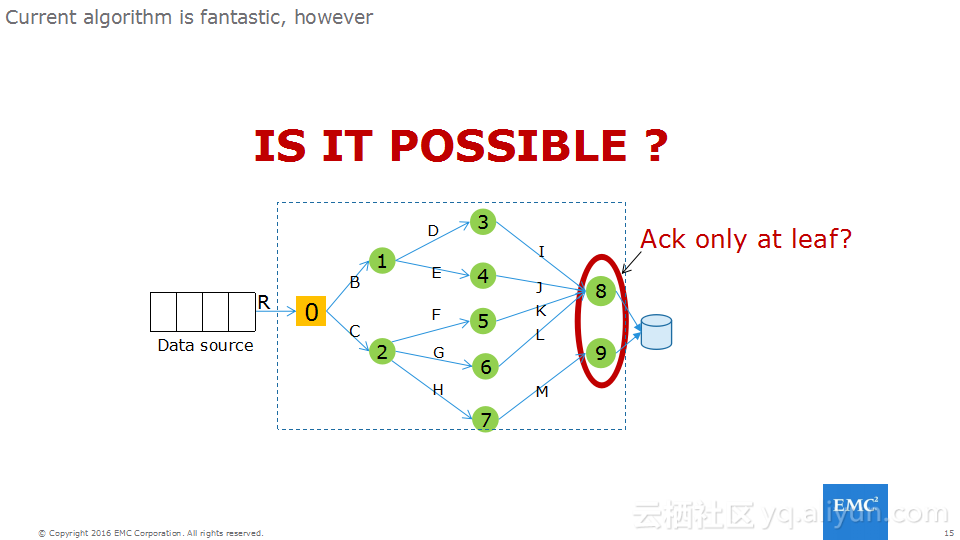

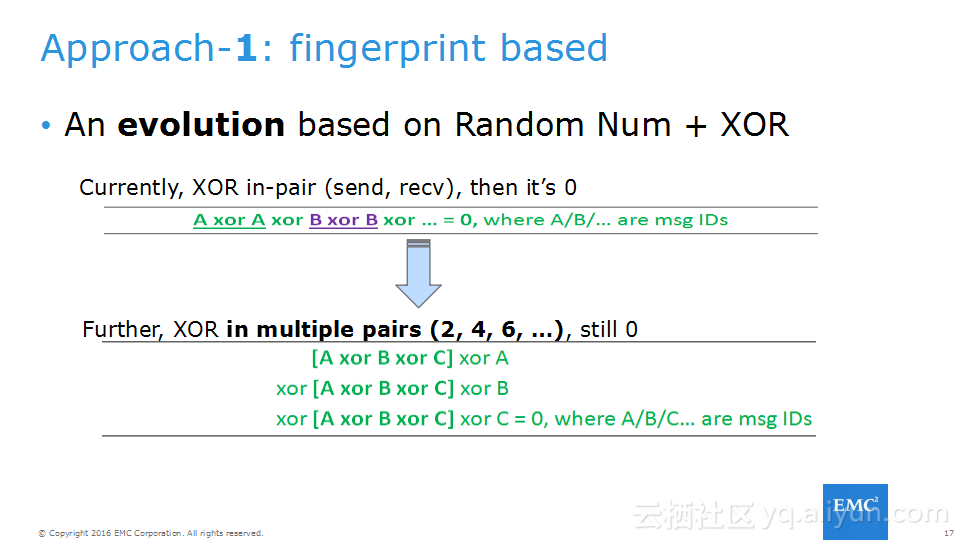
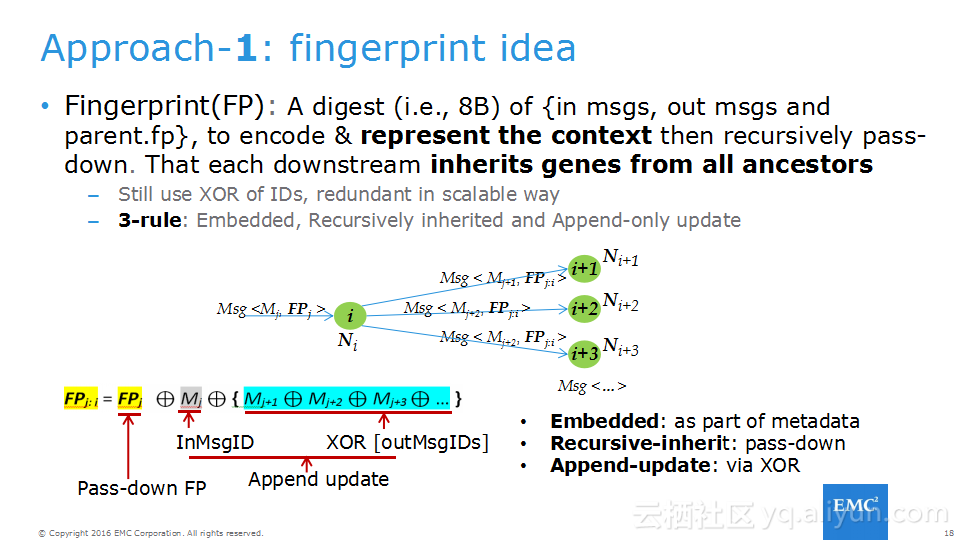

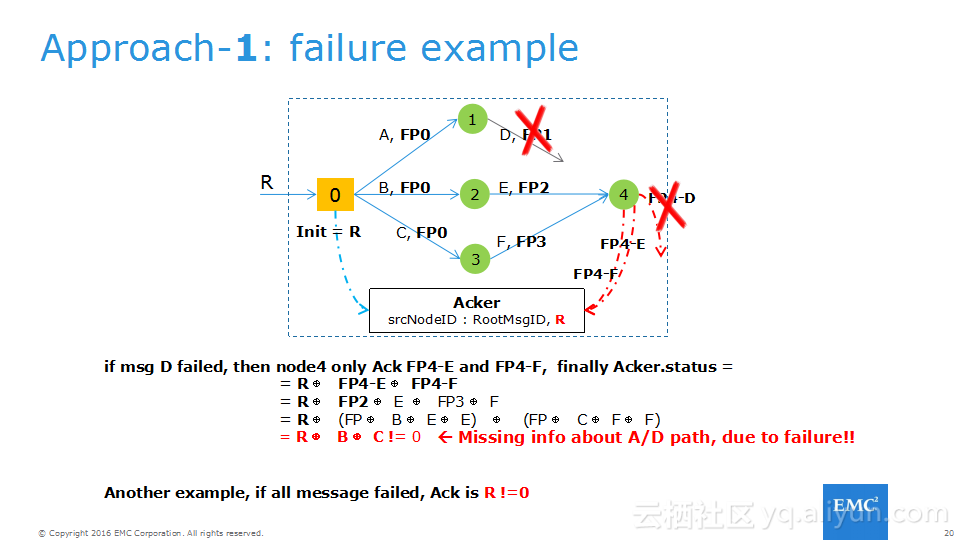
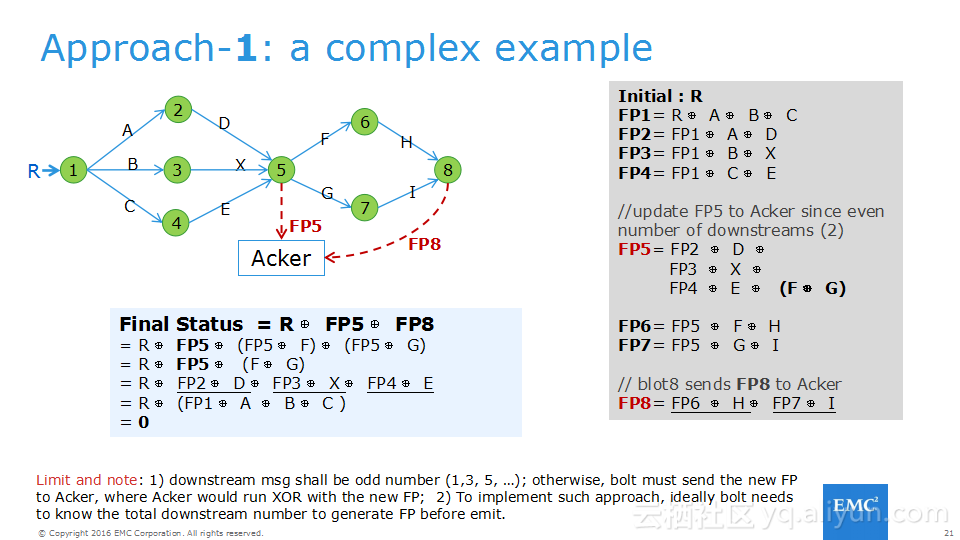
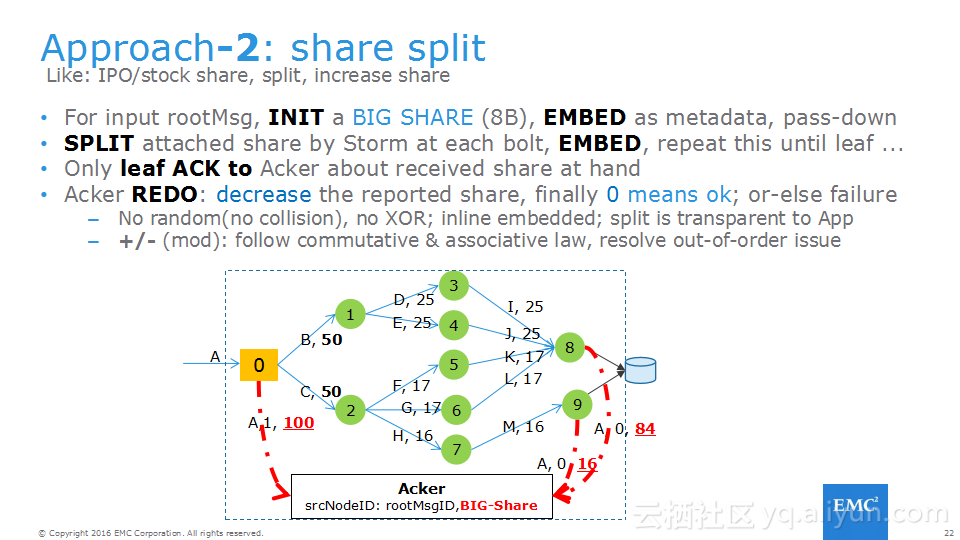
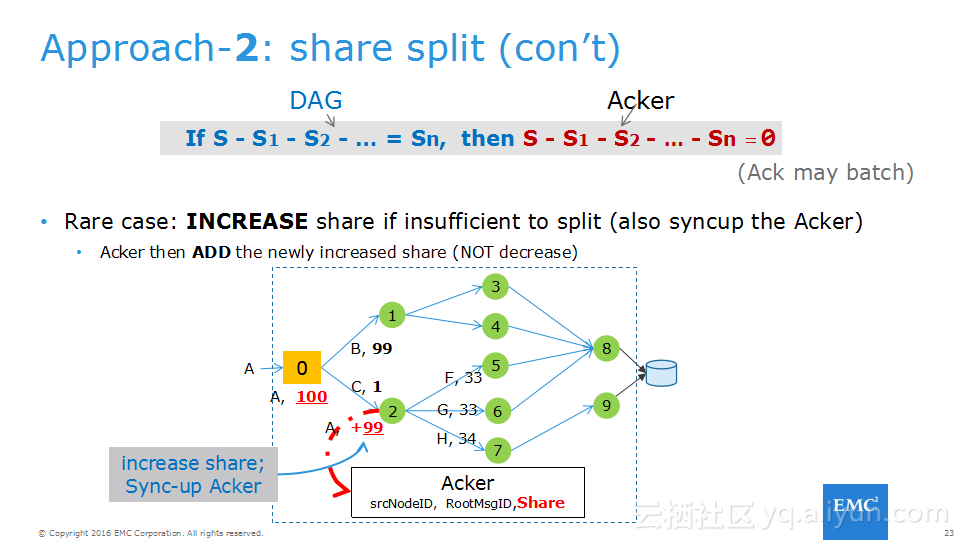


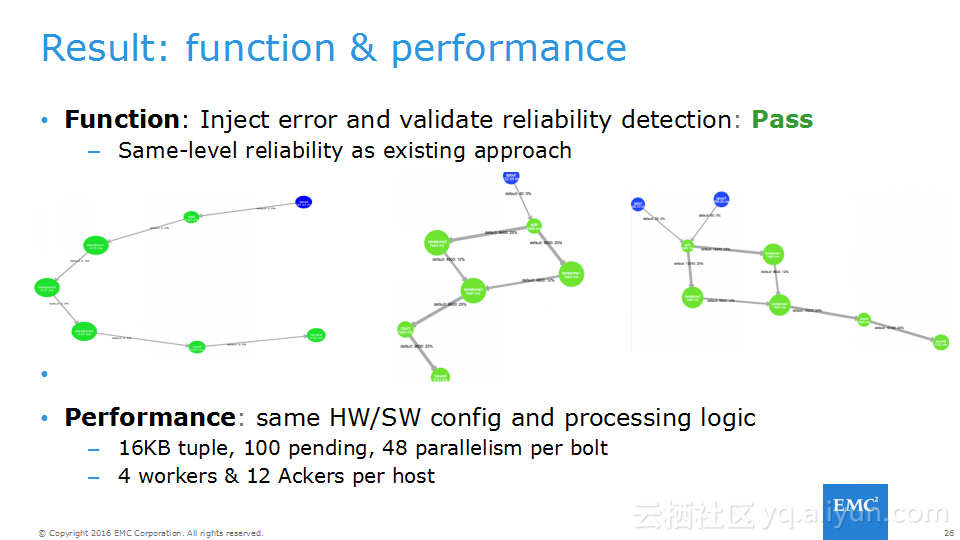
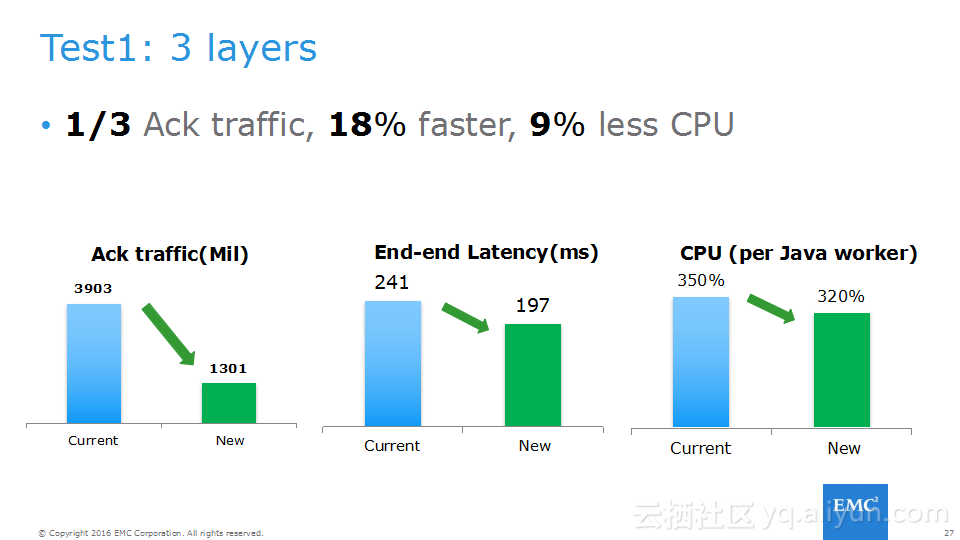
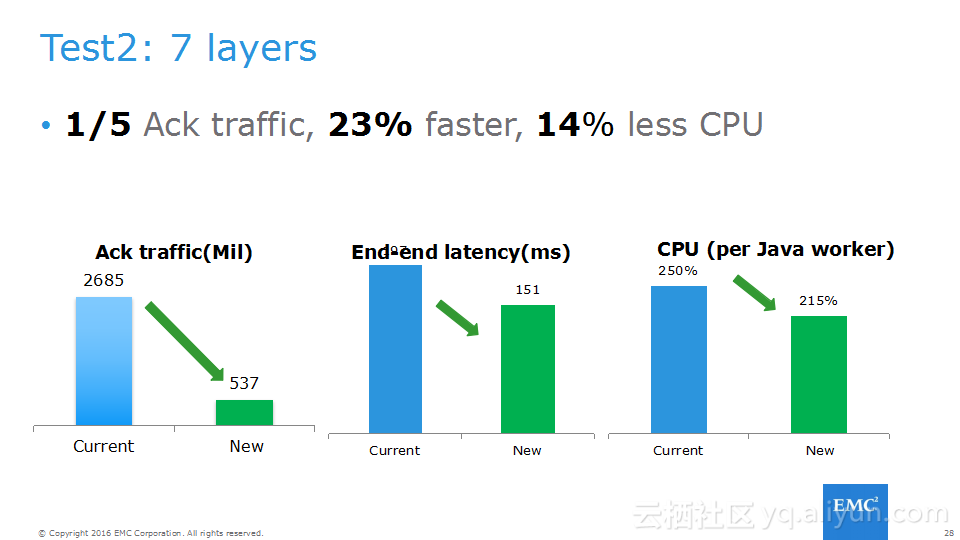

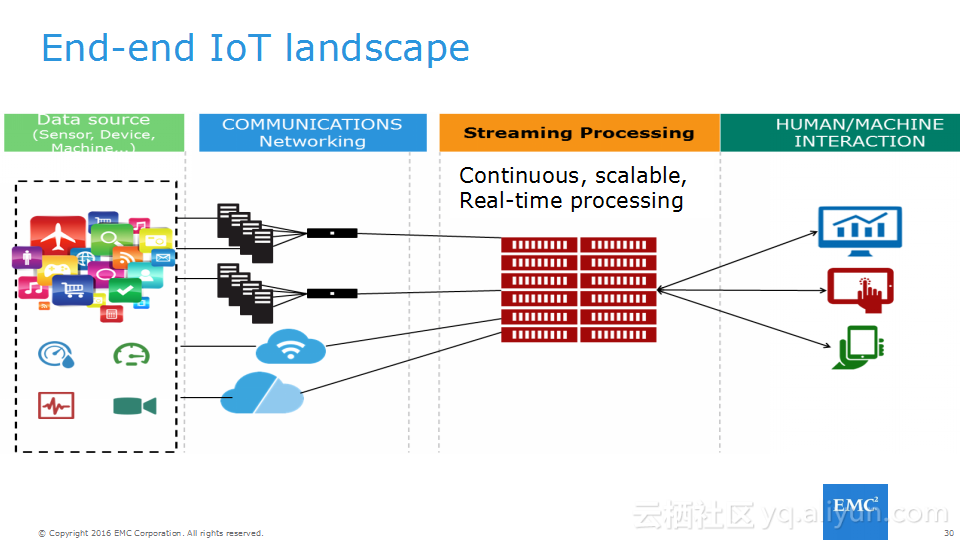
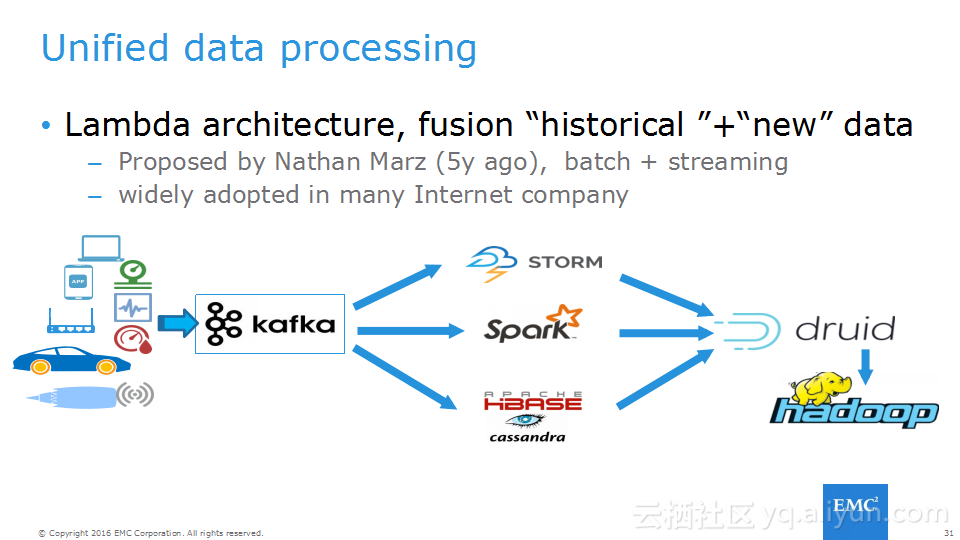



本讲义出自Frank Zhao、Fenghao Zhang与 Yusong Lv在Hadoop Summit Tokyo 2016上的演讲,主要介绍了分布式流系统的相关概念,可靠性处理、Apache Storm的解决方案以及面对的挑战、新提出的方法以及 Apache Storm的原型和基准。
