更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
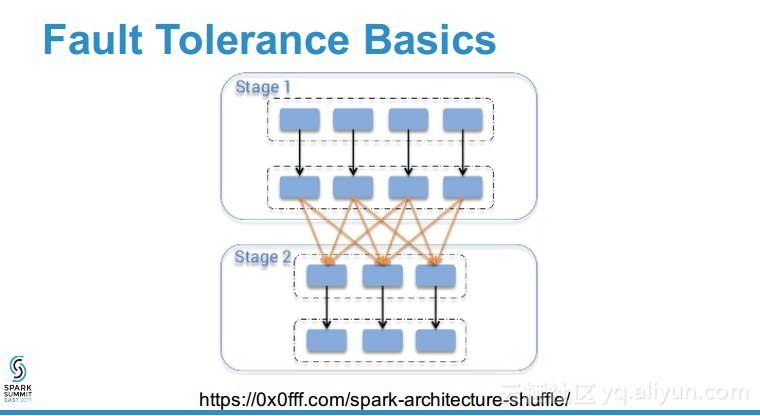
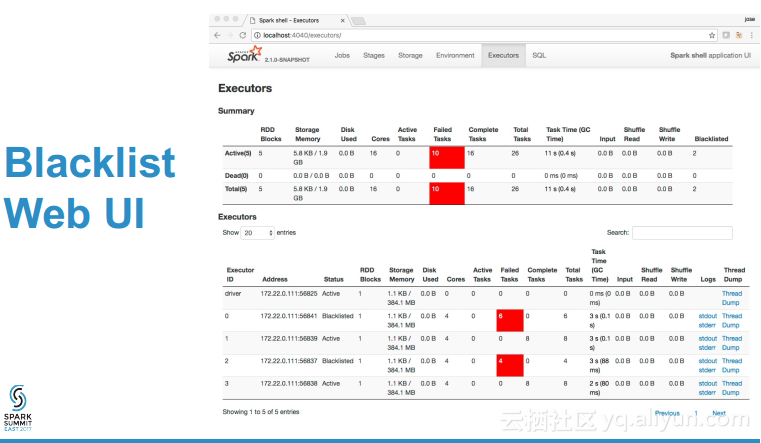
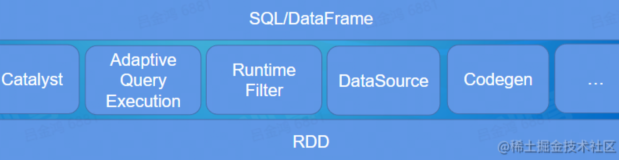
本讲义出自Jose Soltren在Spark Summit East 2017上的演讲,主要介绍了Spark容错中的螺母和螺栓,他首先简述了Spark中的各种容错机制,然后讨论了YARN上的Spark、调度与资源分配,在演讲中还对于一些用户案例进行了探讨研究并给出了一些需要的工具,最后分享了未来Spark中容错未来的发展方向比如调度器和检查点的变化。