我是标题党【doge】······
最近在看SVM算法的原理,之前只知道用,但是对理论推导并不是很明白,这次算是复习一下,加深理解。
从感知机说起
要深入理解SVM,首先要从感知机说起。
什么是感知机呢?
感知机(perceptron)是二类分类的线性分类模型。
假设输入空间为χ⊆Rnχ⊆Rn,输出空间是y=−1,+1y=−1,+1.由输入空间到输出空间的如下函数f(x)=sign(ω⋅x+b)f(x)=sign(ω⋅x+b)称为感知机。
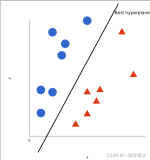
也就是说,我的ωω参数和bb参数,确定了一个分离超平面,将训练数据集划分为两个部分,分别为正类和负类。因此,我们需要知道ωω和b的值,确定这个超平面,那么来了一个新的数据,通过计算和这个超平面的距离,就知道它属于哪个类别了。
因此,我们的任务就变成了求ωω和bb的值是什么,从而确定分离超平面。
在这里,我们有一个前提条件,就是数据集是线性可分的。
那么如何求这两个参数呢?我们需要确定一个学习策略,即定义经验损失函数并将其极小化。也就是我们常说的loss.
在感知机中,我们选择的loss为误分类点到超平面的总距离,让这个总距离最小,这就是我们的优化目标。特征空间中任意一点x0x0到超平面的距离为:
对于误分类的数据 (xi,yi)(xi,yi)来说, yi(ω⋅x+b)<0yi(ω⋅x+b)<0.因此,误分类点到分类超平面的距离就是 −1∥ω∥yi|ω⋅x+b|−1‖ω‖yi|ω⋅x+b|
因此,所有误分类点到分类超平面的距离就是:
由于 1∥ω∥1‖ω‖为常数,因此不考虑它。于是,我们得到了感知机的损失函数:
且该损失函数关于 ωω和b连续可导。
有了学习策略,也就是我们的经验函数,接下来就是学习算法了。我们将学习问题转化为了优化问题,解决方法就是随机梯度下降(SGD),这里不展开说了。
对于感知机,学习算法有原始形式和对偶形式。
- 原始形式:
- 选取ω0,b0ω0,b0的初值,可以随机给。
- 在训练集中选取数据(xi,yi)(xi,yi)
- 如果yi(ωxi+b)<0yi(ωxi+b)<0(说明被分错了):
ω←ω+ηyixiω←ω+ηyixib←b+ηyib←b+ηyi - 回到2,直至没有错分的点。
- 对偶形式
对偶形式的基本想法是,将ωω和b 表示为实例xixi和label yiyi的线性组合形式,通过求解其系数,求得ωω和b。
按照上面的参数更新过程,我们设初始值都为0,那么经过n次迭代以后,ωω和b关于(xi,yi)(xi,yi)的增量为αiyixiαiyixi和αiyiαiyi,其中αiηαiη。因此,最后学习到的参数值分别可以表示为:
ω=∑i=1Nαiyixiω=∑i=1Nαiyixib=∑i=1Nαiyib=∑i=1Nαiyi
基于此,感知机的模型就可以表示为f(x)=sign(∑Nj=1αjyjxj⋅x+b)f(x)=sign(∑j=1Nαjyjxj⋅x+b)
实例点更新的次数越多,意味着它与分离超平面越近,越不好分。也就是说,这样的实例对学习的结果影响最大。
那么,对偶形式就可以如下表示了:
1. 参数为αα,b,赋初值为0.
2. 在训练集中选取数据(xi,yi)(xi,yi)
3. 如果(∑Nj=1αjyjxj⋅x+b)<=0(∑j=1Nαjyjxj⋅x+b)<=0:
4. 转2,直到没有误分类的点。
对偶形式中,训练集仅以内积的形式出现,为了方便,可以预先算出来存储下来,这个矩阵就是Gram矩阵
总结
- 首先,感知机应用场景为,数据集是线性可分的,这是前提。
- 感知机的经验损失函数为误分类点到分离超平面的距离和,让这个距离和达到最小。
- 感知机学习得到的分离超平面并不唯一,有无穷多解。解由于初值不同或者迭代顺序不同而可能有所不同。
- 学习算法为随机梯度下降.有原始形式和对偶形式。