阿里云EMR(Elastic MapReduce)是一项 Web 服务,简化了大数据处理,提供的大数据框架可以让您轻松、高速、经济、安全、稳定地处理大数据,满足如日志分析、数据仓库、商业智能、机器学习、科学模拟等业务需求。
一. 最佳实践
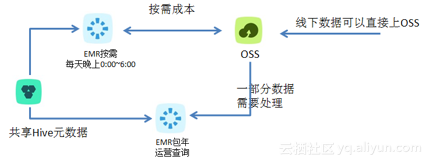
1. 混合使用包年及按需计费,节约成本
数据都存在热、冷的差异。一般建议把冷数据存放在OSS中,热数据放在本地HDFS中。晚上00:00-06:00按需运行,运行完成后释放集群,节约成本。晚上ECS水位低,比较容易申请到大集群。
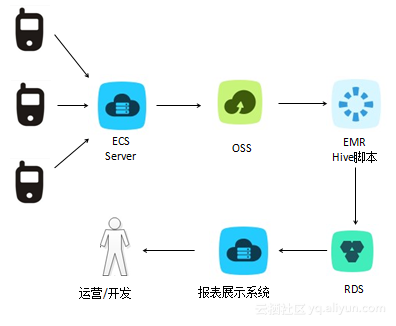
服务端会把这些信息存储在OSS中,再启动E-MapReduce中的Hive脚本分析这些数据,如:统计pv和uv,再把每个链接的访问情况存储在RDS中,最后通过报表系统展示。
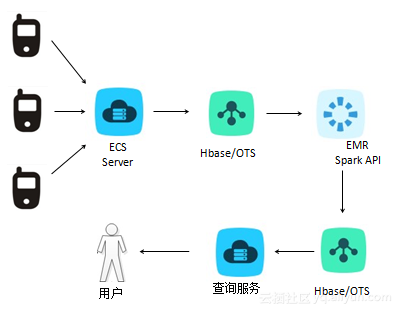
3. 离线处理+在线服务进行多维度信息统计
比如考虑到这样的一个场景,车载APP会实时上传汽车的物理指标,包括车速、发动机功耗、电池电压等,这些信息首先存储到EMR Hbase中,再启用E-MapReduce的hive或者mapreduce或者spark离线分析,按照城市的粒度,即分析出来某个城市某个时段的车辆出行率、出行里程平均数、车速平均值、平均油耗、出行车辆数、平均怠速时间、剧烈驾驶次数,这些信息又存放到Hbase中做成服务。
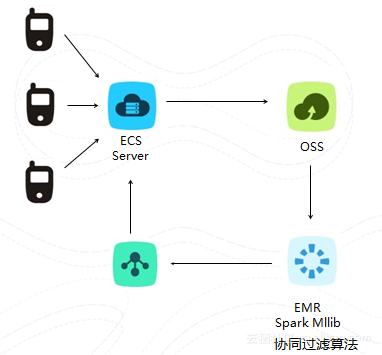
4. 离线处理-推荐(机器学习)
用户会对视频发生点赞、喜欢、收藏、分享、观看等行为,将用户对某个视频产生同一行为的用户进行关联分析建模。然后当某个用户看了某个视频,而相关联的好友用户没有看过该视频的话,就会在该用户观看视频播放器的下方进行推荐。整个过程用了协同过滤算法。主要是spark mllib分析oss中用户的日志,存放在rds中。
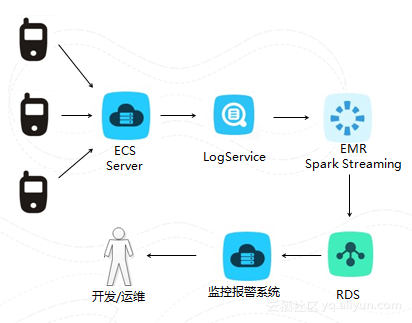
5. 实时处理-监控报警
统计数据从多个维度来展现当前服务质量,例如各种请求状态码占比,请求接口占比,每种请求的状态码占比,请求延时分布,每种请求的时延占比。最终结果可以呈现给运维人员或者开发人员,用来进一步保证服务质量和优化服务性能。如果出现一些异常情况,则报警给运维人员或者开发人员。主要的架构就是使用了spark streaming接受logservice实时推送过来的日志,分析完成后,实时存放到rds中,出现问题时监控报警系统会触发报警。
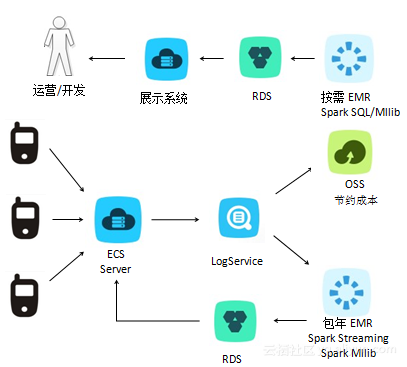
6. 在线离线混合
例如一个有用户浏览的网站,日志信息用logService接收。一方面存入到OSS中,晚上启动E-MapReduce离线分析,比如,页面的UV、从A页面到B页面的调转,提供运营同学数据化支持。另一方面,用户在不断浏览过程中,我们希望根据浏览情况实时自动推荐用户内容,E-MapReduce spark Streaming就实时接收 logService的数据,再结合spark mllib的算法,自动算出推荐内容,存储到RDS中,前端用户浏览时推荐的内容会实时发生变化。
二. 容灾设计
1. 数据容灾
Hadoop分布式文件系统(HDFS)将每一个文件的数据进行分块存储,同时每一个数据块又保存有多个副本(系统默认为每一个数据块存放3个副本),尽量保证这些数据块副本分布在不同的机架之上(在大多数情况下,副本系数是3,HDFS的存放策略是将一个副本存放在本地机架节点上,一个副本存放在同一个机架的另一个节点上,最后一个副本放在不同机架的节点上)。
HDFS会定期扫描数据副本,若发现数据副本发生丢失,则会快速的进行数据的复制以保证副本的数量。若发现节点丢失,则节点上的所有数据也会快速的进行复制恢复。在阿里云上,如果是使用云盘的技术,则在后台每一个云盘都会对应三个数据副本,当其中的任何一个出现问题时,副本数据都会自动进行切换并恢复,以保证数据的可靠性。
Hadoop HDFS是一个经历了长时间考验且具有高可靠性的数据存储系统,已经能够实现海量数据的高可靠性存储。同时基于云上的特性,也可以在OSS等服务上进行数据的额外备份,来达到更高的数据可靠性。
2. 服务容灾
Hadoop的核心组件都会进行HA的部署,即有至少2个节点的服务互备,如YARN,HDFS,Hive Server,Hive Meta,以保证在任何时候,其中任何一个服务节点挂掉时,当前的服务节点都能自动的进行切换,保证服务不会受到影响。

