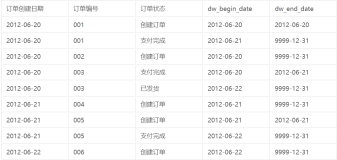
公司要出一报表,计算某月数据,并按周数据的累加计算出月的数据,这里周的划分是自己规定,比如5.3号属于4月的18周,不是5月的周,格式类似这样
model cd,流通类型code,客户类型code,總重點賣場數,week19%,week19
因此在根据周的累加和统计月的数据方法如下
SELECT /*+ FULL(T1) FULL(T2) USE_HASH(T1) */
T1.BASE_YW
,T_LOCL.BRNC_ID
,MAX(T_LOCL.BRNC_NM) BRNC_ID_NM
,T_LOCL.OFFC_ID
,MAX(T_LOCL.OFFC_NM) OFFC_ID_NM
,T1.SHOP_ID
,T_MODL.MKT_MODL_ID
,T_MODL.BASC_MODL
,T_CHNL.BI_CHNL_TP_02
,MAX(T_BI_CHNL_TP_02.CODE_NM) BI_CHNL_TP_02_NM
,T_CHNL.BI_CHNL_TP_03
,MAX(T_BI_CHNL_TP_03.CODE_NM) BI_CHNL_TP_03_NM
,SUM(PSI_VAL) PSI_VAL
,MAX(T_YW.YW_RNK) YW_RNK
FROM MCS_BI.DM_BI_TPS_SHOP_01_YW T1 --对应规定周
,T_MODL --对应自然月
/*一 周和自然月的第一周关联 这里是5.3号统计数据
5.3号在规定周里是18周最后一天 4.27-5.3
在自然月里是5月第一周,前三天 5.1-5.3
这两个时间段数据连接,能取出5.1-5.3的数据
二 5.8号在规定周里是19周 5.3-5.10
在自然月里是5月第一周 5.1-5.8
这两个时间段数据连接,能取出5.3-5.8的数据
因此计算19周数据可以先算出19周数据 从5.3开始的数据,然后计算18周的数据截至到5.3号的数据,这样数据就完整连接上了 */
,T_SHOP
,T_LOCL
,T_REGN
,T_CHNL
,T_YW
,MCS_HQ.CD_CODE_LIST T_BI_CHNL_TP_02
,MCS_HQ.CD_CODE_LIST T_BI_CHNL_TP_03
WHERE T1.BASE_YW >= (SELECT MIN(A.BASE_YW) FROM MCS_HQ.MA_BASE_YW A WHERE A.WEEK_YM = '201504')
AND T1.BASE_YW AND T_YW.BASE_YW = T1.BASE_YW
AND T1.BI_CHNL_PSI_TP = 'I3F' --or SOF
AND T1.SHOP_ID = T_SHOP.SHOP_ID
AND T_MODL.MODL_CD = T1.MODL_CD
AND T_SHOP.CITY_ID = T_REGN.CITY_ID
AND T_SHOP.OFFC_ID = T_LOCL.OFFC_ID
AND T_CHNL.CHNL_ID(+) = T_SHOP.SUPP_CHNL_ID
AND T_BI_CHNL_TP_02.CODE_DIV(+) = 'BI_CHNL_TP_02'
AND T_BI_CHNL_TP_02.LANG_CD(+) = 'CN'
AND T_BI_CHNL_TP_02.CODE_CD(+) = T_CHNL.BI_CHNL_TP_02
AND T_BI_CHNL_TP_03.CODE_DIV(+) = 'BI_CHNL_TP_03'
AND T_BI_CHNL_TP_03.LANG_CD(+) = 'CN'
AND T_BI_CHNL_TP_03.CODE_CD(+) = T_CHNL.BI_CHNL_TP_03
GROUP BY T1.BASE_YW
,T_LOCL.BRNC_ID
,T_LOCL.OFFC_ID
,T1.SHOP_ID
,T_MODL.MKT_MODL_ID
,T_MODL.BASC_MODL
,T_CHNL.BI_CHNL_TP_02
,T_CHNL.BI_CHNL_TP_03
model cd,流通类型code,客户类型code,總重點賣場數,week19%,week19
因此在根据周的累加和统计月的数据方法如下
SELECT /*+ FULL(T1) FULL(T2) USE_HASH(T1) */
T1.BASE_YW
,T_LOCL.BRNC_ID
,MAX(T_LOCL.BRNC_NM) BRNC_ID_NM
,T_LOCL.OFFC_ID
,MAX(T_LOCL.OFFC_NM) OFFC_ID_NM
,T1.SHOP_ID
,T_MODL.MKT_MODL_ID
,T_MODL.BASC_MODL
,T_CHNL.BI_CHNL_TP_02
,MAX(T_BI_CHNL_TP_02.CODE_NM) BI_CHNL_TP_02_NM
,T_CHNL.BI_CHNL_TP_03
,MAX(T_BI_CHNL_TP_03.CODE_NM) BI_CHNL_TP_03_NM
,SUM(PSI_VAL) PSI_VAL
,MAX(T_YW.YW_RNK) YW_RNK
FROM MCS_BI.DM_BI_TPS_SHOP_01_YW T1 --对应规定周
,T_MODL --对应自然月
/*一 周和自然月的第一周关联 这里是5.3号统计数据
5.3号在规定周里是18周最后一天 4.27-5.3
在自然月里是5月第一周,前三天 5.1-5.3
这两个时间段数据连接,能取出5.1-5.3的数据
二 5.8号在规定周里是19周 5.3-5.10
在自然月里是5月第一周 5.1-5.8
这两个时间段数据连接,能取出5.3-5.8的数据
因此计算19周数据可以先算出19周数据 从5.3开始的数据,然后计算18周的数据截至到5.3号的数据,这样数据就完整连接上了 */
,T_SHOP
,T_LOCL
,T_REGN
,T_CHNL
,T_YW
,MCS_HQ.CD_CODE_LIST T_BI_CHNL_TP_02
,MCS_HQ.CD_CODE_LIST T_BI_CHNL_TP_03
WHERE T1.BASE_YW >= (SELECT MIN(A.BASE_YW) FROM MCS_HQ.MA_BASE_YW A WHERE A.WEEK_YM = '201504')
AND T1.BASE_YW AND T_YW.BASE_YW = T1.BASE_YW
AND T1.BI_CHNL_PSI_TP = 'I3F' --or SOF
AND T1.SHOP_ID = T_SHOP.SHOP_ID
AND T_MODL.MODL_CD = T1.MODL_CD
AND T_SHOP.CITY_ID = T_REGN.CITY_ID
AND T_SHOP.OFFC_ID = T_LOCL.OFFC_ID
AND T_CHNL.CHNL_ID(+) = T_SHOP.SUPP_CHNL_ID
AND T_BI_CHNL_TP_02.CODE_DIV(+) = 'BI_CHNL_TP_02'
AND T_BI_CHNL_TP_02.LANG_CD(+) = 'CN'
AND T_BI_CHNL_TP_02.CODE_CD(+) = T_CHNL.BI_CHNL_TP_02
AND T_BI_CHNL_TP_03.CODE_DIV(+) = 'BI_CHNL_TP_03'
AND T_BI_CHNL_TP_03.LANG_CD(+) = 'CN'
AND T_BI_CHNL_TP_03.CODE_CD(+) = T_CHNL.BI_CHNL_TP_03
GROUP BY T1.BASE_YW
,T_LOCL.BRNC_ID
,T_LOCL.OFFC_ID
,T1.SHOP_ID
,T_MODL.MKT_MODL_ID
,T_MODL.BASC_MODL
,T_CHNL.BI_CHNL_TP_02
,T_CHNL.BI_CHNL_TP_03