YOLO目标检测创新改进与实战案例专栏
专栏目录: YOLO有效改进系列及项目实战目录 包含卷积,主干 注意力,检测头等创新机制 以及 各种目标检测分割项目实战案例
专栏链接: YOLO基础解析+创新改进+实战案例
介绍

摘要
许多有效的解决方案已被提出以减少推理加速中模型的冗余。然而,常见的方法大多集中在消除不重要的滤波器或构建高效的操作上,而忽视了特征图中的模式冗余。我们揭示了在一个层内,许多特征图分享相似但不完全相同的模式。然而,确定具有类似模式的特征是否冗余或包含重要细节是困难的。因此,我们提出了一种基于分割的卷积操作,即SPConv,来容忍具有相似模式但需要较少计算的特征。具体来说,我们将输入的特征图分割成代表性部分和不确定冗余部分,从代表性部分中通过相对复杂的计算提取内在信息,而在不确定冗余部分中处理微小的隐藏细节则采用轻量级操作。为了重新校准和融合这两组处理过的特征,我们提出了一个无需参数的特征融合模块。此外,我们的SPConv设计成可以直接替代原始卷积,在使用中非常便捷。实验结果表明,基准测试中配备SPConv的网络在GPU上在准确性和推理时间上始终优于最先进的基准模型,同时大幅减少了浮点运算和参数量。
文章链接
论文地址:论文地址
代码地址:代码地址
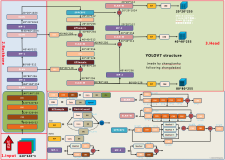
基本原理
在现有的滤波器中,如常规卷积、GhostConv、OctConv和HetConv,通常在所有输入通道上执行 ( k \times k ) 卷积操作。然而,这些方法未能解决同一层特征中存在的冗余问题,即使不存在完全相同的两个通道特征,也难以直接剔除冗余。
受此现象启发,研究者提出了一种新的方法,将所有输入特征按比例分为两部分:
- 代表性部分:执行 $k \times k$ 卷积以提取重要信息;
- 不确定部分:执行 $1 \times 1$ 卷积以补充隐含细节信息。
这种过程可以用以下公式描述:
$$ \text{SPConv} = \text{Representative部分} \oplus \text{Uncertain部分} $$
核心代码
class SPConv_3x3(nn.Module):
def __init__(self, inplanes, outplanes, stride=1, ratio=0.5):
super(SPConv_3x3, self).__init__()
# 计算3x3卷积和1x1卷积的输入输出通道数
self.inplanes_3x3 = int(inplanes * ratio)
self.inplanes_1x1 = inplanes - self.inplanes_3x3
self.outplanes_3x3 = int(outplanes * ratio)
self.outplanes_1x1 = outplanes - self.outplanes_3x3
self.outplanes = outplanes
self.stride = stride
# 定义3x3组卷积和1x1卷积层
self.gwc = nn.Conv2d(self.inplanes_3x3, self.outplanes, kernel_size=3, stride=self.stride,
padding=1, groups=2, bias=False)
self.pwc = nn.Conv2d(self.inplanes_3x3, self.outplanes, kernel_size=1, bias=False)
# 定义1x1卷积层
self.conv1x1 = nn.Conv2d(self.inplanes_1x1, self.outplanes, kernel_size=1)
# 定义平均池化层
self.avgpool_s2_1 = nn.AvgPool2d(kernel_size=2, stride=2)
self.avgpool_s2_3 = nn.AvgPool2d(kernel_size=2, stride=2)
self.avgpool_add_1 = nn.AdaptiveAvgPool2d(1)
self.avgpool_add_3 = nn.AdaptiveAvgPool2d(1)
# 定义批归一化层
self.bn1 = nn.BatchNorm2d(self.outplanes)
self.bn2 = nn.BatchNorm2d(self.outplanes)
self.ratio = ratio
self.groups = int(1 / self.ratio)
task与yaml配置
详见: https://blog.csdn.net/shangyanaf/article/details/140406016