在当前的工作环境中,我主要负责处理和分析大量数据,以及优化数据处理流程。随着业务的发展,我们发现需要更强大的计算资源和更高效的数据处理方案。因此,当听说阿里云推出了EMR Serverless Spark这项全托管的Serverless Spark计算产品时,我非常感兴趣并决定尝试使用它来改进我们的工作流程。
开箱即用
首先,我必须说,注册和设置EMR Serverless Spark服务的过程非常简单直接。阿里云的文档相当详细,让我这个PHP程序员也能轻松上手。通过几次点击,我就创建了我的第一个Spark任务,这给我留下了深刻的第一印象。
环境配置和首秀
在初次使用时,我按照文档指南配置了必要的环境变量和安全设置。由于EMR Serverless Spark支持多种计算模式和扩展性选项,我选择了最适合我们数据规模的资源配置。随后,我尝试运行了一些基本的数据分析脚本,比如数据清洗和用户行为分析,初步感觉它的性能比我们现有的自建Spark集群要好不少。
稳定性与性能测试
为了进一步验证EMR Serverless Spark的稳定性和性能,我设计了一系列的压力测试,包括大规模数据ETL操作和复杂的数据分析任务。结果显示,无论是在数据处理速度还是在高并发条件下的资源消耗方面,EMR Serverless Spark都表现得相当不错。特别是在自动弹性伸缩方面,它能够根据工作负载的变化动态调整资源,大大节省了成本。
开发和调试体验
作为一个PHP开发者,我并不熟悉Java或Scala,但EMR Serverless Spark提供的Python和SQL接口让数据分析变得简单易懂。此外,它还支持Jupyter Notebook,这让我能够交互式地开发和调试我的代码,非常方便。
运维和监控
EMR Serverless Spark的一个亮点是减少了运维负担。不需要维护硬件或软件,也不必担心集群的配置和管理。内置的监控和日志系统让我们可以轻松跟踪任务的运行状态和性能指标,这对于调优和故障排查来说非常有用。
成本评估
在成本方面,EMR Serverless Spark按实际使用计费,这意味着我们只需为实际运行的任务付费。对比传统的自建Spark集群,这种方式在成本上更具可预测性和灵活性。经过一段时间的使用后,我发现总体成本确实比维护一个自建的Spark集群要低。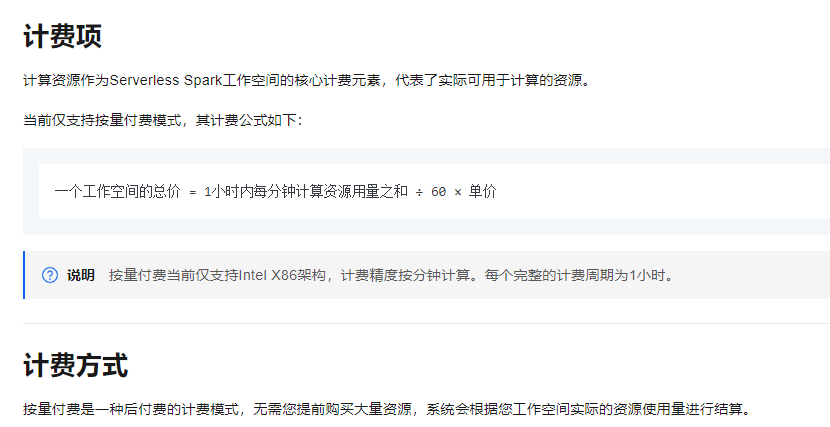
功能满足度
虽然EMR Serverless Spark提供了许多便利的功能,但在使用过程中我也发现了一些可以改进的地方。例如,与第三方数据源的连接可以更加丰富,以满足不同场景下的数据导入需求。此外,对于某些高级的Spark特性,如果能提供更多的文档和示例,将使得非专业的Spark开发者更容易上手。
联动组合可能性
我还尝试了将EMR Serverless Spark与其他阿里云服务结合使用,例如使用Data Lake Analytics进行数据仓库操作,以及使用MaxCompute进行大规模的数据计算。这种联动可以形成更加强大的数据处理解决方案,为我们提供一站式的大数据处理平台。
总结
总体来说,EMR Serverless Spark是一项令人印象深刻的服务。它不仅提供了高性能和稳定的计算能力,还极大地简化了数据处理任务的开发、部署和运维工作。尽管有一些小缺点和改进空间,但我相信随着时间的推移,这项服务将会变得更加成熟和强大。作为一名PHP程序员,我非常享受这次体验,并期待未来能更多地利用EMR Serverless Spark来提升我们的工作效率。



