问题一:Flink CDC 里我设置的这个参数,这个值是否可以超出集群配置去设置呢?
Flink CDC 里我设置的这个参数,启动了大概134个任务会占用270左右的cpu核数,再启动任务就又出现了timeout,这个值是否可以超出集群配置去设置呢? 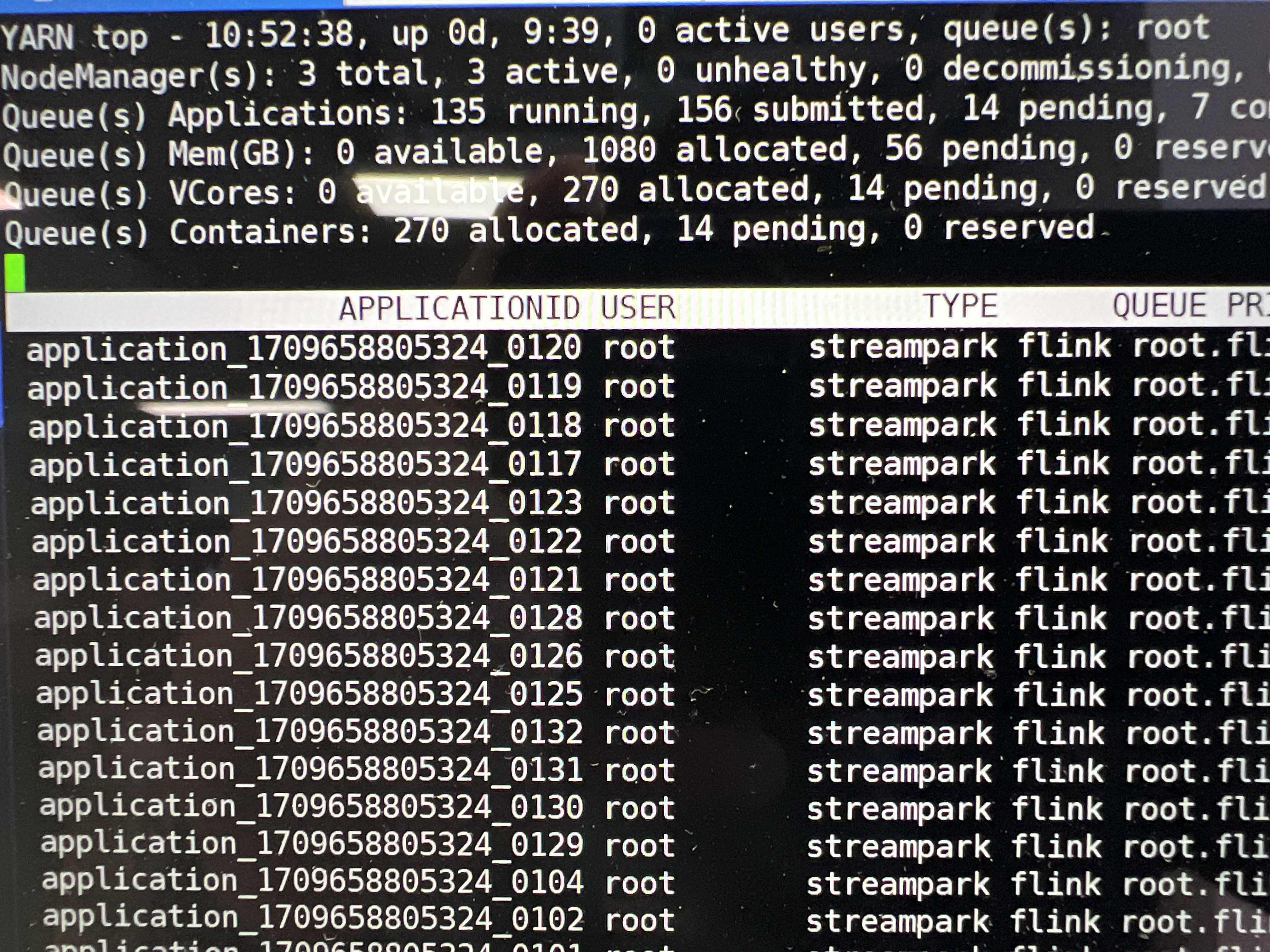
yarn.nodemanager.resource.cpu-vcores
270
cpu
可以通过这个调整物理和虚拟的占比,内存是不是只能压缩nodemanager的内存占用了,没有类似的参数吧?
参考答案:
可以适当加大这个参数yarn.nodemanager.resource.pcores-vcores-multiplier。yarn.nodemanager.resource.percentage-physical-cpu-limit
yarn.nodemanager.resource.pcores-vcores-multiplier。可以试试最大写物理核心数的两倍。
https://hadoop.apache.org/docs/r3.1.4/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
,你看默认配置里面有没有你可以修改的参数。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/602794
问题二:Flink CDC 里 run -t yarn-per-job 提交,能单独指定管理内存吗?
Flink CDC 里flink run -t yarn-per-job 提交的时候,能单独指定管理内存吗? 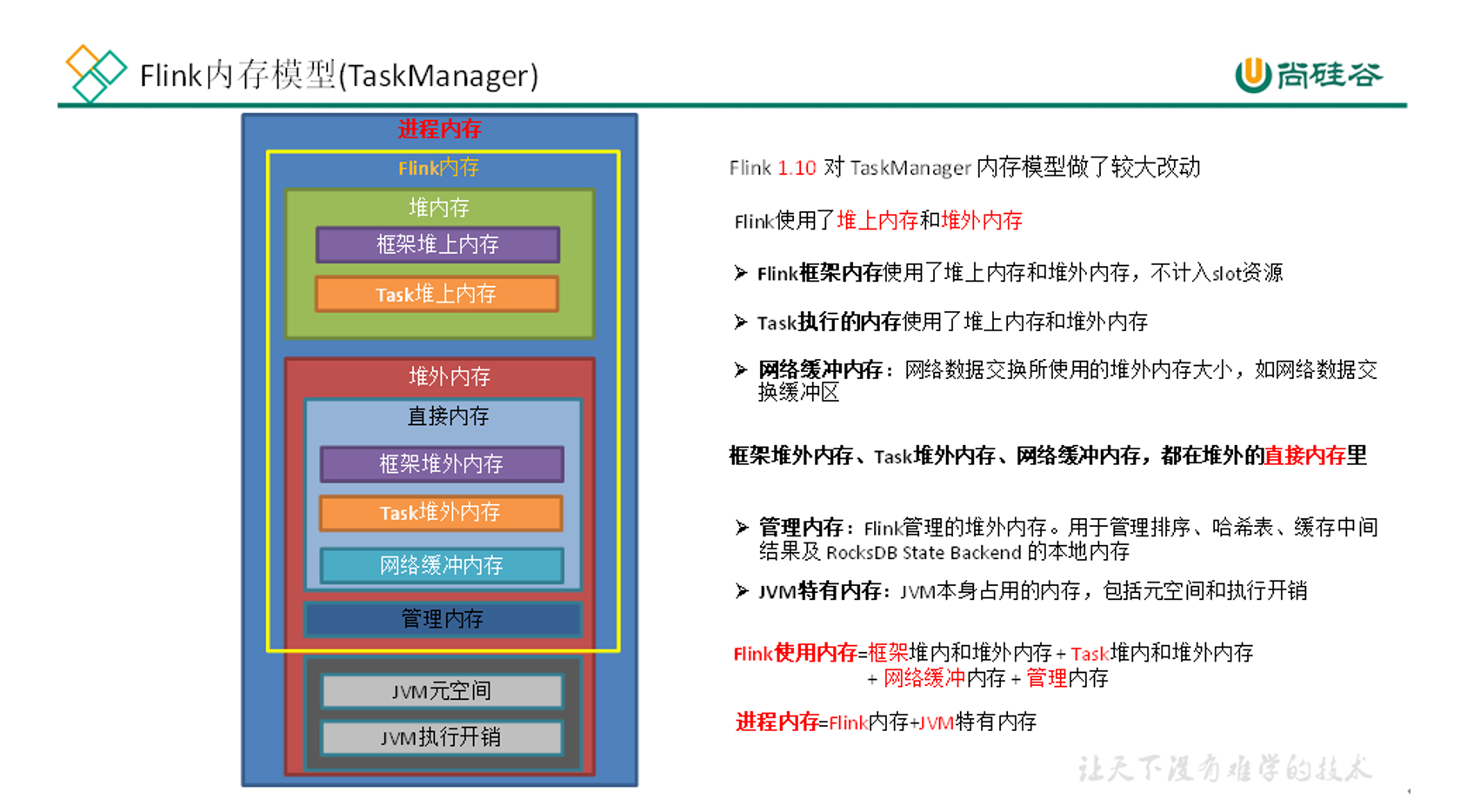
参考答案:
可以。-Dtaskmanager.memory.managed.size=128mb 这参数。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/602784
问题三:Flink CDC 里这是少什么?
Flink CDC 里这是少什么? 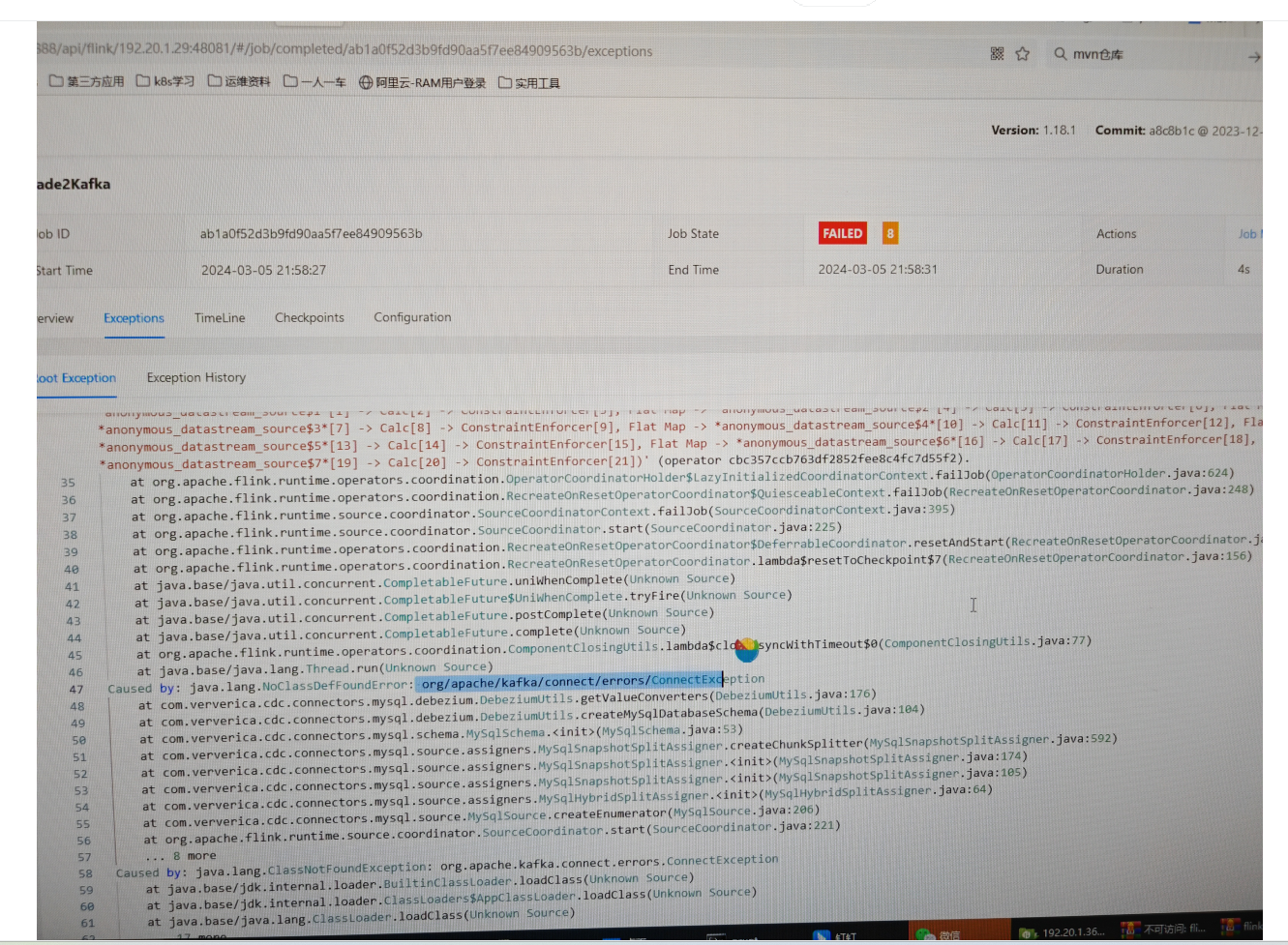
参考答案:
缺少Kafka-client的jar。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/602782
问题四:flink application 模式提交的时候,能加环境变量吗?
flink application 模式提交的时候,能加环境变量吗?
参考答案:
在 Flink 的 Application 模式下,可以设置环境变量。
Application 模式是 Flink 1.11 版本引入的新部署选项,它允许更加轻量级和可扩展的应用提交进程。在这种模式下,客户端将运行任务所需的依赖上传到 Flink Master,然后在 Master 端进行任务的提交。为了在 Application 模式下设置环境变量,您可以采取以下步骤:
- 使用
-D参数:在提交 Flink 作业时,可以通过-D参数来设置环境变量。例如,如果您想要设置一个名为MY_VARIABLE的环境变量,可以使用-DMY_VARIABLE=value的形式来设置。 - 使用配置文件:可以在 Flink 的配置文件中设置环境变量,这样在启动 Flink 作业时,这些变量会被自动加载。
- 使用 shell 脚本:在提交作业之前,可以通过 shell 脚本来设置环境变量,然后再执行 Flink 作业提交命令。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/602770
问题五:Flink我查到了1.16版本有优化,就是不知道1.12升级到1.16有没有其他大问题?
Flink中ck还是慢,应该背压导致上游in buffer满了,ck的barrier都卡住。我查到了1.16版本有优化,就是不知道1.12升级到1.16有没有其他大问题? 
参考答案:
任务不多好恢复的话,可以升级试试看,
关于本问题的更多回答可点击进行查看:
