1.概述
在Java编程环境中,javax.sql.DataSource 是Java标准API中的一个接口,用于提供数据库连接。DataSource对象允许应用程序以更高效的方式获取数据库连接,例如通过池化技术(Connection Pooling)来复用连接,从而减少频繁创建和关闭数据库连接所带来的开销。
市面上的数据源很多,本文将依托于目前市面上用的最多的,最主流的Druid数据源来聊一聊数据源技术。Druid是阿里巴巴开源的一个Java数据库连接池组件,它不仅提供高效、稳定和易于管理的数据库连接服务,而且集成了丰富的监控与诊断功能,特别适合在高并发环境下的生产级应用。以下是 Druid 数据源的主要特点:
高性能: Druid 通过连接池技术实现了对数据库连接的复用,极大地降低了建立新连接的开销,同时支持快速获取和释放连接。 它还具有强大的并发处理能力,通过优化算法减少了锁竞争,提高了多线程环境下的性能表现。
资源管理: Druid 提供了完善的连接管理机制,能够自动回收空闲连接,检测并关闭失效连接,并且支持配置连接的有效时长、最大连接数、最小连接数等参数以适应不同的负载场景。
监控与统计: 内置监控统计功能是 Druid 的一大亮点,它可以实时收集包括 SQL 执行次数、执行耗时、连接状态等在内的多种监控指标,并通过 Web 页面展示详细的监控信息和图表。 支持通过扩展插件系统来输出统计数据到各种监控系统中,例如 Log4j、Slf4j、Graphite 等。
SQL解析与拦截: Druid 可以解析 SQL 语句并进行优化,还能根据配置进行 SQL 拦截,实现诸如 SQL 注入防护、慢 SQL 监控等功能。
扩展性: Druid 设计了灵活的扩展接口,用户可以根据需求自定义连接池行为,比如添加额外的数据源代理逻辑、过滤器或监听器。
兼容性: Druid 兼容 JDBC 标准,支持广泛的数据库类型,包括 MySQL、Oracle、SQL Server、PostgreSQL 等。
零依赖: Druid 自身是一个轻量级的独立项目,没有其他外部依赖,可以方便地集成到任何基于 Java 的应用程序中,特别是在 Spring Boot 等框架下,可通过简单的配置即可启用 Druid 数据源。
2.使用
2.1.环境
直接用Spring Boot来演示了,方便快速点。
依赖:
千万注意要在spring boot环境中用要用专门的druid的starter!
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> </dependency> <!-- MySQL驱动 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.29</version> </dependency> <!-- MyBatis Plus Starter --> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.5.1</version> </dependency> <!-- Alibaba Druid 数据源 --> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.2.20</version> </dependency> </dependencies> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-dependencies</artifactId> <version>2.6.3</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement>
配置:
spring: application: name: testDemo datasource: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/db01 username: root password: admin # DruidDataSource额外配置 druid: initial-size: 5 min-idle: 5 max-active: 20 max-wait: 60000 time-between-eviction-runs-millis: 60000 min-evictable-idle-time-millis: 300000 validation-query: SELECT 1 FROM DUAL test-while-idle: true test-on-borrow: false test-on-return: false pool-prepared-statements: true max-pool-prepared-statement-per-connection-size: 20
druid的常用参数:
# Druid 数据源配置(YAML格式) druid: datasource: # 类型 type: com.alibaba.druid.pool.DruidDataSource # 基本属性 driverClassName: com.mysql.jdbc.Driver # 根据实际情况设置数据库驱动类名 url: jdbc:mysql://localhost:3306/mydatabase # 数据库连接URL username: root # 数据库用户名 password: password # 数据库密码 # 连接池相关配置 initialSize: 5 # 初始化时建立的连接数 minIdle: 5 # 最小空闲连接数 maxActive: 20 # 最大并发连接数 maxWait: 60000 # 获取连接等待超时时间(毫秒) timeBetweenEvictionRunsMillis: 60000 # 连接在池中最小生存的时间(毫秒),用于检查空闲连接是否有效 validationQuery: SELECT 1 FROM DUAL # 验证SQL语句,用来测试连接的有效性 testWhileIdle: true # 是否在空闲时进行连接有效性检测 testOnBorrow: false # 是否在借出连接时进行有效性检测 testOnReturn: false # 是否在归还连接时进行有效性检测 removeAbandoned: true # 是否自动回收被遗弃的连接 removeAbandonedTimeout: 1800 # 超过多长时间不活动则认为是被遗弃的连接(秒) # 日志与监控配置 filters: stat,wall,slf4j # 启用过滤器,例如:统计信息过滤器(stat)、SQL防火墙过滤器(wall)和日志输出过滤器(slf4j) logSlowSql: true # 是否开启慢查询日志记录 slowSqlMillis: 1000 # 慢查询阈值(毫秒) maxPoolPreparedStatementPerConnectionSize: 20 # 每个连接上可以缓存的预编译Statement数量 # 其他高级配置(根据实际需求选择启用或调整) connectionProperties: characterEncoding=UTF-8 # 设置连接属性,如字符集
2.2.连接复用
测试代码:
@SpringBootTest(classes = Main.class) public class test { @Autowired DruidDataSource druidDataSource; @Test public void test01(){ DruidPooledConnection connection01 = null; try { connection01 = druidDataSource.getConnection(); System.out.println(connection01); connection01.close(); DruidPooledConnection connection02 = druidDataSource.getConnection(); System.out.println(connection02); } catch (SQLException e) { throw new RuntimeException(e); } } }
测试结果:
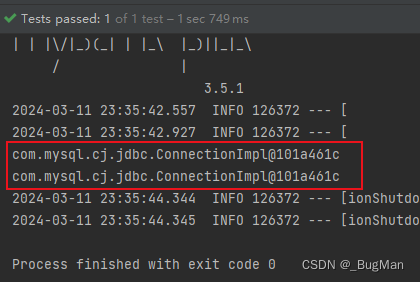
可以看到close掉的连接会被收回然后复用。
2.3.监控
druid数据源支持对sql进行监控,可以监控慢sql、黑名单、白名单等。
配置:
package com.eryi.config; import com.alibaba.druid.filter.logging.Slf4jLogFilter; import com.alibaba.druid.filter.stat.StatFilter; import com.alibaba.druid.support.http.StatViewServlet; import org.springframework.boot.web.servlet.ServletRegistrationBean; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class DruidConfig { @Bean public ServletRegistrationBean<StatViewServlet> statViewServlet() { //先配置管理后台的servLet,访问的入口为/druid/ ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean( new StatViewServlet(), "/druid/*"); // IP白名单 (没有配置或者为空,则允许所有访问) servletRegistrationBean.addInitParameter("allow", "127.0.0.1"); // IP黑名单 (存在共同时,deny优先于allow) servletRegistrationBean.addInitParameter("deny", ""); servletRegistrationBean.addInitParameter("loginUsername", "admin"); servletRegistrationBean.addInitParameter("loginPassword", "123"); return servletRegistrationBean; } /** * @description 配置慢sql拦截器 * @return */ @Bean(name = "statFilter") public StatFilter statFilter(){ StatFilter statFilter = new StatFilter(); //慢sql时间设置,即执行时间大于200毫秒的都是慢sql statFilter.setSlowSqlMillis(30); statFilter.setLogSlowSql(true); statFilter.setMergeSql(true); return statFilter; } /** * @description 配置日志拦截器 * @return */ @Bean(name = "logFilter") public Slf4jLogFilter logFilter(){ Slf4jLogFilter slf4jLogFilter = new Slf4jLogFilter(); slf4jLogFilter.setDataSourceLogEnabled(true); slf4jLogFilter.setStatementExecutableSqlLogEnable(true); return slf4jLogFilter; } }
慢sql监控:

黑白名单监控:
2.4.拦截器
过滤器是 Druid 数据源连接池的重要扩展点,通过一系列的 Filter 可以对数据库操作的各个阶段进行拦截和处理,实现诸如日志记录、性能统计、SQL 审计、权限控制、SQL 防注入等功能。
这种拦截和改写的能力可以实现很多功能,例如针对分库分表场景下的路由规则,或者在分布式事务中对事务边界内的SQL进行特殊处理。Sharding jdbc就是通过自定义数据源,然后在数据源中拦截sql,然后对sql进行改写和扩展从而实现的分库分表以及分布式事务。
Druid Filter 的工作原理与架构:
Filter接口与继承体系: com.alibaba.druid.filter.Filter 是所有过滤器需要实现的接口,定义了一系列针对数据库连接生命周期不同阶段的方法。 FilterAdapter 类是一个抽象适配器类,简化了 Filter 的实现过程,对于不关心的方法可以使用默认实现。
过滤器链与执行流程: Druid 在初始化时会根据配置构建一个过滤器链(FilterChain),每个请求(如获取连接、执行SQL等)都会按照顺序依次经过链上的每一个过滤器。过滤器之间通过代理模式相互协作,比如 DruidPooledConnection 本质上是对 JDBC Connection 的代理,而其内部又包含了多个 Statement 和 ResultSet 的代理对象,这些代理对象在创建时就会调用相应的过滤器方法。
主要的过滤器方法: 初始化与销毁:init(DruidDataSource dataSource) 用于初始化过滤器,destroy() 用于资源释放时清理。 连接相关:getConnection(DruidDataSource, DruidPooledConnection) 拦截获取连接的过程,close(DruidPooledConnection) 拦截关闭连接的操作。 SQL 执行相关:statementCreateAfter(StatementProxy, String) 在 Statement 创建后被调用,可在此处拦截并修改SQL;resultSetOpenAfter(ResultSetProxy, StatementProxy, String, boolean) 在 ResultSet 打开后被调用,可用于监控查询结果。 其他方法还包括对 PreparedStatement、CallableStatement 等的创建、关闭等事件的拦截。
启用过滤器: 通过 DruidDataSource 的 setFilters(String filters) 方法来指定要启用的过滤器集合,格式通常是逗号分隔的一系列过滤器别名或全限定类名。 自定义过滤器需注册到系统中,并且在配置文件中通过别名引用,也可以利用 SPI(服务提供者接口)机制自动发现和加载。
内置过滤器示例: stat:统计信息过滤器,收集数据库连接相关的各种统计指标。 wall:SQL防火墙过滤器,用于防止SQL注入攻击,对SQL语句进行安全检查。 config:配置信息过滤器,从配置文件读取特定的参数配置数据。
内置过滤器的注册使用:
import com.alibaba.druid.pool.DruidDataSource; @Configuration public class DruidConfig { @Bean public DataSource dataSource() { DruidDataSource dataSource = new DruidDataSource(); // 设置基础数据库连接属性(如url、username、password) dataSource.setUrl("jdbc:mysql://localhost:3306/mydb"); dataSource.setUsername("root"); dataSource.setPassword("password"); // 启用并配置内置过滤器 dataSource.setFilters("stat,wall"); // 这里以StatFilter(统计信息过滤器)和WallFilter(SQL防火墙过滤器)为例 // 对于StatFilter可能需要进一步配置统计功能(可选) StatFilter statFilter = new StatFilter(); statFilter.setLogSlowSql(true); // 开启慢查询日志 statFilter.setMergeSql(true); // 合并SQL语句(去除参数) // 注册到Druid数据源 dataSource.getProxyFilters().add(statFilter); // WallFilter通常只需要开启即可,其默认提供了SQL注入防护等功能 // 若有特殊配置需求,请参考官方文档进行设置 return dataSource; } }
- StatFilter:用于收集数据库连接池及SQL执行的统计信息,包括连接数、执行次数、耗时等。 可以通过配置来决定是否记录慢查询、合并SQL等操作。
- WallFilter: 提供SQL防火墙功能,可以防止SQL注入攻击,并对SQL执行进行一些安全策略控制。 配置项丰富,例如允许设置SQL黑名单、白名单,限制SQL长度,禁止全表更新等
自定义过滤器的注册使用:
自定义Druid过滤器用于拦截SQL时,通常需要继承com.alibaba.druid.filter.FilterAdapter或其子类,并重写与SQL执行相关的回调方法。以下是一个基础的示例,展示如何创建一个简单的自定义过滤器来拦截和修改PreparedStatement中的SQL:
import com.alibaba.druid.filter.FilterAdapter; import com.alibaba.druid.proxy.jdbc.ConnectionProxy; import com.alibaba.druid.proxy.jdbc.PreparedStatementProxy; import com.alibaba.druid.sql.parser.SQLParserUtils; import com.alibaba.druid.sql.parser.SQLStatement; import com.alibaba.druid.util.JdbcConstants; @Component public class CustomSqlInterceptorFilter extends FilterAdapter { @Override public PreparedStatementProxy connection_prepareStatement(ConnectionProxy connection, String sql) throws SQLException { // 1. 解析SQL语句 SQLStatement statement = SQLParserUtils.parse(sql, JdbcConstants.MYSQL, false); // 2. 在这里可以检查、记录或修改SQL语句 if (shouldModifySql(sql)) { // 假设我们有一个判断逻辑,决定是否要修改SQL String modifiedSql = modifySql(sql); return connection.prepareStatement(modifiedSql); } // 3. 如果不需要修改,则直接返回原始的PreparedStatement代理对象 return connection.prepareStatement(sql); } private boolean shouldModifySql(String sql) { // 根据你的业务逻辑判断是否需要修改SQL语句 // 这里仅作为示例,实际逻辑请自行实现 return true; // 示例:始终返回true表示总是修改SQL } private String modifySql(String originalSql) { // 修改SQL的具体逻辑,例如添加额外的查询条件 return originalSql + " AND your_condition = ?"; } // 其他可能需要重写的方法... } @Configuration public class DruidConfig { @Autowired private CustomSqlInterceptorFilter customSqlInterceptorFilter; @Bean public DataSource dataSource() { DruidDataSource dataSource = new DruidDataSource(); // 设置其他基本属性... // 注册自定义过滤器,这里假设你的过滤器已经在Spring容器中被实例化和管理 dataSource.getProxyFilters().add(customSqlInterceptorFilter); // 或者通过别名引用(需要先进行别名注册) // dataSource.setFilters("stat,wall,customSqlInterceptor"); return dataSource; } }
3.tomcat中的数据源
Tomcat 自身提供了一个内置的数据源实现,它基于Apache Commons DBCP(DataBase Connection Pool)或者其它连接池库(例如,从Tomcat 8.5开始,默认使用了HikariCP)。这意味着在Tomcat服务器中,你可以配置一个JDBC数据源,并将其作为全局资源注册到JNDI(Java Naming and Directory Interface)命名空间中。应用程序可以通过JNDI查找和使用这些预配置的数据源,从而方便地进行数据库连接管理和复用。 在实际配置时,你需要在Tomcat的server.xml或特定应用的context.xml文件中添加相应的数据源配置信息,包括数据源名称、数据库驱动类、URL、用户名和密码等属性。这样,在部署的应用程序就可以通过JNDI查找并获取这个数据源,而无需在应用程序代码中硬编码数据库连接信息,提高了代码的可移植性和管理性。
这部分内容有点深了,大后期博主会专门开一个系列来聊一聊JAVA规范以及手写一个tomcat和大家一起从一个完整的角度来看整个JAVA EE体系,敬请期待。