[toc]
Langchain的核心是“链”的概念,这是一个构建块,允许您组合和编排不同的组件,以创建复杂而智能的应用程序。想象一下,您是一名数据科学家,正在从事一个尖端项目,该项目涉及处理和分析大量非结构化数据,例如客户评论、社交媒体帖子,甚至是学术论文。您的目标是从这些数据中提取见解和有价值的信息,但任务的庞大数量和复杂性可能令人生畏。使用LangChain链,您可以将这个非常复杂的任务分解成更小的、可管理的部分,然后将它们链接在一起,以创建一个无缝的端到端解决方案。这就像拥有一支由高技能助手组成的团队,每个人都专注于一项特定的任务,而您正在协调他们的努力,以构建真正非凡的东西。
一、LLM Chain
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
# Initialize the language model
llm_model = "gpt-3.5-turbo"
llm = ChatOpenAI(temperature=0.9, model=llm_model)
# Create a prompt template
prompt = ChatPromptTemplate.from_template("What is the best name to describe a company that makes {product}?")
# Combine the LLM and prompt into an LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain on some input data
product = "Queen Size Sheet Set"
chain_output = chain.invoke({
product})
print(chain_output)
# Output
# {'product': {'Queen Size Sheet Set'}, 'text': 'Royal Slumber Bedding Co.'}
在此示例中,我们首先从LangChain导入必要的导入。然后,我们初始化一个 OpenAI 语言模型,并创建一个提示模板,要求提供描述给定产品的最佳名称。接下来,我们将语言模型和提示模板组合成一个 LLMChain。现在,可以使用任何产品描述调用此链,并且它将根据输入生成合适的公司名称。例如,如果我们输入“Queen Size Sheet Set”作为产品,连锁店可能会输出“Royal Slumber Bedding Co.”作为建议的公司名称。很简单,对吧?但不要被它的简单性所迷惑——LLMChain 是一个有用的工具,可用于广泛的应用程序,从内容生成到数据分析,甚至代码生成。
二、顺序链:组成多个步骤
LLMChain 是一个很好的起点,但有时我们的任务需要按特定顺序执行一系列步骤或操作。这就是顺序链发挥作用的地方,它允许我们将多个提示链接在一起,以创建更复杂和更精密的工作流程。
1.SimpleSequentialChain:一个输入,一个输出
让我们从 SimpleSequentialChain 开始,它非常适合链中每个步骤都有单个输入和单个输出的方案。想象一下,您想要创建一个系统,该系统不仅可以根据产品建议公司名称,还可以为该公司生成简短描述。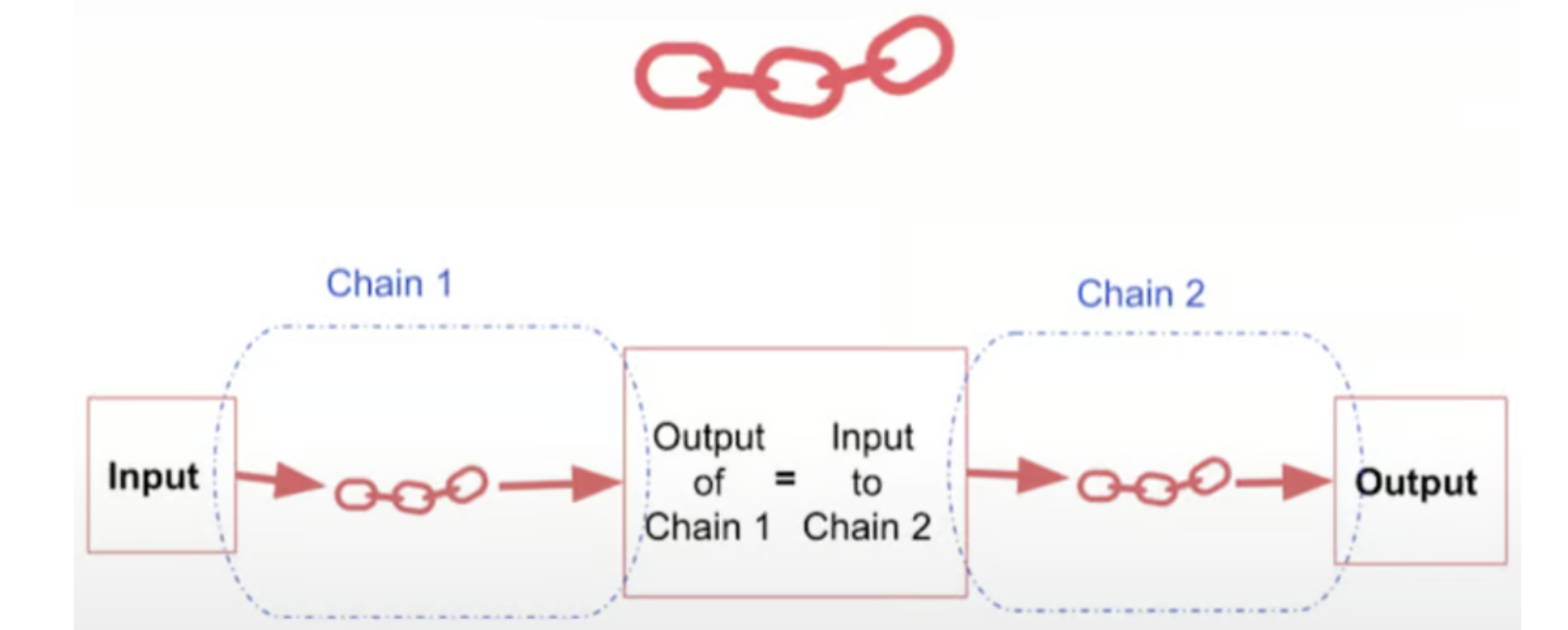
from langchain.chains import SimpleSequentialChain
# Initialize the language model
llm = ChatOpenAI(temperature=0.9, model=llm_model)
# Prompt template 1: Suggest a company name
first_prompt = ChatPromptTemplate.from_template("What is the best name to describe a company that makes {product}?")
chain_one = LLMChain(llm=llm, prompt=first_prompt)
# Prompt template 2: Generate a company description
second_prompt = ChatPromptTemplate.from_template("Write a 20-word description for the following company: {company_name}")
chain_two = LLMChain(llm=llm, prompt=second_prompt)
# Create the SimpleSequentialChain
overall_simple_chain = SimpleSequentialChain(chains=[chain_one, chain_two], verbose=True)
# Run the chain on some input data
product = "Queen Size Sheet Set"
chain_output = overall_simple_chain.invoke(product)
print(chain_output)
# Output
# {'input': 'Queen Size Sheet Set',
# 'output': 'Regal Comfort Linens provides luxurious and stylish bedding options to ensure a comfortable and elegant sleep experience for customers.'}
在此示例中,我们首先定义两个单独的 LLMChains:一个用于根据产品建议公司名称,另一个用于生成给定公司名称的简短描述。然后,我们将这两条链组合成一个 SimpleSequentialChain,指定它们的执行顺序。当我们使用“Queen Size Sheet Set”等产品调用此链时,它将首先生成一个公司名称(例如,“Royal Comfort Linens”),然后将该名称用作第二条链的输入,该链将输出类似“Regal Comfort Linens 提供豪华时尚的床上用品选择,以确保为客户提供舒适优雅的睡眠体验”。SimpleSequentialChain 的美妙之处在于它能够将复杂的任务分解为更小的、可管理的步骤,每个步骤都有明确定义的输入和输出。这种模块化方法不仅使代码更具可读性和可维护性,而且还允许随着项目的发展而获得更大的灵活性和可扩展性。
2.SequentialChain:处理多个输入和输出
虽然 SimpleSequentialChain 非常适合简单的任务,但有时我们的链需要同时处理多个输入和输出。进入 SequentialChain,这是其更简单版本的更强大、更灵活的版本。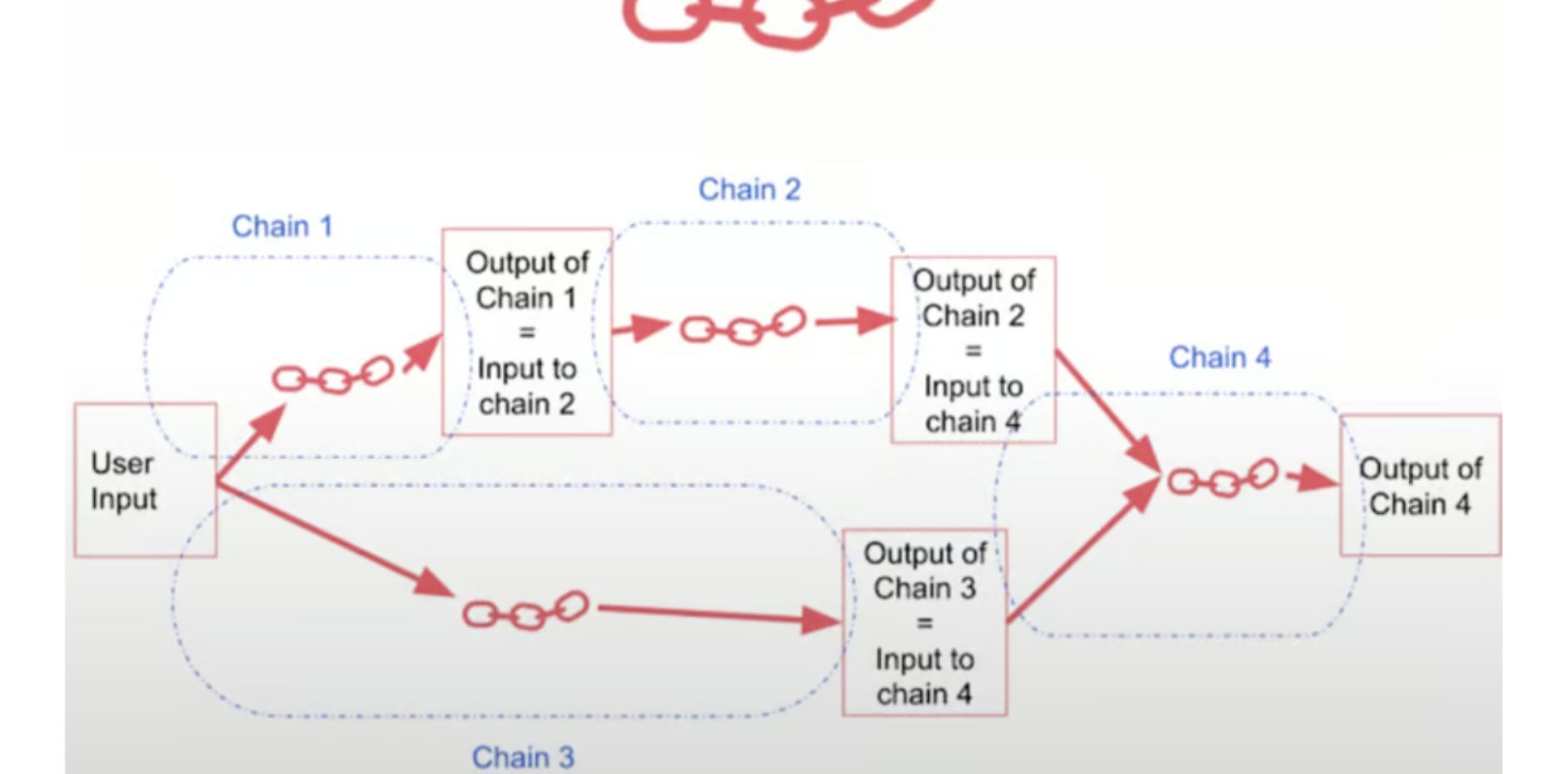
from langchain.chains import SequentialChain
# Initialize the language model
llm = ChatOpenAI(temperature=0.9, model=llm_model)
# Prompt template 1: Translate review to English
first_prompt = ChatPromptTemplate.from_template("Translate the following review to English:\n\n{Review}")
chain_one = LLMChain(llm=llm, prompt=first_prompt, output_key="English_Review")
# Prompt template 2: Summarize the review in one sentence
second_prompt = ChatPromptTemplate.from_template("Can you summarize the following review in 1 sentence:\n\n{English_Review}")
chain_two = LLMChain(llm=llm, prompt=second_prompt, output_key="summary")
# Prompt template 3: Detect the language of the review
third_prompt = ChatPromptTemplate.from_template("What language is the following review:\n\n{Review}")
chain_three = LLMChain(llm=llm, prompt=third_prompt, output_key="language")
# Prompt template 4: Generate a follow-up response
fourth_prompt = ChatPromptTemplate.from_template("Write a follow-up response to the following summary in the specified language:\n\nSummary: {summary}\n\nLanguage: {language}")
chain_four = LLMChain(llm=llm, prompt=fourth_prompt, output_key="followup_message")
# Create the SequentialChain
overall_chain = SequentialChain(
chains=[chain_one, chain_two, chain_three, chain_four],
input_variables=["Review"],
output_variables=["English_Review", "summary", "followup_message"],
verbose=True,
)
# Run the chain on some input data
review = "Je trouve le goût médiocre. La mousse ne tient pas, c'est bizarre. J'achète les mêmes dans le commerce et le goût est bien meilleur...\nVieux lot ou contrefaçon !?"
chain_output = overall_chain.invoke(review)
print(chain_output)
# Output
# Entering new SequentialChain chain...
# Finished chain.
# {'English_Review': "I find the taste mediocre. The foam doesn't hold, it's "
# 'weird. I buy the same ones in stores and the taste is much '
# 'better... \n'
# 'Old batch or counterfeit!?',
# 'Review': "Je trouve le goût médiocre. La mousse ne tient pas, c'est bizarre. "
# "J'achète les mêmes dans le commerce et le goût est bien "
# 'meilleur...\n'
# 'Vieux lot ou contrefaçon !?',
# 'followup_message': "Je suis désolé(e) d'apprendre que vous avez trouvé le "
# "goût du produit médiocre. Il est possible qu'il s'agisse "
# "d'un lot ancien ou contrefait, comme vous l'avez "
# "suggéré. Il est important de s'assurer de la qualité des "
# 'produits que nous consommons. Avez-vous envisagé de '
# 'contacter le fabricant pour clarifier la situation ? '
# "J'espère que votre prochaine expérience d'achat sera "
# 'plus satisfaisante. Merci de partager votre avis.',
# 'summary': 'The reviewer found the taste of the product mediocre and '
# 'different from what they usually buy in stores, suggesting that '
# 'it may be an old batch or counterfeit.'}
在这个更高级的示例中,我们定义了四个单独的 LLMChains,每个 LLMChain 都有自己的特定任务:
- 1.将商品评论从原文翻译成英文。
- 2.用一句话总结翻译后的评论。
- 3.检测评论的原始语言。
- 4.以检测到的语言生成对摘要的后续响应。
这里的关键区别在于,每条链可以有多个输入和输出变量,我们需要使用 output_key 和 input_variables/output_variables 参数显式指定这些变量。例如,第一条链将原始评论作为输入并输出English_Review。然后,第二条链将English_Review作为输入,并输出一句话的摘要。第三条链使用原始评论来检测语言,最后,第四条链将摘要和语言结合起来生成followup_message。然后,我们将这四条链组合成一个 SequentialChain,指定它们应该执行的顺序,以及整个链的输入和输出变量。当我们用产品评论来调用这个链条时,比如“Je trouve le goût médiocre.La mousse ne tient pas, c'est bizarre.J'achète les mêmes dans le commerce et le goût est bien meilleur...nVieux lot ou contrefaçon !?“,它将经历链条中的每一步,将评论翻译成英语,对其进行总结,检测原始语言(在本例中为法语),最后根据摘要生成法语的后续回复。SequentialChain 的有用之处在于它能够处理具有多个输入和输出的复杂工作流程,允许您将最复杂的任务分解为更小、可管理的组件。
三、路由链:路由到专门的子链
有时,我们的任务需要不同的方法或专门的子链,具体取决于输入数据。这就是路由器链发挥作用的地方,它允许我们根据某些标准动态地将输入路由到适当的子链。
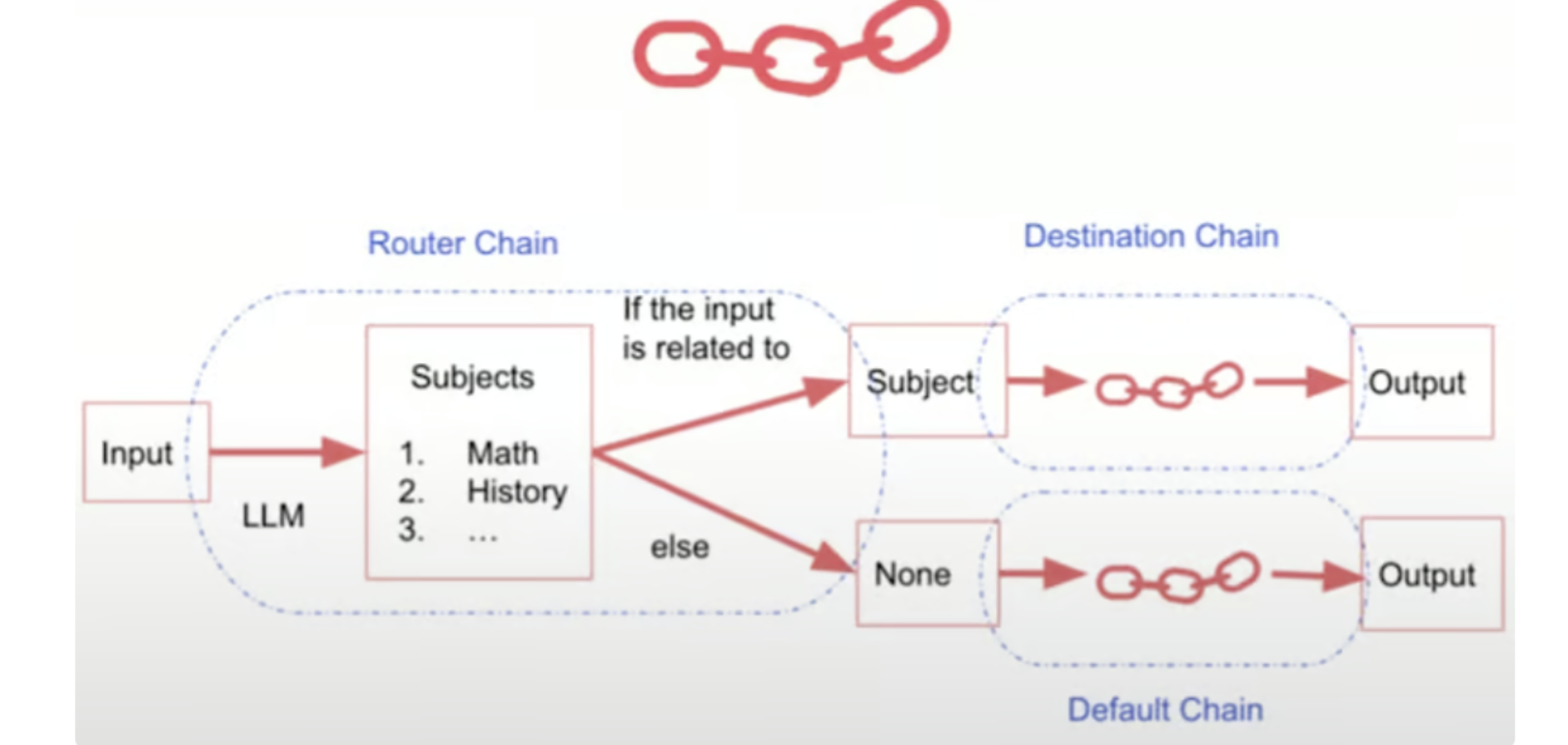
1.MultiPromptChain:专用提示之间的路由
路由器链的一个常见用例是当我们有多个提示时,每个提示专门用于特定类型的输入或任务。MultiPromptChain 允许我们定义这些专用提示,然后根据输入内容将输入动态路由到适当的提示。
from langchain.chains.router import MultiPromptChain
from langchain.chains.router.llm_router import LLMRouterChain, RouterOutputParser
from langchain.prompts import PromptTemplate
# Define specialized prompt templates
physics_template = """You are a very smart physics professor. \
You are great at answering questions about physics in a concise\
and easy to understand manner. \
When you don't know the answer to a question you admit\
that you don't know.
Here is a question:
{input}"""
math_template = """You are a very good mathematician. \
You are great at answering math questions. \
You are so good because you are able to break down \
hard problems into their component parts,
answer the component parts, and then put them together\
to answer the broader question.
Here is a question:
{input}"""
history_template = """You are a very good historian. \
You have an excellent knowledge of and understanding of people,\
events and contexts from a range of historical periods. \
You have the ability to think, reflect, debate, discuss and \
evaluate the past. You have a respect for historical evidence\
and the ability to make use of it to support your explanations \
and judgements.
Here is a question:
{input}"""
computerscience_template = """ You are a successful computer scientist.\
You have a passion for creativity, collaboration,\
forward-thinking, confidence, strong problem-solving capabilities,\
understanding of theories and algorithms, and excellent communication \
skills. You are great at answering coding questions. \
You are so good because you know how to solve a problem by \
describing the solution in imperative steps \
that a machine can easily interpret and you know how to \
choose a solution that has a good balance between \
time complexity and space complexity.
Here is a question:
{input}"""
# Create prompt info dictionaries
prompt_infos = [
{
"name": "physics",
"description": "Good for answering questions about physics",
"prompt_template": physics_template,
},
{
"name": "math",
"description": "Good for answering math questions",
"prompt_template": math_template,
},
{
"name": "History",
"description": "Good for answering history questions",
"prompt_template": history_template,
},
{
"name": "computer science",
"description": "Good for answering computer science questions",
"prompt_template": computerscience_template,
},
]
# Initialize the language model
llm = ChatOpenAI(temperature=0, model=llm_model)
# Create destination chains (LLMChains) for each prompt
destination_chains = {
}
for p_info in prompt_infos:
name = p_info["name"]
prompt_template = p_info["prompt_template"]
prompt = ChatPromptTemplate.from_template(template=prompt_template)
chain = LLMChain(llm=llm, prompt=prompt)
destination_chains[name] = chain
# Define a default chain for inputs that don't match any specialized prompt
default_prompt = ChatPromptTemplate.from_template("{input}")
default_chain = LLMChain(llm=llm, prompt=default_prompt)
MULTI_PROMPT_ROUTER_TEMPLATE = """Given a raw text input to a \
language model select the model prompt best suited for the input. \
You will be given the names of the available prompts and a \
description of what the prompt is best suited for. \
You may also revise the original input if you think that revising\
it will ultimately lead to a better response from the language model.
<< FORMATTING >>
Return a string snippet enclosed by triple backticks a JSON object formatted to look like below:
{
"destination": string \ name of the prompt to use or "default"
"next_inputs": string \ a potentially modified version of the original input
}
REMEMBER: "destination" MUST be one of the candidate prompt \
names specified below OR it can be "default" if the input is not \
well suited for any of the candidate prompts. \
REMEMBER: "next_inputs" can just be the original input \
if you don't think any modifications are needed.
<< CANDIDATE PROMPTS >>
{destinations}
REMEMBER: If destination name not there input the question
<< INPUT >>
{input}
<< OUTPUT (remember to include the ```
json
```)>>"""
# Create the router prompt template
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(destinations=destinations_str) # (a prompt template for the router to use)
router_prompt = PromptTemplate(template=router_template, input_variables=["input"], output_parser=RouterOutputParser())
router_chain = LLMRouterChain.from_llm(llm, router_prompt)
# Create the MultiPromptChain
chain = MultiPromptChain(
router_chain=router_chain,
destination_chains=destination_chains,
default_chain=default_chain,
verbose=True,
)
# Run the chain on some input data
physics_question = "What is black body radiation?"
chain_output = chain.invoke(physics_question)
print(chain_output)
# Output
# Entering new MultiPromptChain chain...
# physics: {'input': 'What is black body radiation?'}
# Finished chain.
# {'input': 'What is black body radiation?',
# 'text': "Black body radiation is the electromagnetic radiation emitted by a perfect absorber of radiation, known as a black body. A black body absorbs all incoming radiation and emits radiation across the entire electromagnetic spectrum. The spectrum of black body radiation is continuous and follows a specific distribution known as Planck's law. This phenomenon is important in understanding the behavior of objects at different temperatures and is a key concept in the field of thermal physics."}
math_question = "what is 2 + 2"
chain_output = chain.invoke(math_question )
print(chain_output)
# Output
# Entering new MultiPromptChain chain...
# math: {'input': 'what is 2 + 2'}
# Finished chain.
# {'input': 'what is 2 + 2', 'text': 'The answer to 2 + 2 is 4.'}
biology_question = "Why does every cell in our body contain DNA?"
chain_output = chain.invoke(biology_question )
print(chain_output)
# Output
# Entering new MultiPromptChain chain...
# None: {'input': 'Why does every cell in our body contain DNA?'}
# Finished chain.
# {'input': 'Why does every cell in our body contain DNA?',
# 'text': 'Every cell in our body contains DNA because DNA carries the genetic information that determines the characteristics and functions of an organism. DNA contains the instructions for building and maintaining an organism, including the proteins that are essential for cell function and structure. This genetic information is passed down from parent to offspring and is essential for the growth, development, and functioning of all cells in the body. Having DNA in every cell ensures that the genetic information is preserved and can be used to carry out the necessary processes for life.'}
在此示例中,我们首先定义了几个专用的提示模板,每个模板旨在处理特定类型的输入或任务(例如,物理问题、数学问题、历史问题、计算机科学问题)。然后,我们为每个模板创建提示信息词典,其中包括名称、描述和实际的提示模板本身。接下来,我们初始化我们的语言模型,并为每个专用提示创建目标链 (LLMChains)。这些目标链将是当输入与特定提示匹配时调用的目标链。我们还定义了一个默认链,该链将用于与任何专用提示不匹配的输入。MultiPromptChain 的核心是路由器链,它负责根据输入确定要使用的目标链。我们定义一个路由器提示模板,为路由器提供指令和格式,然后使用此模板和我们的语言模型创建 LLMRouterChain。最后,我们创建 MultiPromptChain 本身,传入路由器链、目标链和默认链。
当我们用“什么是黑体辐射?”这样的输入调用这个链时,路由器链将分析输入并确定这是一个物理问题。然后,它会将输入路由到物理目标链,该目标链将提供有关黑体辐射的详细答案。如果我们输入的问题与任何专业提示都不匹配,例如“DNA在细胞中的作用是什么?”,路由器链会将输入路由到默认链,默认链将尝试使用预训练的LLM数据提供一般答案。MultiPromptChain 允许我们通过动态路由输入到最合适的子链或提示来创建高度专业化和高效的工作流,确保每个输入都由最适合任务的组件处理。
2.路由链的优势
路由器链具有多种优势,使其成为机器学习和自然语言处理工具包中的有用工具:
1.专业化:通过将输入路由到专门的子链,您可以确保每个任务都由最适合它的组件处理,从而获得更准确和相关的结果。
2.效率:路由器链不是通过多个链或提示来运行每个输入,而是智能地将输入路由到适当的目的地,从而节省计算资源并提高整体性能。
3.灵活性:通过添加或删除目标链或提示,可以轻松扩展或修改路由器链,使其高度适应不断变化的需求或新域。
- 4.模块化:每个子链或提示都可以独立开发和测试,促进代码的可复用性和可维护性。
- 5.可扩展性:随着项目的增长和复杂性的增加,路由器链可以帮助管理和编排越来越多的专用组件,确保您的系统保持强大和高效。
借助路由器链,您可以创建复杂而智能的应用程序,这些应用程序可以处理各种输入和任务,同时保持高度的专业化和效率。
小结
本节我们学习的是LangChain中的Chain(链),我们学习了顺序链和路由链,同时还学习了每种链的示例,希望同学们通过本节的学习能够对LangChain 中的Chain(链)有一个深刻的认识。

