写在文章开头
go语言的map相较于Java设计有着不同的设计思想,而这篇文章我将从go语言的角度来聊聊哈希集的设计,希望通过这篇文章的阅读可以让读者对于map的设计有着更进一步的理解。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的 java coder ,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
详解go语言map
map的数据结构
我们通过一张图了解一下map,go语言中的map通过count来记录map的键值对个数,并且通过buckets指针指向管理键值对的数组[]bmap。
可以看到bmap是记录键值对的核心数据结构,bmap是一个固定大小的数据结构,这意味着要存储更多的键值对就需要更多的bmap。每一个bmap分别由tophash、keys、values这3个数组,这其中tophash记录的是能够定位到当前索引位置key的哈希值,例如tophash[0]记录的就是keys[0]这个key对应的哈希结果,values则是记录相同位置key对应的value值。
需要注意的是go语言中对于map冲突的解决办法,假设我们需要插入某个键值对,进行哈希运算的时候得到bmap的索引为2,但是索引2的bmap空间全被占用,那么go语言就会基于拉链法的思想,创建一个全新的bmap通过overflow指针指向这个空间,将冲突的键值对存入这个新的bmap中。

可以看到go语言将键值对分别存放,其实这么设计也是有它的想法的,我们都知道CPU为了更高效的处理数据会将数据加载到CPU的1级缓存中,假设我们的操作系统为64位,这就意味着我们加载数据数据大小按照8字节等比填充即填满一个CPU缓存,避免一段数据分段拆到不同的CPU核心中。
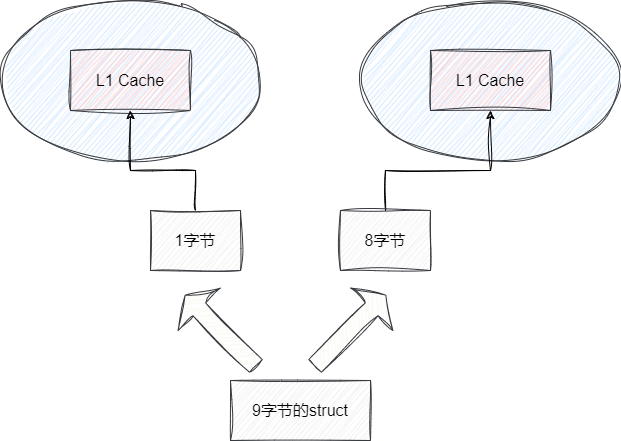
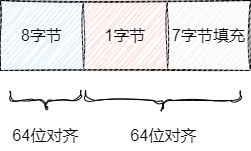
假设我们的map的key为8字节的int和1个字节的value。如果k-v一起存放,在进行内存对齐时,就要为了value的内存对齐填充7字节,很明显如果每个键值对都这样做,对于宝贵的内存空间而言简直就是一种浪费。
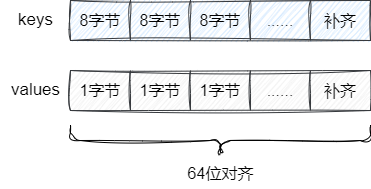
所以设计者就将键值对存放到各自的数组中,如此一来进行内存填充时,只需根据数组大小一次性补齐即可。
对应的我们给出map的定义,可以看到hmap成员比较复杂,这里笔者说明几个比较核心的:
- count:map size
- B:桶数量的次方,例如8个桶,即3次方
- hash0:哈希种子进行哈希运算的
- buckets:桶数组的指针
- oldbuckets:进行扩容时记录旧的桶
// A header for a Go map.
type hmap struct {
count int // map的键值对个数,通过len可以获取这个值的结果
B uint8 // 记录当前桶的次幂,录入当前桶为8个,那么B就等于3(2^3)
// ......
hash0 uint32 // 计算机哈希值的哈希种子
// ......
buckets unsafe.Pointer // 记录存放键值对数组的指针buckets
// ......
}
上文提到buckets记录桶数组指针,对应桶结构体如下,可以看到它仅仅提供了tophash数组:
// A bucket for a Go map.
type bmap struct {
//数组长度为9的u8数组,记录key的哈希值
tophash [bucketCnt]uint8
}
实际上这也是go为了方便扩展而故意为之的,为了保证我们的存储的键值对可以是各种类型,go的bmap并没有存放任何键值对的信息。只有当程序进行编译时,编译器根据声明的map类型进行字段填充,最终bmap的数据结构就会变为类似于下面这样:
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
keys int
values string
overflow unsafe.Pointer
}
map初始化
了解了map的整体数据结构之后,我们就来看看map的初始化的源码,因为go语言执行设计各种编译链接,所以对于map的构建我们可以需要通过汇编指令得到实际的创建方式,于是我们给出下面这段示例代码:
m := make(map[int]string, 64)
m[1] = "xiaoming"
fmt.Println(m)
使用命令:
go build -gcflags -S main.go
最终我们得到了map的创建函数为makemap:
0x0026 00038 (F:\github\awesomeProject\main.go:8) CALL runtime.makemap(SB)
然后我们就可以在map.go这个文件中定位到这个方法,该方法会先判断需要分配的内存是否超出最大值,如果未超过则会进行哈希种子初始化、桶的大小计算,以及考虑到后续的空间会根据B的值判断,根据设计者们的经验来看,它们认为当B大于4即桶的个数大于8的情况下的场景有很大概率出现溢出的情况,所以它们会在makeBucketArray调用时提前分配溢出桶。
func makemap(t *maptype, hint int, h *hmap) *hmap {
//判断申请的内存是否超出限制
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
// 初始化map
if h == nil {
h = new(hmap)
}
//计算哈希种子的值
h.hash0 = fastrand()
//基于传入的size即hint 获取2^b *6.5的最大值,实现2^b *6.5<=hint
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
//根据计算结果创建bucket,假如b大于4说明当前的map很可能出现溢出的情况,需要针对提前创建几个溢出桶
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
存入键值对
对于go语言来说,其存储键值对的方式比较简单:
- 基于哈希种子
hash0得到一个哈希值。 - 基于B的大小获取低B位的值,例如B为3(即bucket为8),则取低3位置的值(定位到的bucket永远在8范围内),如下图,对应的bucket为第二个。
- 取高8位获取bucket中的具体位置,如下图所示高8位为1,则取
bucket2的索引1位置。

基于上述汇编码查看到我们对map进行赋值时得到的方法为mapassign_fast64:
0x0040 00064 (F:\github\test\main.go:8) CALL runtime.mapassign_fast64(SB)
这里笔者拿出对应的核心代码,对应的过程和上图一致,笔者就不多赘述了:
func mapassign_fast64(t *maptype, h *hmap, key uint64) unsafe.Pointer {
//计算哈希值
hash := t.hasher(noescape(unsafe.Pointer(&key)), uintptr(h.hash0))
again:
//定位到bucket桶的指针b
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork_fast64(t, h, bucket)
}
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
//分别记录bucket指针,索引指针,key的指针
var insertb *bmap
var inserti uintptr
var insertk unsafe.Pointer
//遍历定位到bucket指针和inserti指针位置
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
//若对应tophash位置为空这个位置就可以作为插入的指针位置
if isEmpty(b.tophash[i]) {
if insertb == nil {
insertb = b
inserti = i
}
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := *((*uint64)(add(unsafe.Pointer(b), dataOffset+i*8)))
if k != key {
continue
}
insertb = b
inserti = i
goto done
}
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
//......
//tophash数组记录对应key的哈希
insertb.tophash[inserti&(bucketCnt-1)] = tophash(hash) // mask inserti to avoid bounds checks
//定位key指针位置存储key
insertk = add(unsafe.Pointer(insertb), dataOffset+inserti*8)
// store new key at insert position
*(*uint64)(insertk) = key
h.count++
done:
//定位insertb对应的索引位置存储t.elemsize
elem := add(unsafe.Pointer(insertb), dataOffset+bucketCnt*8+inserti*uintptr(t.elemsize))
if h.flags&hashWriting == 0 {
fatal("concurrent map writes")
}
h.flags &^= hashWriting
return elem
}
查数据
我们打印map值的时候调用了这个方法访问key:
0x00a1 00161 (F:\github\awesomeProject\main.go:10) CALL runtime.mapaccess1_fast64(SB)
对应的源码如下如下,整体流程也是计算位置并循环定位,具体核心步骤笔者以给出注释,读者可自行参阅:
func mapaccess1_fast64(t *maptype, h *hmap, key uint64) unsafe.Pointer {
//.......
var b *bmap
if h.B == 0 {
// One-bucket table. No need to hash.
b = (*bmap)(h.buckets)
} else {
//定位哈希
hash := t.hasher(noescape(unsafe.Pointer(&key)), uintptr(h.hash0))
//找到bucket指针b
m := bucketMask(h.B)
b = (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
//.......
}
//遍历这个bucket到这个bucket的overflow知道找到这个key的键值对
for ; b != nil; b = b.overflow(t) {
for i, k := uintptr(0), b.keys(); i < bucketCnt; i, k = i+1, add(k, 8) {
//如果tophash和当前key计算的值一致则说明找到了,返回这个键值对指针
if *(*uint64)(k) == key && !isEmpty(b.tophash[i]) {
return add(unsafe.Pointer(b), dataOffset+bucketCnt*8+i*uintptr(t.elemsize))
}
}
}
return unsafe.Pointer(&zeroVal[0])
}
小结
本文对map的源码进行了简单的分析,由于map在编译器会做很多的优化,所以调试和理解相较于Java更困难一些,希望感兴趣的读者可以进行读者的思路自行编译并查阅理解源码。笔者也会在后续的文章中,对于map如何解决冲突以及在哈希等设计进行更加深入的分析,希望对你有帮助。
我是 sharkchili ,CSDN Java 领域博客专家,开源项目—JavaGuide contributor,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
参考
GoLang学习之map源码剖析:https://www.golangcoding.com/2021/05/04/GoLang%E5%AD%A6%E4%B9%A0%E4%B9%8Bmap%E6%BA%90%E7%A0%81%E5%89%96%E6%9E%90/
【go语言之map源码分析】:https://blog.csdn.net/qq_37674060/article/details/127061426
理解Go语言struct的内存对齐
:http://t.csdnimg.cn/A9Obp

