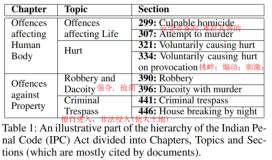
性能优化(Performance Optimization)是指通过各种技术手段和策略提升软件应用、网站或系统的运行效率,减少资源消耗,改善用户体验的过程。性能优化可以在多个层面进行,包括但不限于代码优化、数据库优化、硬件资源利用、网络优化等。
以下是一些常见的性能优化方法和它们的作用:
1. 代码优化
- 算法优化:选择更高效的算法,减少时间复杂度。
- 数据结构优化:使用合适的数据结构,提高数据访问和处理效率。
- 避免冗余计算:通过缓存结果避免重复计算。
2. 数据库优化
- 索引:为数据库表添加合适的索引,加快查询速度。
- 查询优化:编写高效的SQL查询,减少不必要的数据加载。
- 规范化:数据库规范化减少数据冗余,提高数据完整性。
3. 硬件资源利用
- 负载均衡:使用负载均衡技术分散服务器压力。
- 资源调度:合理分配CPU、内存等资源,提高硬件利用率。
4. 网络优化
- 带宽管理:优化网络带宽使用,提高数据传输效率。
- 内容分发网络(CDN):使用CDN减少数据传输距离,加快加载速度。
5. 缓存机制
- 服务器端缓存:缓存热点数据,减少数据库访问。
- 客户端缓存:利用浏览器缓存减少重复加载资源。
6. 前端性能优化
- 代码分割:按需加载JavaScript和CSS文件。
- 资源压缩:压缩图片和代码文件,减少文件大小。
- 懒加载:延迟加载非关键资源,提高首屏加载速度。
7. 代码部署和监控
- 自动化测试:通过自动化测试及早发现性能问题。
- 性能监控:实时监控应用性能,快速响应性能瓶颈。
8. 系统架构优化
- 微服务架构:将应用拆分成小型服务,提高可维护性和可扩展性。
- 异步处理:使用消息队列等技术实现异步处理,提高系统响应速度。
怎么用:
性能优化是一个持续的过程,需要根据应用的具体情况来定制优化策略。以下是实施性能优化的一般步骤:
- 性能分析:使用性能分析工具识别瓶颈。
- 设定目标:根据业务需求和用户体验设定性能目标。
- 优化实施:根据分析结果,选择适当的优化方法。
- 测试验证:通过测试验证优化效果,确保没有引入新的问题。
- 监控和调整:持续监控性能,根据反馈进行调整。