Kubernetes 作为当今云原生业界标准,具备良好的生态以及跨云厂商能力。Kubernetes 很好的抽象了 IaaS 资源交付标准,使得云资源交付变的越来越简单,与此同时用户期望更多的聚焦于业务自身,做到面向应用交付,Serverless 理念也因此而生。 那么如何通过原生 k8s 提供Serverless 能力?如何实现GPU等异构资源按需使用?这里给大家介绍一下我们在Serverless Kubernetes 开发实践:异构资源,按需使用。
方案介绍
使用 Knative + ASK 作为 Serverless 架构。数据采集之后,发送到消息队列(Kafka), Kafka事件源接收到事件之后,通过服务网关访问数据处理服务,数据处理服务根据请求量按需自动扩缩容
目标读者
Kubernetes 容器领域开发者。
Serverless 领域开发者。
适应场景
AI 音视频编/解码场景。
大数据及AI 智能识别。
相关概念
Serverless Kubernetes(ASK):ACK Serverless集群是阿里云推出的无服务器Kubernetes容器服务。
Knative:Knative 是一款基于Kubernetes的Serverless框架。其目标是制定云原生、跨平台的Serverless编排标准。Knative通过整合容器构建(或者函数)、工作负载管理(动态扩缩)以及事件模型这三者来实现的这一Serverless标准。
方案架构
方案架构图
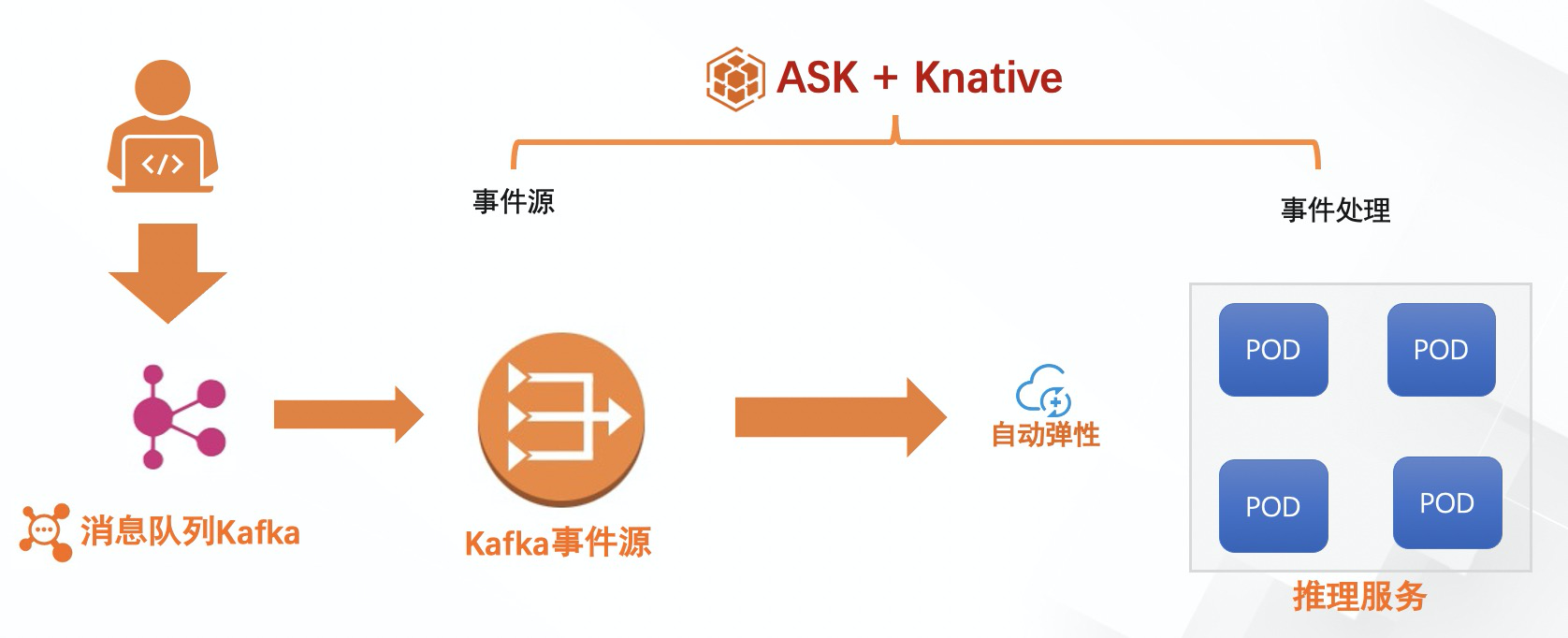
用户将数据采集之后,将数据发送到消息队列Kafka中,Knative 中的Kafka事件源接收到消息,并发送到 AI 推理服务,推理服务对事件进行意图识别处理。
方案优势
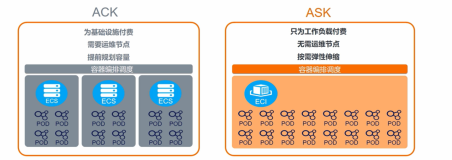
对于希望通过 Serverless 技术实现按需使用资源,节省资源使用成本,简化运维部署 ,另外还有 GPU 等异构资源业务诉求的用户。使用 ASK + Knative 方案 ,可以满足 GPU 等异构资源使用诉求,同时简化应用运维部署(尽可能少的操作 k8s deployment/svc/ingress/hpa等资源),IaaS资源免运维。
方案实施
前提条件
已安装 KafaSource 事件源。
操作步骤
第一步:部署推理服务
该服务用于接收事件驱动发送的事件,并根据请求数进行自动扩缩容,进行数据处理。部署之前,我们先确认当前无工作负载,以便观察部署之后的结果。
接着通过 Knative 把推理处理部署到 GPU 类型工作负载。这里我们通过YAML的方式进行部署,YAML内容如下:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: test-ai-process
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/maxScale: "100"
autoscaling.knative.dev/minScale: "1"
k8s.aliyun.com/eci-use-specs: ecs.gn6i-c4g1.xlarge #指定支持的ECI GPU规格。
spec:
containerConcurrency: 2
containers:
- image: registry.cn-hangzhou.aliyuncs.com/ai-samples/bert-intent-detection:1.0.1
name: user-container
ports:
- containerPort: 80
name: http1
resources:
limits:
nvidia.com/gpu: '1' #容器所需的GPU个数,必须指定该值,否则Pod启动后将会报错。主要参数说明:
minScale和maxScale:表示服务配置的最小和最大Pod数量。
containerConcurrency:表示配置的Pod最大请求并发数。
k8s.aliyun.com/eci-use-specs:表示配置的 eci 规格。
那么接下来我们部署该服务。
在集群管理页左侧导航栏中,选择应用 > Knative。
在服务管理页签右上角,单击【使用模板创建】。选择default 命名空间,将上面的 YAML 内容粘贴到模板,点击创建。

推理服务部署完成,我们通过如下方式进行服务访问。
$ curl -H "host: test-ai-process.default.8829e4ebd8fe9967.app.alicontainer.com" "http://120.26.143.xx/predict?query=music" -v结果如下:
* Trying 120.26.143.xx...
* TCP_NODELAY set
* Connected to 120.26.143.xx (120.26.143.xx) port 80 (#0)
> GET /predict?query=music HTTP/1.1
> Host: test-ai-process.knative-serving.8829e4ebd8fe9967.app.alicontainer.com
> User-Agent: curl/7.64.1
> Accept: */*
>
< HTTP/1.1 200 OK
< Date: Thu, 17 Feb 2022 09:10:06 GMT
< Content-Type: text/html; charset=utf-8
< Content-Length: 9
< Connection: keep-alive
<
* Connection #0 to host 120.26.143.xx left intact
PlayMusic* #意图识别结果第二步:部署事件驱动
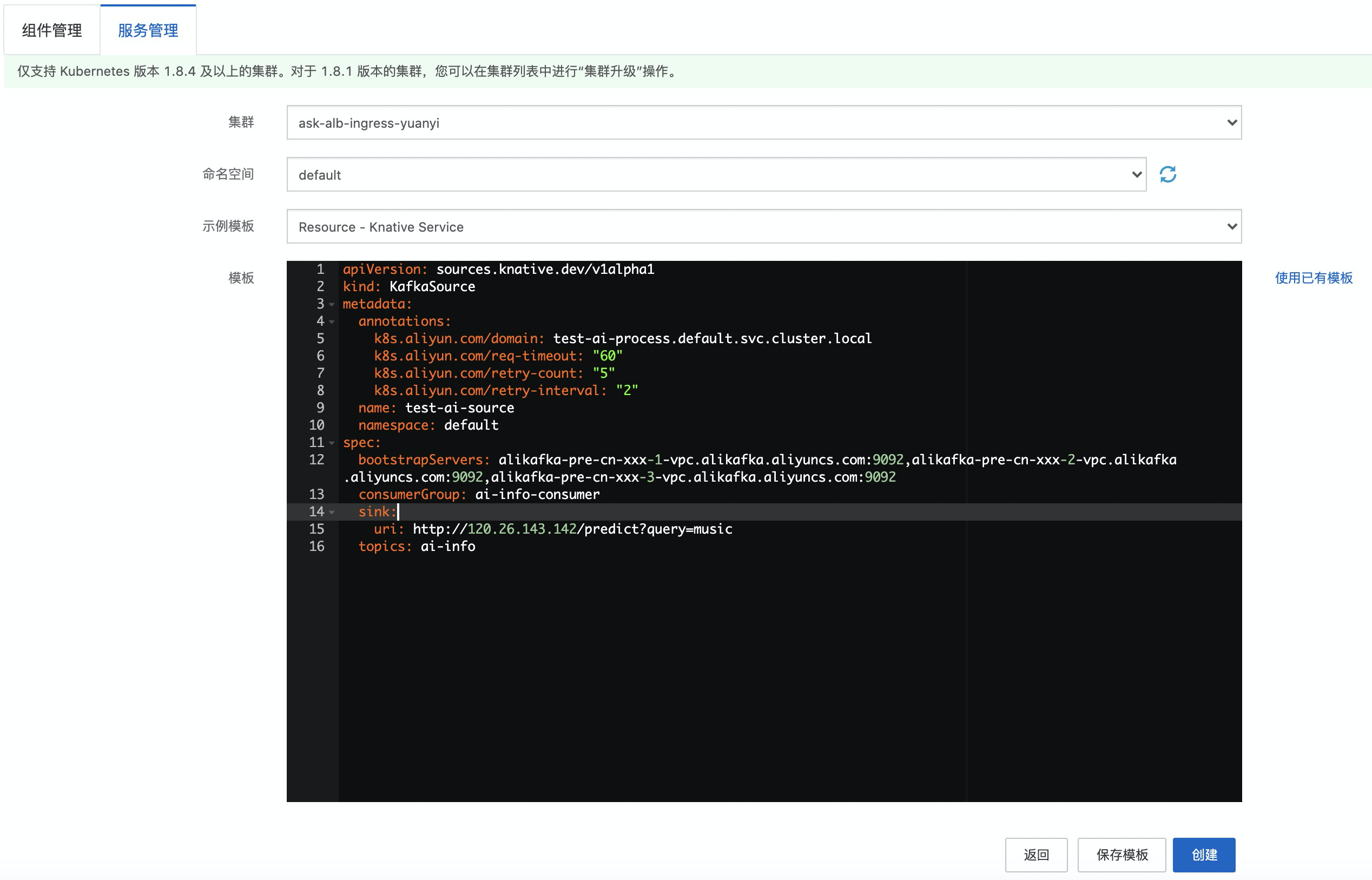
事件驱动用于接收事件并进行事件流过滤、流转。这里我们使用 Kafka 事件源作为事件驱动,用于从 Kafka 接收事件,然后把事件到消息处理。我们通过YAML的方式进行部署, YAML内容如下:
apiVersion: sources.knative.dev/v1alpha1
kind: KafkaSource
metadata:
annotations:
k8s.aliyun.com/domain: test-ai-process.default.svc.cluster.local
k8s.aliyun.com/req-timeout: "60"
k8s.aliyun.com/retry-count: "5"
k8s.aliyun.com/retry-interval: "2"
name: test-ai-source
namespace: default
spec:
bootstrapServers: alikafka-pre-cn-xxx-1-vpc.alikafka.aliyuncs.com:9092,alikafka-pre-cn-7pp2kmoc7002-2-vpc.alikafka.aliyuncs.com:9092,alikafka-pre-cn-xx-3-vpc.alikafka.aliyuncs.com:9092
consumerGroup: ai-info-consumer
sink:
uri: http://120.26.143.xx/predict?query=music
topics: ai-info主要参数说明:
kafka配置包括:kafka服务地址 ,弹幕消息 topics 以及消费组consumerGroup。
转发路由:
-
目标服务:
k8s.aliyun.com/domain: test-ai-process.default.svc.cluster.local。目标路由:
http://120.26.143.xx/predict?query=music。
那么接下来我们部署该服务。
在集群管理页左侧导航栏中,选择应用 > Knative。
在服务管理页签右上角,单击【使用模板创建】。选择default 命名空间,将上面的 YAML 内容粘贴到模板,点击创建。
方案验证
接下来我们模拟并发发送消息,进行自动弹性验证。golang 客户端向Kafka发送消息代码如下:
package main
import (
"crypto/tls"
"crypto/x509"
"fmt"
"io/ioutil"
"strconv"
"time"
"github.com/Shopify/sarama"
)
var producer sarama.SyncProducer
func init() {
// 初始化 kafka 客户端
// 设置用户名、密码、访问证书
kafkaConfig := sarama.NewConfig()
kafkaConfig.Version = sarama.V0_10_2_0
kafkaConfig.Producer.Return.Successes = true
kafkaConfig.Net.SASL.Enable = true
kafkaConfig.Net.SASL.User = "alikafka_xxx"
kafkaConfig.Net.SASL.Password = "RpfoLE41hdX60ybxxxx"
kafkaConfig.Net.SASL.Handshake = true
certBytes, err := ioutil.ReadFile("/Users/richard/common/demo/ca-cert")
clientCertPool := x509.NewCertPool()
ok := clientCertPool.AppendCertsFromPEM(certBytes)
if !ok {
panic("kafka producer failed to parse root certificate")
}
kafkaConfig.Net.TLS.Config = &tls.Config{
//Certificates: []tls.Certificate{},
RootCAs: clientCertPool,
InsecureSkipVerify: true,
}
kafkaConfig.Net.TLS.Enable = true
if err = kafkaConfig.Validate(); err != nil {
msg := fmt.Sprintf("Kafka producer config invalidate. err: %v", err)
fmt.Println(msg)
panic(msg)
}
// 设置 Kafka 实例访问地址
producer, err = sarama.NewSyncProducer([]string{"alikafka-pre-cn-xxx-1.alikafka.aliyuncs.com:9093","alikafka-pre-cn-xxx-2.alikafka.aliyuncs.com:9093","alikafka-pre-cn-xxx-3.alikafka.aliyuncs.com:9093"}, kafkaConfig)
if err != nil {
msg := fmt.Sprintf("Kafak producer create fail. err: %v", err)
fmt.Println(msg)
panic(msg)
}
}
func main() {
// 模拟并发50,持续100s, 发送消息
for i := 1; i <= 100; i++ {
for j := 0; j < 50; j++ {
key := strconv.FormatInt(time.Now().UTC().UnixNano()+int64(j), 10)
value := `{"id":12182,"template_name":"template_media/videos/templates/8f3a5f293149095aa62958029e208501_1606889936.zip","width":360,"height":640}`
go produce("demo", key, value)
}
time.Sleep(time.Second)
}
}
// Kafka 发送消息函数
func produce(topic string, key string, content string) error {
msg := &sarama.ProducerMessage{
Topic: topic,
Key: sarama.StringEncoder(key),
Value: sarama.StringEncoder(content),
Timestamp: time.Now(),
}
_, _, err := producer.SendMessage(msg)
if err != nil {
msg := fmt.Sprintf("Send Error topic: %v. key: %v. content: %v", topic, key, content)
fmt.Println(msg)
return err
}
fmt.Printf("Send OK topic:%s key:%s value:%s\n", topic, key, content)
return nil
}我们可以看到自动弹性扩容如下:

小结
Serverless Kubernetes 基于 Kubernetes 之上,提供按需使用、节点免运维、异构资源以及事件驱动等 Serverless 能力,让开发者真正实现通过 Kubernetes 标准化 API 进行 Serverless 应用编程。
常见问题
部署推理服务(test-ai-process)没有Pod创建失败。
可以查看Pod的event事件异常信息:
若指定ECI GPU规格没有库存,这时候可以调整其它GPU 规格。
若拉镜像失败,需要开通NAT访问公网。
模拟发送消息,Pod实例没有触发自动扩所容。
Kafka创建的实例需要与ACK Serverless集群属于同一个VPC,并且kafka实例白名单需要设置:
0.0.0.0/0。