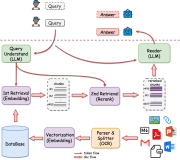
RAG
检索增强生成(Retrieval Augmented Generation),简称 RAG。是通过自有垂域数据库检索相关信息,然后合并成为提示模板,给大模型生成漂亮的回答。
想必大家对大模型的能力有了一定的了解,但是当我们将大模型应用于实际业务场景时会发现,通用的基础大模型基本无法满足我们的实际业务需求,主要有以下几方面原因:
- 知识的局限性:模型自身的知识完全源于它的训练数据,而现有的主流大模型的训练集基本都是构建于网络公开的数据,对于一些实时性的、非公开的或离线的数据是无法获取到的,这部分知识也就无从具备。
- 幻觉问题:所有的AI模型的底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,大模型也不例外,所以它有时候会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的场景。而这种幻觉问题的区分是比较困难的,因为它要求使用者自身具备相应领域的知识。
- 数据安全性:对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。
而RAG是解决上述问题的一套有效方案。
一句话总结:RAG(中文为检索增强生成) = 检索技术 + LLM 提示。例如,我们向 LLM 提问一个问题(answer),RAG 从各种数据源检索相关的信息,并将检索到的信息和问题(answer)注入到 LLM 提示中,LLM 最后给出答案。
RAG 是2023年基于 LLM 的系统中最受欢迎的架构。许多产品基于 RAG 构建,从基于 web 搜索引擎和 LLM 的问答服务到使用私有数据的chat应用程序。
尽管在2019年,Faiss 就实现了基于嵌入的向量搜索技术,但是 RAG 推动了向量搜索领域的发展。
在这个过程中,有两个主要步骤:语义搜索和生成输出。在语义搜索步骤中,我们希望从我们的知识库中找到与我们要回答的查询最相关的部分内容。然后,在生成步骤中,我们将使用这些内容来生成响应。
RAG实现过程
目前我们已经知道RAG融合是一种用于(可能)提升RAG应用检索阶段的技术。
基本上,主要思路就是利用LLM来生成多个查询,期望能够通过这些查询让问题的各个方面在上下文中显现出来。之后你可以使用生成的查询进行向量搜索(如本系列之前的部分所述),并且基于其在结果集中的显示方式来对内容进行重新排序。
RAG架构
RAG的架构如图中所示,简单来讲,RAG就是通过检索获取相关的知识并将其融入Prompt,让大模型能够参考相应的知识从而给出合理回答。因此,可以将RAG的核心理解为“检索+生成”,前者主要是利用向量数据库的高效存储和检索能力,召回目标知识;后者则是利用大模型和Prompt工程,将召回的知识合理利用,生成目标答案。
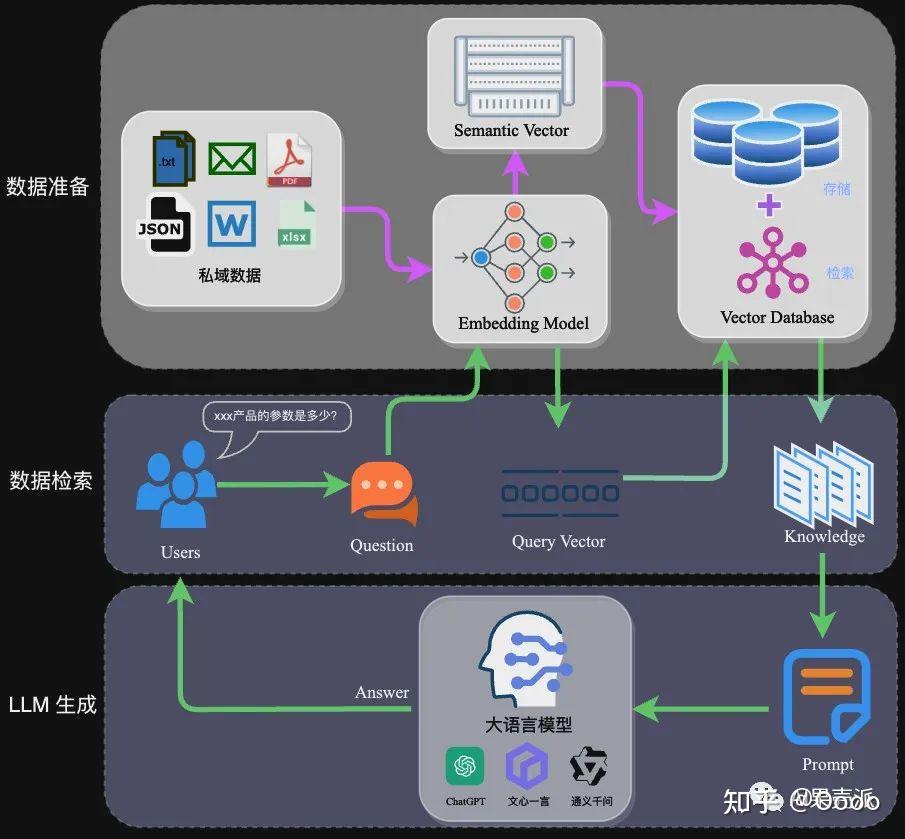
完整的RAG应用流程主要包含两个阶段:
- 数据准备阶段:数据提取——>文本分割——>向量化(embedding)——>数据入库
- 应用阶段:用户提问——>数据检索(召回)——>注入Prompt——>LLM生成答案
数据准备阶段
数据准备一般是一个离线的过程,主要是将私域数据向量化后构建索引并存入数据库的过程。主要包括:数据提取、文本分割、向量化、数据入库等环节。

数据准备
- 数据提取
- 数据加载:包括多格式数据加载、不同数据源获取等,根据数据自身情况,将数据处理为同一个范式。
- 数据处理:包括数据过滤、压缩、格式化等。
- 元数据获取:提取数据中关键信息,例如文件名、Title、时间等 。
- 文本分割:
文本分割主要考虑两个因素:1)embedding模型的Tokens限制情况;2)语义完整性对整体的检索效果的影响。一些常见的文本分割方式如下:
- 句分割:以”句”的粒度进行切分,保留一个句子的完整语义。常见切分符包括:句号、感叹号、问号、换行符等。
- 固定长度分割:根据embedding模型的token长度限制,将文本分割为固定长度(例如256/512个tokens),这种切分方式会损失很多语义信息,一般通过在头尾增加一定冗余量来缓解。
- 向量化(embedding):
向量化是一个将文本数据转化为向量矩阵的过程,该过程会直接影响到后续检索的效果。
免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector

- 数据入库:
数据向量化后构建索引,并写入数据库的过程可以概述为数据入库过程,适用于RAG场景的数据库包括:FAISS、Chromadb、ES、milvus等。一般可以根据业务场景、硬件、性能需求等多因素综合考虑,选择合适的数据库。
高级 RAG
现在我们深入讲解高级 RAG 技术。包括所涉及的核心步骤和算法的方案,但是省略了一些逻辑循环和复杂的多步代理行为,以保持方案的可读性。

1:分块 (Chunking) & 向量化 (Vectorisation)
- 分块 (Chunking)
- 向量化 (Vectorisation)
2. 搜索索引
- 向量存储索引
- 分层索引
- 假设性问题和 HyDE
- 内容增强
4. 查询转换
5. 聊天引擎
6. 查询路由
7. 智能体(Agent)
8. 响应合成
这是任何 RAG 管道的最后一步——根据我们检索的所有上下文和初始用户查询生成答案。
总结
RAG 系统性能评估的多个框架,都包含了几项独立的指标,例如总体答案相关性、答案基础性、忠实度和检索到的上下文相关性。
RAG融合是一个强大的功能,能够提高RAG应用的语义搜索效率。通过使用语言模型生成多个查询并对搜索结果进行重新排序,RAG融合可以呈现更丰富多样的内容,并提供了一个额外的层次,用于调整应用。此外,RAG融合还可以实现自动纠正、节省成本以及增加内容多样性。但是,需要注意一些权衡,比如潜在的延迟问题、自动纠正的挑战以及成本影响。对于依赖常见概念但可能出现内部行话或重叠词汇的应用来说,RAG融合尤其有用。重要的是要评估RAG融合的表现并测量其影响,以确定它是否适合特定应用场景。