流畅的 Python 第二版(GPT 重译)(十)(3)https://developer.aliyun.com/article/1484734
示例 19-12. sequential.py:小数据集的顺序素性检查
#!/usr/bin/env python3 """ sequential.py: baseline for comparing sequential, multiprocessing, and threading code for CPU-intensive work. """ from time import perf_counter from typing import NamedTuple from primes import is_prime, NUMBERS class Result(NamedTuple): # ① prime: bool elapsed: float def check(n: int) -> Result: # ② t0 = perf_counter() prime = is_prime(n) return Result(prime, perf_counter() - t0) def main() -> None: print(f'Checking {len(NUMBERS)} numbers sequentially:') t0 = perf_counter() for n in NUMBERS: # ③ prime, elapsed = check(n) label = 'P' if prime else ' ' print(f'{n:16} {label} {elapsed:9.6f}s') elapsed = perf_counter() - t0 # ④ print(f'Total time: {elapsed:.2f}s') if __name__ == '__main__': main()
①
check 函数(在下一个 callout 中)返回一个带有 is_prime 调用的布尔值和经过时间的 Result 元组。
②
check(n) 调用 is_prime(n) 并计算经过的时间以返回一个 Result。
③
对于样本中的每个数字,我们调用 check 并显示结果。
④
计算并显示总经过时间。
基于进程的解决方案
下一个示例 procs.py 展示了使用多个进程将素性检查分布到多个 CPU 核心上。这是我用 procs.py 得到的时间:
$ python3 procs.py Checking 20 numbers with 12 processes: 2 P 0.000002s 3333333333333333 0.000021s 4444444444444444 0.000002s 5555555555555555 0.000018s 6666666666666666 0.000002s 142702110479723 P 1.350982s 7777777777777777 0.000009s 299593572317531 P 1.981411s 9999999999999999 0.000008s 3333333333333301 P 6.328173s 3333335652092209 6.419249s 4444444488888889 7.051267s 4444444444444423 P 7.122004s 5555553133149889 7.412735s 5555555555555503 P 7.603327s 6666666666666719 P 7.934670s 6666667141414921 8.017599s 7777777536340681 8.339623s 7777777777777753 P 8.388859s 9999999999999917 P 8.117313s 20 checks in 9.58s
输出的最后一行显示 procs.py 比 sequential.py 快了 4.2 倍。
理解经过时间
请注意,第一列中的经过时间是用于检查该特定数字的。例如,is_prime(7777777777777753) 几乎花费了 8.4 秒才返回 True。同时,其他进程正在并行检查其他数字。
有 20 个数字需要检查。我编写了 procs.py 来启动与 CPU 核心数量相等的工作进程,这个数量由 multiprocessing.cpu_count() 确定。
在这种情况下,总时间远远小于各个检查的经过时间之和。在启动进程和进程间通信中存在一些开销,因此最终结果是多进程版本仅比顺序版本快约 4.2 倍。这很好,但考虑到代码启动了 12 个进程以利用笔记本电脑上的所有核心,有点令人失望。
注意
multiprocessing.cpu_count()函数在我用来撰写本章的 MacBook Pro 上返回12。实际上是一个 6-CPU Core-i7,但由于超线程技术,操作系统报告有 12 个 CPU,每个核心执行 2 个线程。然而,当一个线程不像同一核心中的另一个线程那样努力工作时,超线程效果更好——也许第一个在缓存未命中后等待数据,而另一个在进行数字计算。无论如何,没有免费午餐:这台笔记本电脑在不使用大量内存的计算密集型工作中表现得像一台 6-CPU 机器,比如简单的素数测试。
多核素数检查的代码
当我们将计算委托给线程或进程时,我们的代码不会直接调用工作函数,因此我们不能简单地获得返回值。相反,工作由线程或进程库驱动,并最终产生需要存储的结果。协调工作人员和收集结果是并发编程中常见队列的用途,也是分布式系统中的用途。
procs.py中的许多新代码涉及设置和使用队列。文件顶部在示例 19-13 中。
警告
SimpleQueue在 Python 3.9 中添加到multiprocessing中。如果您使用的是早期版本的 Python,可以在示例 19-13 中用Queue替换SimpleQueue。
示例 19-13。procs.py:多进程素数检查;导入、类型和函数
import sys from time import perf_counter from typing import NamedTuple from multiprocessing import Process, SimpleQueue, cpu_count # ① from multiprocessing import queues # ② from primes import is_prime, NUMBERS class PrimeResult(NamedTuple): # ③ n: int prime: bool elapsed: float JobQueue = queues.SimpleQueue[int] # ④ ResultQueue = queues.SimpleQueue[PrimeResult] # ⑤ def check(n: int) -> PrimeResult: # ⑥ t0 = perf_counter() res = is_prime(n) return PrimeResult(n, res, perf_counter() - t0) def worker(jobs: JobQueue, results: ResultQueue) -> None: # ⑦ while n := jobs.get(): # ⑧ results.put(check(n)) # ⑨ results.put(PrimeResult(0, False, 0.0)) # ⑩ def start_jobs( procs: int, jobs: JobQueue, results: ResultQueue ⑪ ) -> None: for n in NUMBERS: jobs.put(n) ⑫ for _ in range(procs): proc = Process(target=worker, args=(jobs, results)) ⑬ proc.start() ⑭ jobs.put(0) ⑮
①
尝试模拟threading,multiprocessing提供multiprocessing.SimpleQueue,但这是绑定到预定义实例的低级BaseContext类的方法。我们必须调用这个SimpleQueue来构建一个队列,不能在类型提示中使用它。
②
multiprocessing.queues有我们在类型提示中需要的SimpleQueue类。
③
PrimeResult包括检查素数的数字。将n与其他结果字段一起保持简化后续显示结果。
④
这是main函数将用于向执行工作的进程发送数字的SimpleQueue的类型别名。
⑤
第二个将在main中收集结果的SimpleQueue的类型别名。队列中的值将是由要测试素数的数字和一个Result元组组成的元组。
⑥
这类似于sequential.py。
⑦
worker获取一个包含要检查的数字的队列,另一个用于放置结果。
⑧
在这段代码中,我使用数字0作为毒丸:一个信号,告诉工作进程完成。如果n不是0,则继续循环。¹⁴
⑨
调用素数检查并将PrimeResult入队。
⑩
发回一个PrimeResult(0, False, 0.0),以让主循环知道这个工作进程已完成。
⑪
procs是将并行计算素数检查的进程数。
⑫
将要检查的数字入队到jobs中。
⑬
为每个工作进程分叉一个子进程。每个子进程将在其自己的worker函数实例内运行循环,直到从jobs队列中获取0。
⑭
启动每个子进程。
⑮
为每个进程入队一个0,以终止它们。
现在让我们来研究procs.py中的main函数在示例 19-14 中。
示例 19-14. procs.py:多进程素数检查;main函数
def main() -> None: if len(sys.argv) < 2: # ① procs = cpu_count() else: procs = int(sys.argv[1]) print(f'Checking {len(NUMBERS)} numbers with {procs} processes:') t0 = perf_counter() jobs: JobQueue = SimpleQueue() # ② results: ResultQueue = SimpleQueue() start_jobs(procs, jobs, results) # ③ checked = report(procs, results) # ④ elapsed = perf_counter() - t0 print(f'{checked} checks in {elapsed:.2f}s') # ⑤ def report(procs: int, results: ResultQueue) -> int: # ⑥ checked = 0 procs_done = 0 while procs_done < procs: # ⑦ n, prime, elapsed = results.get() # ⑧ if n == 0: # ⑨ procs_done += 1 else: checked += 1 # ⑩ label = 'P' if prime else ' ' print(f'{n:16} {label} {elapsed:9.6f}s') return checked if __name__ == '__main__': main()
①
如果没有给出命令行参数,则将进程数量设置为 CPU 核心数;否则,根据第一个参数创建相同数量的进程。
②
jobs和results是示例 19-13 中描述的队列。
③
启动proc进程来消费jobs并发布results。
④
检索结果并显示它们;report在⑥中定义。
⑤
显示检查的数字数量和总经过时间。
⑥
参数是procs的数量和用于发布结果的队列。
⑦
循环直到所有进程完成。
⑧
获取一个PrimeResult。在队列上调用.get()会阻塞,直到队列中有一个项目。也可以将其设置为非阻塞,或设置超时。有关详细信息,请参阅SimpleQueue.get文档。
⑨
如果n为零,则一个进程退出;增加procs_done计数。
⑩
否则,增加checked计数(以跟踪检查的数字)并显示结果。
结果将不会按照提交作业的顺序返回。这就是为什么我必须在每个PrimeResult元组中放入n。否则,我将无法知道哪个结果属于每个数字。
如果主进程在所有子进程完成之前退出,则可能会看到由multiprocessing中的内部锁引起的FileNotFoundError异常的令人困惑的回溯。调试并发代码总是困难的,而调试multiprocessing更加困难,因为在类似线程的外观背后有着复杂性。幸运的是,我们将在第二十章中遇到的ProcessPoolExecutor更易于使用且更健壮。
注意
感谢读者 Michael Albert 注意到我在早期发布时发布的代码在示例 19-14 中有一个竞争条件。竞争条件是一个可能发生也可能不发生的错误,取决于并发执行单元执行操作的顺序。如果“A”发生在“B”之前,一切都很好;但如果“B”先发生,就会出现问题。这就是竞争条件。
如果你感兴趣,这个差异显示了错误以及我如何修复它:example-code-2e/commit/2c123057—但请注意,我后来重构了示例,将main的部分委托给start_jobs和report函数。在同一目录中有一个README.md文件解释了问题和解决方案。
尝试使用更多或更少的进程
你可能想尝试运行procs.py,传递参数来设置工作进程的数量。例如,这个命令…
$ python3 procs.py 2
…将启动两个工作进程,几乎比sequential.py快两倍—如果您的计算机至少有两个核心并且没有太忙于运行其他程序。
我用 1 到 20 个进程运行了procs.py 12 次,总共 240 次运行。然后我计算了相同进程数量的所有运行的中位时间,并绘制了图 19-2。
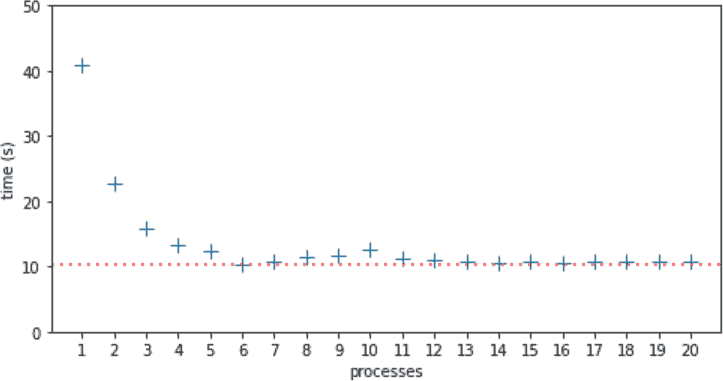
图 19-2。每个进程数的中位运行时间从 1 到 20。1 个进程的最长中位时间为 40.81 秒。6 个进程的最短中位时间为 10.39 秒,由虚线表示。
在这台 6 核笔记本电脑中,6 个进程的最短中位时间为 10.39 秒,由图 19-2 中的虚线标记。我预计在 6 个进程后运行时间会增加,因为 CPU 争用,而在 10 个进程时达到 12.51 秒的局部最大值。我没有预料到,也无法解释为什么在 11 个进程时性能有所提高,并且从 13 到 20 个进程时几乎保持不变,中位时间仅略高于 6 个进程的最低中位时间。
基于线程的非解决方案
我还编写了threads.py,这是使用threading而不是multiprocessing的procs.py版本。代码非常相似——在将这两个 API 之间的简单示例转换时通常是这种情况。¹⁶ 由于 GIL 和is_prime的计算密集型特性,线程版本比示例 19-12 中的顺序代码慢,并且随着线程数量的增加而变慢,因为 CPU 争用和上下文切换的成本。要切换到新线程,操作系统需要保存 CPU 寄存器并更新程序计数器和堆栈指针,触发昂贵的副作用,如使 CPU 缓存失效,甚至可能交换内存页面。¹⁷
接下来的两章将更多地介绍 Python 中的并发编程,使用高级concurrent.futures库来管理线程和进程(第二十章)以及asyncio库用于异步编程(第二十一章)。
本章的其余部分旨在回答以下问题:
鉴于迄今为止讨论的限制,Python 如何在多核世界中蓬勃发展?
Python 在多核世界中
请考虑这段引用自广为引用的文章“软件中的并发:免费午餐已经结束”(作者:Herb Sutter):
从英特尔和 AMD 到 Sparc 和 PowerPC 等主要处理器制造商和架构,他们几乎用尽了传统方法来提升 CPU 性能的空间。他们不再试图提高时钟速度和直线指令吞吐量,而是大规模转向超线程和多核架构。2005 年 3 月。[在线提供]。
Sutter 所说的“免费午餐”是软件随着时间推移变得更快,而无需额外的开发人员努力的趋势,因为 CPU 一直在以更快的速度执行指令代码。自 2004 年以来,这种情况不再成立:时钟速度和执行优化已经达到瓶颈,现在任何显著的性能提升都必须来自于利用多核或超线程,这些进步只有为并发执行编写的代码才能受益。
Python 的故事始于 20 世纪 90 年代初,当时 CPU 仍在以指令代码执行的方式呈指数级增长。当时除了超级计算机外,几乎没有人谈论多核 CPU。当时,决定使用 GIL 是理所当然的。GIL 使解释器在单核运行时更快,其实现更简单。¹⁸ GIL 还使得通过 Python/C API 编写简单扩展变得更容易。
注意
我之所以写“简单扩展”,是因为扩展根本不需要处理 GIL。用 C 或 Fortran 编写的函数可能比 Python 中的等效函数快几百倍。¹⁹ 因此,在许多情况下,可能不需要释放 GIL 以利用多核 CPU 的增加复杂性。因此,我们可以感谢 GIL 为 Python 提供了许多扩展,这无疑是该语言如今如此受欢迎的关键原因之一。
尽管有全局解释器锁(GIL),Python 在需要并发或并行执行的应用程序中蓬勃发展,这要归功于绕过 CPython 限制的库和软件架构。
现在让我们讨论 Python 在 2021 年多核、分布式计算世界中的系统管理、数据科学和服务器端应用开发中的应用。
系统管理
Python 被广泛用于管理大量服务器、路由器、负载均衡器和网络附加存储(NAS)。它也是软件定义网络(SDN)和道德黑客的主要选择。主要的云服务提供商通过由提供者自己或由他们庞大的 Python 用户社区编写的库和教程来支持 Python。
在这个领域,Python 脚本通过向远程机器发出命令来自动化配置任务,因此很少有需要进行 CPU 绑定操作。线程或协程非常适合这样的工作。特别是,我们将在第二十章中看到的concurrent.futures包可以用于同时在许多远程机器上执行相同的操作,而不需要太多复杂性。
除了标准库之外,还有一些流行的基于 Python 的项目用于管理服务器集群:像Ansible和Salt这样的工具,以及像Fabric这样的库。
还有越来越多支持协程和asyncio的系统管理库。2016 年,Facebook 的生产工程团队报告:“我们越来越依赖于 AsyncIO,这是在 Python 3.4 中引入的,并且在将代码库从 Python 2 迁移时看到了巨大的性能提升。”
数据科学
数据科学—包括人工智能—和科学计算非常适合 Python。这些领域的应用程序需要大量计算,但 Python 用户受益于一个庞大的用 C、C++、Fortran、Cython 等编写的数值计算库生态系统—其中许多能够利用多核机器、GPU 和/或异构集群中的分布式并行计算。
截至 2021 年,Python 的数据科学生态系统包括令人印象深刻的工具,例如:
两个基于浏览器的界面—Jupyter Notebook 和 JupyterLab—允许用户在远程机器上运行和记录潜在跨网络运行的分析代码。两者都是混合 Python/JavaScript 应用程序,支持用不同语言编写的计算内核,通过 ZeroMQ 集成—一种用于分布式应用的异步消息传递库。Jupyter这个名字实际上来自于 Julia、Python 和 R,这三种是 Notebook 支持的第一批语言。建立在 Jupyter 工具之上的丰富生态系统包括Bokeh,一个强大的交互式可视化库,让用户能够浏览和与大型数据集或持续更新的流数据进行交互,得益于现代 JavaScript 引擎和浏览器的性能。
根据O’Reilly 2021 年 1 月报告,这是两个顶尖的深度学习框架,根据他们在 2020 年学习资源使用情况。这两个项目都是用 C++编写的,并且能够利用多核、GPU 和集群。它们也支持其他语言,但 Python 是它们的主要关注点,也是大多数用户使用的语言。TensorFlow 由 Google 内部创建和使用;PyTorch 由 Facebook 创建。
一个并行计算库,可以将工作分配给本地进程或机器集群,“在世界上一些最大的超级计算机上进行了测试”——正如他们的主页所述。Dask 提供了紧密模拟 NumPy、pandas 和 scikit-learn 的 API——这些是当今数据科学和机器学习中最流行的库。Dask 可以从 JupyterLab 或 Jupyter Notebook 中使用,并利用 Bokeh 不仅用于数据可视化,还用于显示数据和计算在进程/机器之间的流动的交互式仪表板,几乎实时地展示。Dask 如此令人印象深刻,我建议观看像这样的15 分钟演示视频,其中项目的维护者之一 Matthew Rocklin 展示了 Dask 在 AWS 上的 8 台 EC2 机器上的 64 个核心上处理数据的情况。
这些只是一些例子,说明数据科学界正在创造利用 Python 最佳优势并克服 CPython 运行时限制的解决方案。
服务器端 Web/Mobile 开发
Python 在 Web 应用程序和支持移动应用程序的后端 API 中被广泛使用。谷歌、YouTube、Dropbox、Instagram、Quora 和 Reddit 等公司是如何构建 Python 服务器端应用程序,为数亿用户提供 24x7 服务的?答案远远超出了 Python “开箱即用”提供的范围。
在讨论支持 Python 大规模应用的工具之前,我必须引用 Thoughtworks Technology Radar 中的一句警告:
高性能嫉妒/Web 规模嫉妒
我们看到许多团队陷入困境,因为他们选择了复杂的工具、框架或架构,因为他们可能需要扩展”。像 Twitter 和 Netflix 这样的公司需要支持极端负载,因此需要这些架构,但他们也有极其熟练的开发团队能够处理复杂性。大多数情况并不需要这种工程壮举;团队应该控制他们对Web 规模的嫉妒,而选择简单的解决方案来完成工作[²⁰]。
在Web 规模上,关键是允许横向扩展的架构。在那一点上,所有系统都是分布式系统,没有单一的编程语言可能适合解决方案的每个部分。
分布式系统是一个学术研究领域,但幸运的是一些从业者已经写了一些基于扎实研究和实践经验的易懂的书籍。其中之一是 Martin Kleppmann,他是《设计数据密集型应用》(O’Reilly)的作者。
考虑 Kleppmann 的书中的第 19-3 图,这是许多架构图中的第一个。以下是我在参与的 Python 项目中看到或拥有第一手知识的一些组件:
- 应用程序缓存:[²¹] memcached,Redis,Varnish
- 关系型数据库:PostgreSQL,MySQL
- 文档数据库:Apache CouchDB,MongoDB
- 全文索引:Elasticsearch,Apache Solr
- 消息队列:RabbitMQ,Redis

图 19-3. 一个可能的结合多个组件的系统架构[²²]
在每个类别中还有其他工业级开源产品。主要云服务提供商也提供了他们自己的专有替代方案。
Kleppmann 的图是通用的,与语言无关——就像他的书一样。对于 Python 服务器端应用程序,通常部署了两个特定组件:
- 一个应用服务器,用于在几个 Python 应用程序实例之间分发负载。应用服务器将出现在图 19-3 中的顶部,处理客户端请求,然后再到达应用程序代码。
- 建立在图 19-3 右侧的消息队列周围的任务队列,提供了一个更高级、更易于使用的 API,将任务分发给在其他机器上运行的进程。
接下来的两节探讨了这些组件,在 Python 服务器端部署中被推荐为最佳实践。
WSGI 应用程序服务器
WSGI——Web 服务器网关接口——是 Python 框架或应用程序接收来自 HTTP 服务器的请求并向其发送响应的标准 API。²³ WSGI 应用程序服务器管理一个或多个运行应用程序的进程,最大限度地利用可用的 CPU。
图 19-4 说明了一个典型的 WSGI 部署。
提示
如果我们想要合并前面一对图表,图 19-4 中虚线矩形的内容将取代 图 19-3 顶部的实线“应用程序代码”矩形。
Python web 项目中最知名的应用程序服务器有:
对于 Apache HTTP 服务器的用户,mod_wsgi 是最佳选择。它与 WSGI 一样古老,但仍在积极维护。并且现在提供了一个名为 mod_wsgi-express 的命令行启动器,使其更易于配置,并更适合在 Docker 容器中使用。

图 19-4. 客户端连接到一个 HTTP 服务器,该服务器提供静态文件并将其他请求路由到应用程序服务器,后者分叉子进程来运行应用程序代码,利用多个 CPU 核心。WSGI API 是应用程序服务器和 Python 应用程序代码之间的粘合剂。
uWSGI 和 Gunicorn 是我所知道的最近项目中的首选。两者通常与 NGINX HTTP 服务器一起使用。uWSGI 提供了许多额外功能,包括应用程序缓存、任务队列、类似 cron 的定期任务以及许多其他功能。然而,与 Gunicorn 相比,uWSGI 要难以正确配置得多。²⁵
2018 年发布的 NGINX Unit 是著名 NGINX HTTP 服务器和反向代理的制造商推出的新产品。
mod_wsgi 和 Gunicorn 仅支持 Python web 应用程序,而 uWSGI 和 NGINX Unit 也可以与其他语言一起使用。请浏览它们的文档以了解更多信息。
主要观点:所有这些应用程序服务器都可以通过分叉多个 Python 进程来使用服务器上的所有 CPU 核心,以运行传统的使用旧的顺序代码编写的 Web 应用程序,如 Django、Flask、Pyramid 等。这就解释了为什么可以作为 Python web 开发人员谋生,而无需学习 threading、multiprocessing 或 asyncio 模块:应用程序服务器会透明地处理并发。
ASGI——异步服务器网关接口
WSGI 是一个同步 API。它不支持使用 async/await 实现 WebSockets 或 HTTP 长轮询的协程——这是在 Python 中实现最有效的方法。ASGI 规范 是 WSGI 的继任者,专为异步 Python web 框架设计,如 aiohttp、Sanic、FastAPI 等,以及逐渐添加异步功能的 Django 和 Flask。
现在让我们转向另一种绕过 GIL 以实现更高性能的服务器端 Python 应用程序的方法。
分布式任务队列
当应用服务器将请求传递给运行您代码的 Python 进程之一时,您的应用需要快速响应:您希望进程尽快可用以处理下一个请求。但是,某些请求需要执行可能需要较长时间的操作,例如发送电子邮件或生成 PDF。这就是分布式任务队列旨在解决的问题。
Celery 和 RQ 是最知名的具有 Python API 的开源任务队列。云服务提供商也提供他们自己的专有任务队列。
这些产品包装了一个消息队列,并提供了一个高级 API,用于将任务委托给工作者,可能在不同的机器上运行。
注意
在任务队列的背景下,使用 生产者 和 消费者 这两个词,而不是传统的客户端/服务器术语。例如,Django 视图处理程序生成作业请求,这些请求被放入队列中,以便由一个或多个 PDF 渲染进程消耗。
直接引用自 Celery 的 FAQ,以下是一些典型的用例:
- 在后台运行某些东西。例如,尽快完成网页请求,然后逐步更新用户页面。这给用户留下了良好性能和“灵敏度”的印象,即使实际工作可能需要一些时间。
- 在网页请求完成后运行某些内容。
- 确保某事已完成,通过异步执行并使用重试。
- 定期调度工作。
除了解决这些直接问题外,任务队列还支持水平扩展。生产者和消费者是解耦的:生产者不调用消费者,而是将请求放入队列中。消费者不需要了解生产者的任何信息(但如果需要确认,则请求可能包含有关生产者的信息)。至关重要的是,随着需求增长,您可以轻松地添加更多的工作者来消耗任务。这就是为什么 Celery 和 RQ 被称为分布式任务队列。
回想一下,我们简单的procs.py(示例 19-13)使用了两个队列:一个用于作业请求,另一个用于收集结果。Celery 和 RQ 的分布式架构使用了类似的模式。两者都支持使用 Redis NoSQL 数据库作为消息队列和结果存储。Celery 还支持其他消息队列,如 RabbitMQ 或 Amazon SQS,以及其他数据库用于结果存储。
这就结束了我们对 Python 中并发性的介绍。接下来的两章将继续这个主题,重点关注标准库中的 concurrent.futures 和 asyncio 包。
章节总结
经过一点理论,本章介绍了在 Python 的三种本机并发编程模型中实现的旋转器脚本:
- 线程,使用
threading包 - 进程,使用
multiprocessing - 使用
asyncio进行异步协程
然后,我们通过一个实验探讨了 GIL 的真正影响:将旋转器示例更改为计算大整数的素性,并观察结果行为。这直观地证明了 CPU 密集型函数必须在 asyncio 中避免,因为它们会阻塞事件循环。尽管 GIL 的存在,线程版本的实验仍然有效,因为 Python 周期性地中断线程,而且示例仅使用了两个线程:一个执行计算密集型工作,另一个每秒仅驱动动画 10 次。multiprocessing 变体绕过了 GIL,为动画启动了一个新进程,而主进程则执行素性检查。
下一个示例,计算多个素数,突出了 multiprocessing 和 threading 之间的区别,证明只有进程才能让 Python 受益于多核 CPU。Python 的 GIL 使线程比顺序代码更糟糕,用于重型计算。
GIL 主导了关于 Python 并发和并行计算的讨论,但我们不应该过高估计其影响。这就是“Python 在多核世界中的应用”的观点。例如,GIL 并不影响 Python 在系统管理中的许多用例。另一方面,数据科学和服务器端开发社区已经通过针对其特定需求定制的工业级解决方案绕过了 GIL。最后两节提到了支持 Python 服务器端应用程序规模化的两个常见元素:WSGI 应用程序服务器和分布式任务队列。
进一步阅读
本章有一个广泛的阅读列表,因此我将其分成了子章节。
线程和进程并发
在第二十章中涵盖的concurrent.futures库在底层使用线程、进程、锁和队列,但您不会看到它们的单独实例;它们被捆绑并由ThreadPoolExecutor和ProcessPoolExecutor的更高级抽象管理。如果您想了解更多关于使用这些低级对象进行并发编程的实践,Jim Anderson 的“Python 中的线程简介”是一个很好的首次阅读。Doug Hellmann 在他的网站和书籍The Python 3 Standard Library by Example(Addison-Wesley)中有一章标题为“进程、线程和协程并发”的章节。
Brett Slatkin 的Effective Python,第 2 版(Addison-Wesley),David Beazley 的Python Essential Reference,第 4 版(Addison-Wesley),以及 Martelli 等人的Python in a Nutshell,第 3 版(O’Reilly)是其他涵盖threading和multiprocessing的一般 Python 参考资料。广泛的multiprocessing官方文档在其“编程指南”部分中包含有用的建议。
Jesse Noller 和 Richard Oudkerk 贡献了multiprocessing包,该包在PEP 371—将 multiprocessing 包添加到标准库中介绍。该包的官方文档是一个 93 KB 的*.rst*文件,大约 63 页,使其成为 Python 标准库中最长的章节之一。
在High Performance Python,第 2 版,(O’Reilly)中,作者 Micha Gorelick 和 Ian Ozsvald 包括了一个关于multiprocessing的章节,其中包含一个关于使用不同策略检查质数的示例,与我们的procs.py示例不同。对于每个数字,他们将可能因子的范围—从 2 到sqrt(n)—分成子范围,并让每个工作进程迭代其中一个子范围。他们的分而治之方法是科学计算应用程序的典型特征,其中数据集庞大,工作站(或集群)拥有比用户更多的 CPU 核心。在处理来自许多用户的请求的服务器端系统上,让每个进程从头到尾处理一个计算更简单、更有效—减少了进程之间的通信和协调开销。除了multiprocessing,Gorelick 和 Ozsvald 还提出了许多其他开发和部署高性能数据科学应用程序的方法,利用多个核心、GPU、集群、性能分析工具和像 Cython 和 Numba 这样的编译器。他们的最后一章,“实战经验”,是其他高性能 Python 计算从业者贡献的短案例的宝贵收集。
Advanced Python Development由 Matthew Wilkes(Apress)编写,是一本罕见的书,其中包含简短的示例来解释概念,同时展示如何构建一个准备投入生产的现实应用程序:一个类似于 DevOps 监控系统或用于分布式传感器的 IoT 数据收集器的数据聚合器。Advanced Python Development中的两章涵盖了使用threading和asyncio进行并发编程。
Jan Palach 的Parallel Programming with Python(Packt,2014)解释了并发和并行背后的核心概念,涵盖了 Python 的标准库以及Celery。
“关于线程的真相”是 Caleb Hattingh(O’Reilly)在Using Asyncio in Python第二章的标题。该章节涵盖了线程的利弊,其中包括了几位权威来源的引人注目的引用,明确指出线程的基本挑战与 Python 或 GIL 无关。引用自Using Asyncio in Python第 14 页的原文:
这些主题反复出现:
- 线程使代码难以理解。
- 线程是大规模并发(成千上万个并发任务)的一种低效模型。
如果你想通过艰难的方式了解关于线程和锁的推理有多困难——而又不用担心工作——可以尝试 Allen Downey 的练习册The Little Book of Semaphores(Green Tea Press)。Downey 书中的练习从简单到非常困难到无法解决,但即使是简单的练习也会让人大开眼界。
GIL
如果你对 GIL 感兴趣,请记住我们无法从 Python 代码中控制它,因此权威参考在 C-API 文档中:Thread State and the Global Interpreter Lock。Python Library and Extension FAQ回答了:“我们不能摆脱全局解释器锁吗?”。值得阅读的还有 Guido van Rossum 和 Jesse Noller(multiprocessing包的贡献者)的帖子,分别是“摆脱 GIL 并不容易”和“Python 线程和全局解释器锁”。
CPython Internals由 Anthony Shaw(Real Python)解释了 CPython 3 解释器在 C 编程层面的实现。 Shaw 最长的章节是“并行性和并发性”:深入探讨了 Python 对线程和进程的本机支持,包括使用 C/Python API 从扩展中管理 GIL。
最后,David Beazley 在“理解 Python GIL”中进行了详细探讨。在演示文稿的第 54 页中,Beazley 报告了在 Python 3.2 中引入的新 GIL 算法对特定基准测试处理时间的增加。根据 Antoine Pitrou 在 Beazley 提交的错误报告中的评论,在真实工作负载中,这个问题并不显著:Python 问题#7946。
超越标准库的并发
Fluent Python专注于核心语言特性和标准库的核心部分。Full Stack Python是这本书的绝佳补充:它涵盖了 Python 的生态系统,包括“开发环境”,“数据”,“Web 开发”和“DevOps”等部分。
我已经提到了两本涵盖使用 Python 标准库进行并发的书籍,它们还包括了大量关于第三方库和工具的内容:High Performance Python,第 2 版和Parallel Programming with Python。Francesco Pierfederici 的Distributed Computing with Python(Packt)涵盖了标准库以及云提供商和 HPC(高性能计算)集群的使用。
“Python,性能和 GPU”是 Matthew Rocklin 在 2019 年 6 月发布的“关于从 Python 使用 GPU 加速器的最新情况”。
“Instagram 目前拥有世界上最大规模的Django Web 框架部署,完全使用 Python 编写。”这是 Instagram 软件工程师 Min Ni 撰写的博文“在 Instagram 中使用 Python 的 Web 服务效率”的开头句。该文章描述了 Instagram 用于优化其 Python 代码库效率的指标和工具,以及在每天部署其后端“30-50 次”时检测和诊断性能回归。
由 Harry Percival 和 Bob Gregory(O’Reilly)撰写的Architecture Patterns with Python: Enabling Test-Driven Development, Domain-Driven Design, and Event-Driven Microservices介绍了 Python 服务器端应用程序的架构模式。作者还在cosmicpython.com免费提供了这本书的在线版本。
用于在进程之间并行执行任务的两个优雅且易于使用的库是由 João S. O. Bueno 开发的lelo和由 Nat Pryce 开发的python-parallelize。lelo包定义了一个@parallel装饰器,您可以将其应用于任何函数,使其神奇地变为非阻塞:当您调用装饰的函数时,它的执行将在另一个进程中开始。Nat Pryce 的python-parallelize包提供了一个parallelize生成器,将for循环的执行分布到多个 CPU 上。这两个包都构建在multiprocessing库上。
Python 核心开发者 Eric Snow 维护着一个Multicore Python维基,其中记录了他和其他人努力改进 Python 对并行执行的支持的笔记。Snow 是PEP 554—Stdlib 中的多个解释器的作者。如果得到批准并实施,PEP 554 将为未来的增强奠定基础,最终可能使 Python 能够在没有multiprocessing开销的情况下使用多个核心。其中最大的障碍之一是多个活动子解释器和假定单个解释器的扩展之间的复杂交互。
Python 维护者 Mark Shannon 还创建了一个有用的表格,比较了 Python 中的并发模型,在他、Eric Snow 和其他开发者在python-dev邮件列表上讨论子解释器时被引用。在 Shannon 的表格中,“理想的 CSP”列指的是 Tony Hoare 在 1978 年提出的理论通信顺序进程模型。Go 也允许共享对象,违反了 CSP 的一个基本约束:执行单元应通过通道进行消息传递。
Stackless Python(又名Stackless)是 CPython 的一个分支,实现了微线程,这些线程是应用级轻量级线程,而不是操作系统线程。大型多人在线游戏EVE Online是基于Stackless构建的,游戏公司CCP雇用的工程师一度是Stackless的维护者。Stackless的一些特性在Pypy解释器和greenlet包中重新实现,后者是gevent网络库的核心技术,而后者又是Gunicorn应用服务器的基础。
并发编程的演员模型是高度可扩展的 Erlang 和 Elixir 语言的核心,并且也是 Scala 和 Java 的 Akka 框架的模型。如果你想在 Python 中尝试演员模型,请查看Thespian和Pykka库。
我剩下的推荐几乎没有提到 Python,但对于对本章主题感兴趣的读者仍然相关。
超越 Python 的并发性和可扩展性
Alvaro Videla 和 Jason J. W. Williams(Manning)的RabbitMQ 实战是一本非常精心编写的介绍 RabbitMQ 和高级消息队列协议(AMQP)标准的书籍,其中包含 Python、PHP 和 Ruby 的示例。无论您的技术堆栈的其余部分如何,即使您计划在幕后使用 Celery 与 RabbitMQ,我也推荐这本书,因为它涵盖了分布式消息队列的概念、动机和模式,以及在规模上操作和调整 RabbitMQ。
阅读 Paul Butcher(Pragmatic Bookshelf)的七周七并发模型让我受益匪浅,书中有着优美的副标题当线程解开。该书的第一章介绍了使用 Java 中的线程和锁编程的核心概念和挑战。该书的其余六章致力于作者认为更好的并发和并行编程的替代方案,支持不同的语言、工具和库。示例使用了 Java、Clojure、Elixir 和 C(用于关于使用OpenCL 框架进行并行编程的章节)。CSP 模型以 Clojure 代码为例,尽管 Go 语言值得赞扬,因为它推广了这种方法。Elixir 是用于说明 actor 模型的示例的语言。一个免费提供的额外章节关于 actor 使用 Scala 和 Akka 框架。除非您已经了解 Scala,否则 Elixir 是一个更易于学习和实验 actor 模型和 Erlang/OTP 分布式系统平台的语言。
Thoughtworks 的 Unmesh Joshi 为 Martin Fowler 的博客贡献了几页关于“分布式系统模式”的文档。开篇页面是该主题的绝佳介绍,附有各个模式的链接。Joshi 正在逐步添加模式,但已有的内容蕴含了在关键任务系统中多年辛苦积累的经验。
Martin Kleppmann 的设计数据密集型应用(O’Reilly)是一本罕见的由具有深厚行业经验和高级学术背景的从业者撰写的书籍。作者在领英和两家初创公司的大规模数据基础设施上工作,然后成为剑桥大学分布式系统研究员。Kleppmann 的每一章都以大量参考文献结尾,包括最新的研究结果。该书还包括许多启发性的图表和精美的概念地图。
我很幸运能够参加 Francesco Cesarini 在 OSCON 2016 上关于可靠分布式系统架构的出色研讨会:“使用 Erlang/OTP 进行可扩展性设计和架构”(在 O’Reilly 学习平台上的视频)。尽管标题如此,视频中的 9:35 处,Cesarini 解释道:
我即将说的内容很少会是特定于 Erlang 的[…]. 事实仍然是,Erlang 将消除许多制约系统具有弹性、永不失败且可扩展性的偶发困难。因此,如果您使用 Erlang 或在 Erlang 虚拟机上运行的语言,将会更容易。
那个研讨会基于 Francesco Cesarini 和 Steve Vinoski(O’Reilly)的使用 Erlang/OTP 进行可扩展性设计的最后四章。
编写分布式系统具有挑战性和令人兴奋,但要小心web-scale envy。KISS 原则仍然是可靠的工程建议。
查看 Frank McSherry、Michael Isard 和 Derek G. Murray 撰写的论文“可扩展性!但以什么代价?”。作者们在学术研讨会中发现了需要数百个核心才能胜过“胜任的单线程实现”的并行图处理系统。他们还发现了“在所有报告的配置中都不如一个线程表现”的系统。
这些发现让我想起了一个经典的黑客警句:
我的 Perl 脚本比你的 Hadoop 集群更快。
¹ 演讲“并发不等于并行”的第 8 张幻灯片。
² 我曾与 Imre Simon 教授一起学习和工作,他喜欢说科学中有两个主要的罪过:用不同的词来表示同一件事和用一个词表示不同的事物。Imre Simon(1943-2009)是巴西计算机科学的先驱,对自动机理论做出了重要贡献,并开创了热带数学领域。他还是自由软件和自由文化的倡导者。
³ 这一部分是由我的朋友 Bruce Eckel 提出的,他是有关 Kotlin、Scala、Java 和 C++的书籍的作者。
⁴ 调用sys.getswitchinterval()以获取间隔;使用sys.setswitchinterval(s)来更改它。
⁵ 系统调用是用户代码调用操作系统内核函数的一种方式。I/O、定时器和锁是通过系统调用提供的一些内核服务。要了解更多,请阅读维基百科的“系统调用”文章。
⁶ zlib和bz2模块在Antoine Pitrou 的 python-dev 消息中被特别提到,他为 Python 3.2 贡献了时间切片 GIL 逻辑。
⁷ 来源:Beazley 的“生成器:最终领域”教程第 106 页幻灯片。
⁸ 来源:“线程对象”部分的最后一段。
⁹ Unicode 有许多对简单动画有用的字符,比如盲文图案。我使用 ASCII 字符"\|/-"来保持示例简单。
¹⁰ 信号量是一个基本构件,可用于实现其他同步机制。Python 提供了不同的信号量类,用于线程、进程和协程。我们将在“使用 asyncio.as_completed 和一个线程”中看到asyncio.Semaphore(第二十一章)。
¹¹ 感谢技术评论家 Caleb Hattingh 和 Jürgen Gmach,他们让我没有忽视greenlet和gevent。
¹² 这是一台配备有 6 核、2.2 GHz 英特尔酷睿 i7 处理器的 15 英寸 MacBook Pro 2018。
¹³ 今天这是真实的,因为你可能正在使用具有抢占式多任务的现代操作系统。NT 时代之前的 Windows 和 OSX 时代之前的 macOS 都不是“抢占式”的,因此任何进程都可以占用 100%的 CPU 并冻结整个系统。今天我们并没有完全摆脱这种问题,但请相信这位老者:这在 20 世纪 90 年代困扰着每个用户,硬重置是唯一的解决方法。
¹⁴ 在这个例子中,0是一个方便的标记。None也经常用于这个目的。使用0简化了PrimeResult的类型提示和worker的代码。
¹⁵ 在不失去我们身份的情况下幸存下来是一个相当不错的人生目标。
¹⁶ 请查看Fluent Python代码库中的19-concurrency/primes/threads.py。
¹⁷ 要了解更多,请参阅英文维基百科中的“上下文切换”。
¹⁸ 这可能是促使 Ruby 语言创始人松本行弘(Yukihiro Matsumoto)在他的解释器中使用 GIL 的相同原因。
¹⁹ 在大学的一个练习中,我不得不用 C 实现 LZW 压缩算法。但我先用 Python 写了它,以检查我对规范的理解。C 版本大约快了 900 倍。
²⁰ 来源:Thoughtworks 技术咨询委员会,《技术雷达》—2015 年 11 月。
²¹ 对比应用程序缓存—直接被应用程序代码使用—与 HTTP 缓存,它们将放置在图 19-3 的顶部边缘,用于提供静态资产如图像、CSS 和 JS 文件。内容交付网络(CDN)提供另一种类型的 HTTP 缓存,部署在更接近应用程序最终用户的数据中心。
²² 图表改编自马丁·克莱普曼(O’Reilly)的《数据密集型应用设计》第 1-1 图。
²³ 一些演讲者拼写 WSGI 首字母缩写,而其他人则将其发音为一个与“whisky”押韵的单词。
²⁴ uWSGI的拼写中“u”是小写的,但发音为希腊字母“µ”,因此整个名称听起来像“micro-whisky”,但“k”换成“g”。
²⁵ 彼得·斯佩尔(Peter Sperl)和本·格林(Ben Green)撰写了“为生产部署配置 uWSGI”,解释了uWSGI中许多默认设置对许多常见部署场景都不适用。斯佩尔在2019 年 EuroPython上介绍了他们建议的摘要。强烈推荐给uWSGI的用户。
²⁶ 卡勒布(Caleb)是Fluent Python本版的技术审查员之一。
²⁷ 感谢卢卡斯·布鲁尼亚尔蒂(Lucas Brunialti)给我发送了这个演讲链接。
²⁸ Python 的threading和concurrent.futures API 受到 Java 标准库的重大影响。
²⁹ Erlang 社区将“进程”一词用于 actors。在 Erlang 中,每个进程都是自己循环中的一个函数,因此它们非常轻量级,可以在单台机器上同时激活数百万个进程,与本章其他地方讨论的重量级操作系统进程没有关系。所以这里我们有教授西蒙描述的两种罪行的例子:使用不同的词来表示相同的事物,以及使用一个词来表示不同的事物。
