在本文中,我们将以Scikit-learn的决策树和随机森林预测NBA获胜者。美国国家篮球协会(NBA)是北美主要的男子职业篮球联赛,被广泛认为是首屈一指的男子职业篮球联赛在世界上。它有30个团队(美国29个,加拿大1个)。
在 常规赛期间,每支球队打82场比赛,每场41场。一支球队每年会有四次面对对手(16场比赛)。每个小组在其四次(24场比赛)中的其他两个小组中的六个小组中进行比赛,其余四个小组三次(12场)进行比赛。最后,每个队都会在另一场比赛中两次参加所有的球队(30场比赛)。
用决策树和随机森林预测NBA获胜者
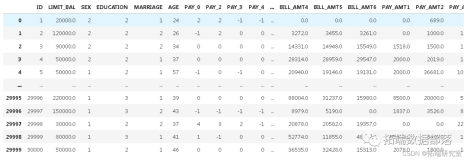
#导入数据集并解析日期导入作为
pd df = pd 。read_csv (“NBA_2017_regularGames.csv” ,parse_dates = [ “Date” ])
从游戏玩法的描述中,我们可以计算机会率。在每场比赛中,主队和客队都有可能赢得一半时间
预测类
在下面的代码中,我们将指定我们的分类类。这将帮助我们查看决策树分类器的预测是否正确。如果主队获胜,我们将指定我们的等级为1,如果访客队在另一个名为“主队赢”的列中获胜,我们将指定为0。
df [ “主队获胜” ] = df [ “访客积分” ] < df [ “主队积分” ]
主队胜率:58.4%
#该数组现在拥有scikit-learn可以读取的格式的类值。
特征工程
我们将创建以下功能来帮助我们预测NBA 2017年的获胜者。
无论是来访者还是主队都赢得了最后一场比赛。
一般认为哪个团队更好?
scikit-learn软件包实现CART(分类和回归树)算法作为其默认 决策树类
决策树实现提供了一种方法来停止构建树,以防止过度使用以下选项:
• min_samples_split
建议使用min_samples_split或min_samples_leaf来控制叶节点处的采样数。一个非常小的数字通常意味着树将过度拟合,而大量的数据将阻止树学习数据。
决策的另一个参数是创建决策的标准。基尼的不纯和信息收益是两种流行的:
• Gini impurity: measures how often a decision node would incorrectly predict a sample's class•`Information gain: indicate how much extra information is gained by the decision node
功能选择
我们通过指定我们希望使用的列并使用数据框视图的values参数,从数据集中提取要素以与我们的scikit-learn的DecisionTreeClassifier一起使用。我们使用cross_val_score函数来测试结果。
X_features_only = df [[ 'Home Win Streak' ,'Visitor Win Streak' ,'Home Team Ranks Higher' ,'Home Team Won Last' ,'Home Last Win' ,'Visitor Last Win' ]]
结果准确性:56.0%
通过选择我们制作的功能,精确度下降到56%。是否有可能通过添加更多功能来提高准确性。
混淆矩阵显示了我们决策树的正确和不正确的分类。对角线1,295分别表示主队的真正负数和真正的正数。左下角的1表示假阴性的数量。而右上角的195,误报的数量。我们也可以查看大约0.602的准确性分数,这表明决策树模型已经将60.2%的样本正确地归类为主队获胜与否。
导入pydotplus 图

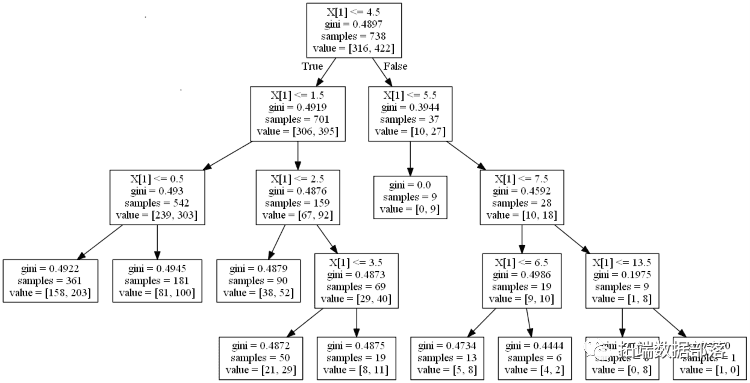
出于探索的目的,测试较少数量的变量以便首先获得决策树输出的感觉会很有帮助。最终的树开始于X的分裂,我们的第一个解释变量,主队队列更高。如果主队排名较高的值小于4.5,那么主队就会松动,因为我们的二元变量具有虚假等值亏损值和真实同赢。