Sklearn、TensorFlow 与 Keras 机器学习实用指南第三版(八)(3)https://developer.aliyun.com/article/1482463
跨多个设备并行执行
正如我们在第十二章中看到的,使用 TF 函数的一个好处是并行性。让我们更仔细地看一下这一点。当 TensorFlow 运行一个 TF 函数时,它首先分析其图形,找到需要评估的操作列表,并计算每个操作的依赖关系数量。然后 TensorFlow 将每个具有零依赖关系的操作(即每个源操作)添加到该操作设备的评估队列中(参见图 19-10)。一旦一个操作被评估,依赖于它的每个操作的依赖计数器都会减少。一旦一个操作的依赖计数器达到零,它就会被推送到其设备的评估队列中。一旦所有输出都被计算出来,它们就会被返回。
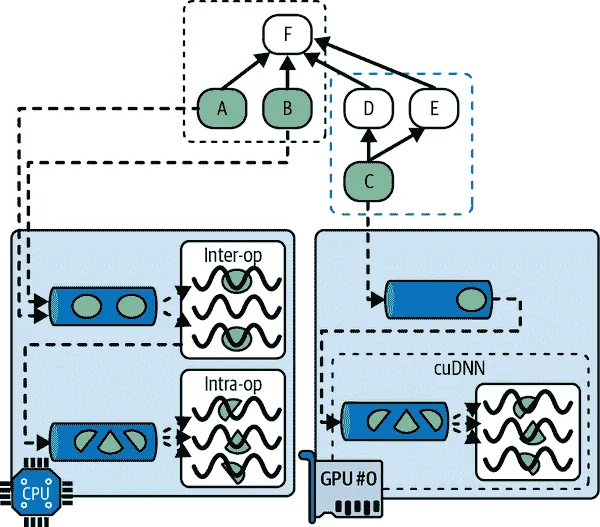
图 19-10. TensorFlow 图的并行执行
CPU 的评估队列中的操作被分派到一个称为inter-op 线程池的线程池中。如果 CPU 有多个核心,那么这些操作将有效地并行评估。一些操作具有多线程 CPU 内核:这些内核将其任务分割为多个子操作,这些子操作被放置在另一个评估队列中,并分派到一个称为intra-op 线程池的第二线程池中(由所有多线程 CPU 内核共享)。简而言之,多个操作和子操作可能在不同的 CPU 核心上并行评估。
对于 GPU 来说,情况要简单一些。GPU 的评估队列中的操作是按顺序评估的。然而,大多数操作都有多线程 GPU 内核,通常由 TensorFlow 依赖的库实现,比如 CUDA 和 cuDNN。这些实现有自己的线程池,它们通常会利用尽可能多的 GPU 线程(这就是为什么 GPU 不需要一个跨操作线程池的原因:每个操作已经占用了大部分 GPU 线程)。
例如,在图 19-10 中,操作 A、B 和 C 是源操作,因此它们可以立即被评估。操作 A 和 B 被放置在 CPU 上,因此它们被发送到 CPU 的评估队列,然后被分派到跨操作线程池并立即并行评估。操作 A 恰好有一个多线程内核;它的计算被分成三部分,在操作线程池中并行执行。操作 C 进入 GPU #0 的评估队列,在这个例子中,它的 GPU 内核恰好使用 cuDNN,它管理自己的内部操作线程池,并在许多 GPU 线程之间并行运行操作。假设 C 先完成。D 和 E 的依赖计数器被减少到 0,因此两个操作都被推送到 GPU #0 的评估队列,并按顺序执行。请注意,即使 D 和 E 都依赖于 C,C 也只被评估一次。假设 B 接下来完成。然后 F 的依赖计数器从 4 减少到 3,由于不为 0,它暂时不运行。一旦 A、D 和 E 完成,那么 F 的依赖计数器达到 0,它被推送到 CPU 的评估队列并被评估。最后,TensorFlow 返回请求的输出。
TensorFlow 执行的另一个神奇之处是当 TF 函数修改状态资源(例如变量)时:它确保执行顺序与代码中的顺序匹配,即使语句之间没有显式依赖关系。例如,如果您的 TF 函数包含v.assign_add(1),然后是v.assign(v * 2),TensorFlow 将确保这些操作按照这个顺序执行。
提示
您可以通过调用tf.config.threading.set_inter_op_parallelism_threads()来控制 inter-op 线程池中的线程数。要设置 intra-op 线程数,请使用tf.config.threading.set_intra_op_parallelism_threads()。如果您不希望 TensorFlow 使用所有 CPU 核心,或者希望它是单线程的,这将非常有用。¹²
有了这些,您就拥有了在任何设备上运行任何操作并利用 GPU 的能力所需的一切!以下是您可以做的一些事情:
- 您可以并行训练多个模型,每个模型都在自己的 GPU 上:只需为每个模型编写一个训练脚本,并在并行运行时设置
CUDA_DEVICE_ORDER和CUDA_VISIBLE_DEVICES,以便每个脚本只能看到一个 GPU 设备。这对于超参数调整非常有用,因为您可以并行训练具有不同超参数的多个模型。如果您有一台具有两个 GPU 的单台机器,并且在一个 GPU 上训练一个模型需要一个小时,那么并行训练两个模型,每个模型都在自己专用的 GPU 上,只需要一个小时。简单! - 您可以在单个 GPU 上训练一个模型,并在 CPU 上并行执行所有预处理操作,使用数据集的
prefetch()方法提前准备好接下来的几批数据,以便在 GPU 需要时立即使用(参见第十三章)。 - 如果您的模型接受两个图像作为输入,并在使用两个 CNN 处理它们之前将它们连接起来,那么如果您将每个 CNN 放在不同的 GPU 上,它可能会运行得更快。
- 您可以创建一个高效的集成:只需在每个 GPU 上放置一个不同训练过的模型,这样您就可以更快地获得所有预测结果,以生成集成的最终预测。
但是如果您想通过使用多个 GPU 加速训练呢?
在多个设备上训练模型
训练单个模型跨多个设备有两种主要方法:模型并行,其中模型在设备之间分割,和数据并行,其中模型在每个设备上复制,并且每个副本在不同的数据子集上进行训练。让我们看看这两种选择。
模型并行
到目前为止,我们已经在单个设备上训练了每个神经网络。如果我们想要在多个设备上训练单个神经网络怎么办?这需要将模型分割成单独的块,并在不同的设备上运行每个块。不幸的是,这种模型并行化实际上非常棘手,其有效性确实取决于神经网络的架构。对于全连接网络,从这种方法中通常无法获得太多好处。直觉上,似乎将模型分割的一种简单方法是将每一层放在不同的设备上,但这并不起作用,因为每一层都需要等待前一层的输出才能执行任何操作。也许你可以垂直切割它——例如,将每一层的左半部分放在一个设备上,右半部分放在另一个设备上?这样稍微好一些,因为每一层的两半确实可以并行工作,但问题在于下一层的每一半都需要上一层两半的输出,因此会有大量的跨设备通信(由虚线箭头表示)。这很可能会完全抵消并行计算的好处,因为跨设备通信速度很慢(当设备位于不同的机器上时更是如此)。
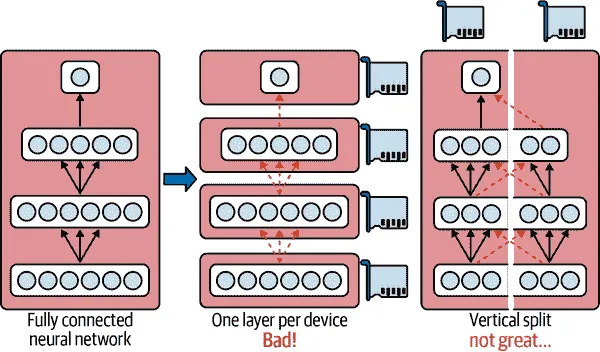
图 19-11。拆分完全连接的神经网络
一些神经网络架构,如卷积神经网络(参见第十四章),包含仅部分连接到较低层的层,因此更容易以有效的方式在设备之间分发块(参见图 19-12)。
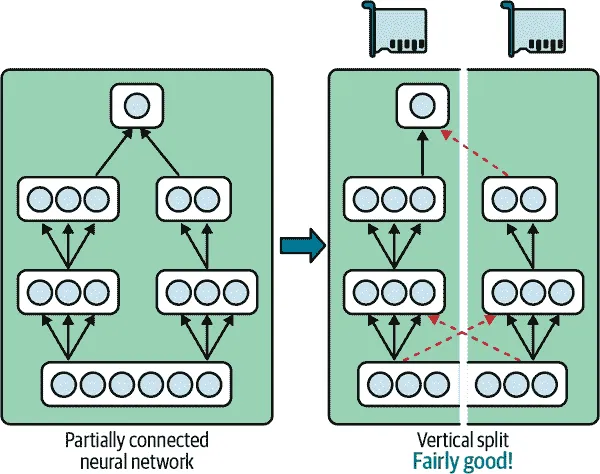
图 19-12。拆分部分连接的神经网络
深度递归神经网络(参见第十五章)可以更有效地跨多个 GPU 进行分割。如果将网络水平分割,将每一层放在不同的设备上,并将输入序列输入网络进行处理,那么在第一个时间步中只有一个设备会处于活动状态(处理序列的第一个值),在第二个时间步中两个设备会处于活动状态(第二层将处理第一层的输出值,而第一层将处理第二个值),当信号传播到输出层时,所有设备将同时处于活动状态(图 19-13)。尽管设备之间仍然存在大量的跨设备通信,但由于每个单元可能相当复杂,理论上并行运行多个单元的好处可能会超过通信惩罚。然而,在实践中,在单个 GPU 上运行的常规堆叠LSTM层实际上运行得更快。
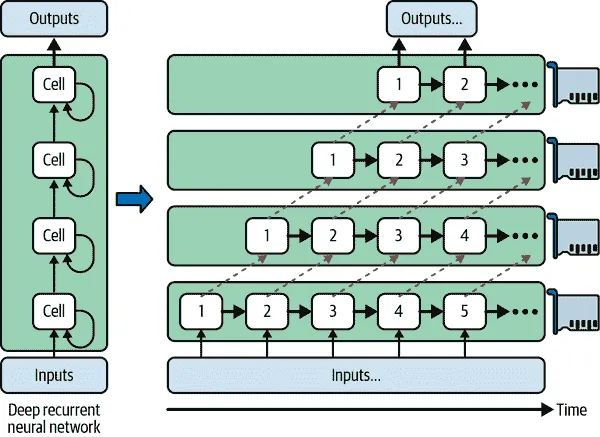
图 19-13。拆分深度递归神经网络
简而言之,模型并行可能会加快某些类型的神经网络的运行或训练速度,但并非所有类型的神经网络都适用,并且需要特别注意和调整,例如确保需要进行通信的设备在同一台机器上运行。接下来我们将看一个更简单且通常更有效的选择:数据并行。
数据并行
另一种并行训练神经网络的方法是在每个设备上复制它,并在所有副本上同时运行每个训练步骤,为每个副本使用不同的小批量。然后对每个副本计算的梯度进行平均,并将结果用于更新模型参数。这被称为数据并行,有时也称为单程序,多数据(SPMD)。这个想法有许多变体,让我们看看最重要的几种。
使用镜像策略的数据并行
可以说,最简单的方法是在所有 GPU 上完全镜像所有模型参数,并始终在每个 GPU 上应用完全相同的参数更新。这样,所有副本始终保持完全相同。这被称为镜像策略,在使用单台机器时特别高效(参见图 19-14)。
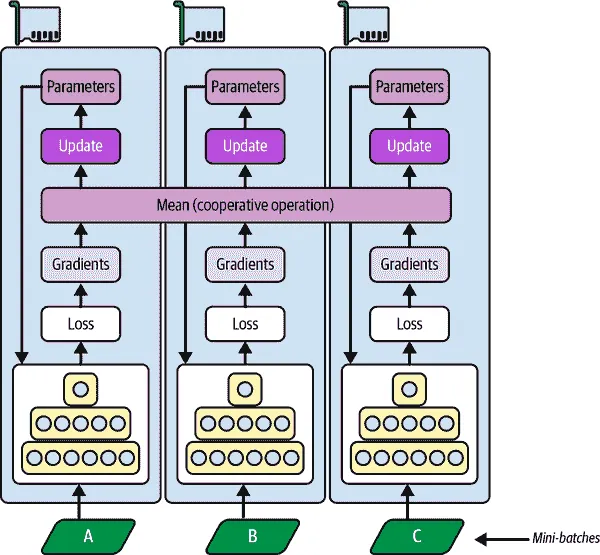
图 19-14. 使用镜像策略的数据并行
使用这种方法的棘手部分是高效地计算所有 GPU 的所有梯度的平均值,并将结果分布到所有 GPU 上。这可以使用AllReduce算法来完成,这是一类算法,多个节点合作以高效地执行reduce 操作(例如计算平均值、总和和最大值),同时确保所有节点获得相同的最终结果。幸运的是,有现成的实现这种算法,您将会看到。
集中式参数的数据并行
另一种方法是将模型参数存储在执行计算的 GPU 设备之外(称为工作器);例如,在 CPU 上(参见图 19-15)。在分布式设置中,您可以将所有参数放在一个或多个仅称为参数服务器的 CPU 服务器上,其唯一作用是托管和更新参数。
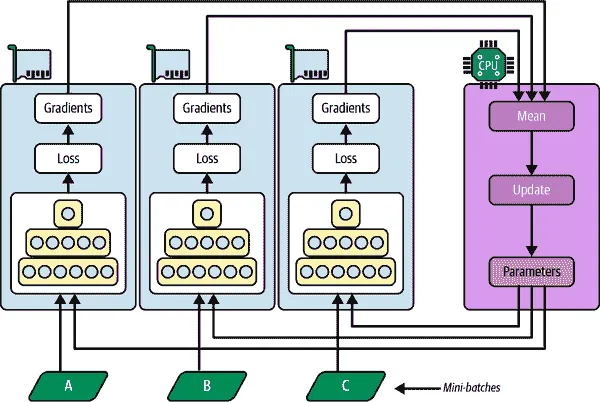
图 19-15. 集中式参数的数据并行
镜像策略强制所有 GPU 上的权重更新同步进行,而这种集中式方法允许同步或异步更新。让我们来看看这两种选择的优缺点。
同步更新
在同步更新中,聚合器会等待所有梯度可用后再计算平均梯度并将其传递给优化器,优化器将更新模型参数。一旦一个副本完成计算其梯度,它必须等待参数更新后才能继续下一个小批量。缺点是一些设备可能比其他设备慢,因此快速设备将不得不在每一步等待慢速设备,使整个过程与最慢设备一样慢。此外,参数将几乎同时复制到每个设备上(在梯度应用后立即),这可能会饱和参数服务器的带宽。
提示
为了减少每个步骤的等待时间,您可以忽略最慢几个副本(通常约 10%)的梯度。例如,您可以运行 20 个副本,但每个步骤只聚合来自最快的 18 个副本的梯度,并忽略最后 2 个的梯度。一旦参数更新,前 18 个副本可以立即开始工作,而无需等待最慢的 2 个副本。这种设置通常被描述为有 18 个副本加上 2 个备用副本。
异步更新
使用异步更新时,每当一个副本完成梯度计算后,梯度立即用于更新模型参数。没有聚合(它删除了“均值”步骤在图 19-15 中)和没有同步。副本独立于其他副本工作。由于不需要等待其他副本,这种方法每分钟可以运行更多的训练步骤。此外,尽管参数仍然需要在每一步复制到每个设备,但对于每个副本,这发生在不同的时间,因此带宽饱和的风险降低了。
使用异步更新的数据并行是一个吸引人的选择,因为它简单、没有同步延迟,并且更好地利用了带宽。然而,尽管在实践中它表现得相当不错,但它能够工作几乎令人惊讶!事实上,当一个副本基于某些参数值计算梯度完成时,这些参数将已经被其他副本多次更新(如果有N个副本,则平均更新N - 1 次),并且无法保证计算出的梯度仍然指向正确的方向(参见图 19-16)。当梯度严重过时时,它们被称为过时梯度:它们可以减慢收敛速度,引入噪声和摆动效应(学习曲线可能包含临时振荡),甚至可能使训练算法发散。
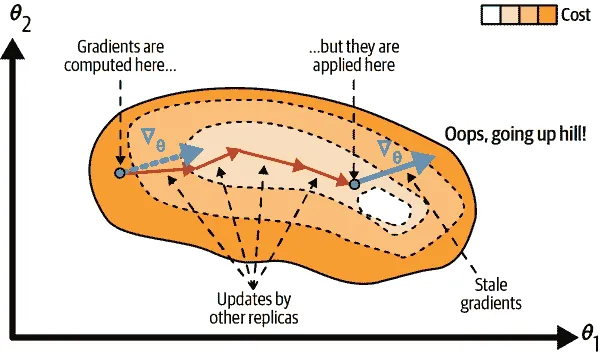
图 19-16。使用异步更新时的过时梯度
有几种方法可以减少陈旧梯度的影响:
- 降低学习率。
- 丢弃陈旧的梯度或将其缩小。
- 调整小批量大小。
- 在开始的几个时期只使用一个副本(这被称为热身阶段)。在训练开始阶段,梯度通常很大,参数还没有稳定在成本函数的谷底,因此陈旧的梯度可能会造成更大的损害,不同的副本可能会将参数推向完全不同的方向。
2016 年,Google Brain 团队发表的一篇论文对各种方法进行了基准测试,发现使用同步更新和一些备用副本比使用异步更新更有效,不仅收敛更快,而且产生了更好的模型。然而,这仍然是一个活跃的研究领域,所以你不应该立刻排除异步更新。
带宽饱和
无论您使用同步还是异步更新,具有集中参数的数据并行仍然需要在每个训练步骤开始时将模型参数从参数服务器传递到每个副本,并在每个训练步骤结束时将梯度传递到另一个方向。同样,当使用镜像策略时,每个 GPU 生成的梯度将需要与每个其他 GPU 共享。不幸的是,通常会出现这样一种情况,即添加额外的 GPU 将不会改善性能,因为将数据移入和移出 GPU RAM(以及在分布式设置中跨网络)所花费的时间将超过通过分割计算负载获得的加速效果。在那一点上,添加更多的 GPU 将只会加剧带宽饱和,并实际上减慢训练速度。
饱和对于大型密集模型来说更严重,因为它们有很多参数和梯度需要传输。对于小型模型来说,饱和程度较轻(但并行化增益有限),对于大型稀疏模型也较轻,因为梯度通常大部分为零,可以有效传输。Google Brain 项目的发起人和负责人 Jeff Dean 报告 在将计算分布到 50 个 GPU 上时,密集模型的典型加速为 25-40 倍,而在 500 个 GPU 上训练稀疏模型时,加速为 300 倍。正如你所看到的,稀疏模型确实更好地扩展。以下是一些具体例子:
- 神经机器翻译:在 8 个 GPU 上加速 6 倍
- Inception/ImageNet:在 50 个 GPU 上加速 32 倍
- RankBrain:在 500 个 GPU 上加速 300 倍
有很多研究正在进行,以缓解带宽饱和问题,目标是使训练能够与可用的 GPU 数量成线性比例扩展。例如,卡内基梅隆大学、斯坦福大学和微软研究团队在 2018 年提出了一个名为PipeDream的系统,成功将网络通信减少了 90%以上,使得可以在多台机器上训练大型模型成为可能。他们使用了一种称为管道并行的新技术来实现这一目标,该技术结合了模型并行和数据并行:模型被切分成连续的部分,称为阶段,每个阶段在不同的机器上进行训练。这导致了一个异步的管道,所有机器都在很少的空闲时间内并行工作。在训练过程中,每个阶段交替进行一轮前向传播和一轮反向传播:它从输入队列中提取一个小批量数据,处理它,并将输出发送到下一个阶段的输入队列,然后从梯度队列中提取一个小批量的梯度,反向传播这些梯度并更新自己的模型参数,并将反向传播的梯度推送到前一个阶段的梯度队列。然后它一遍又一遍地重复整个过程。每个阶段还可以独立地使用常规的数据并行(例如使用镜像策略),而不受其他阶段的影响。

图 19-17。PipeDream 的管道并行性
然而,正如在这里展示的那样,PipeDream 不会工作得那么好。要理解原因,考虑在 Figure 19-17 中的第 5 个小批次:当它在前向传递过程中经过第 1 阶段时,来自第 4 个小批次的梯度尚未通过该阶段进行反向传播,但是当第 5 个小批次的梯度流回到第 1 阶段时,第 4 个小批次的梯度将已经被用来更新模型参数,因此第 5 个小批次的梯度将有点过时。正如我们所看到的,这可能会降低训练速度和准确性,甚至使其发散:阶段越多,这个问题就会变得越糟糕。论文的作者提出了缓解这个问题的方法:例如,每个阶段在前向传播过程中保存权重,并在反向传播过程中恢复它们,以确保相同的权重用于前向传递和反向传递。这被称为权重存储。由于这一点,PipeDream 展示了令人印象深刻的扩展能力,远远超出了简单的数据并行性。
这个研究领域的最新突破是由谷歌研究人员在一篇2022 年的论文中发表的:他们开发了一个名为Pathways的系统,利用自动模型并行、异步团队调度等技术,实现了数千个 TPU 几乎 100%的硬件利用率!调度意味着组织每个任务必须运行的时间和位置,团队调度意味着同时并行运行相关任务,并且彼此靠近,以减少任务等待其他任务输出的时间。正如我们在第十六章中看到的,这个系统被用来在超过 6,000 个 TPU 上训练一个庞大的语言模型,几乎实现了 100%的硬件利用率:这是一个令人惊叹的工程壮举。
在撰写本文时,Pathways 尚未公开,但很可能在不久的将来,您将能够使用 Pathways 或类似系统在 Vertex AI 上训练大型模型。与此同时,为了减少饱和问题,您可能会希望使用一些强大的 GPU,而不是大量的弱 GPU,如果您需要在多台服务器上训练模型,您应该将 GPU 分组在少数且连接非常良好的服务器上。您还可以尝试将浮点精度从 32 位(tf.float32)降低到 16 位(tf.bfloat16)。这将减少一半的数据传输量,通常不会对收敛速度或模型性能产生太大影响。最后,如果您正在使用集中式参数,您可以将参数分片(分割)到多个参数服务器上:增加更多的参数服务器将减少每个服务器上的网络负载,并限制带宽饱和的风险。
好的,现在我们已经讨论了所有的理论,让我们实际在多个 GPU 上训练一个模型!
使用分布策略 API 进行规模训练
幸运的是,TensorFlow 带有一个非常好的 API,它负责处理将模型分布在多个设备和机器上的所有复杂性:分布策略 API。要在所有可用的 GPU 上(暂时只在单台机器上)使用数据并行性和镜像策略训练一个 Keras 模型,只需创建一个MirroredStrategy对象,调用它的scope()方法以获取一个分布上下文,并将模型的创建和编译包装在该上下文中。然后正常调用模型的fit()方法:
strategy = tf.distribute.MirroredStrategy() with strategy.scope(): model = tf.keras.Sequential([...]) # create a Keras model normally model.compile([...]) # compile the model normally batch_size = 100 # preferably divisible by the number of replicas model.fit(X_train, y_train, epochs=10, validation_data=(X_valid, y_valid), batch_size=batch_size)
在底层,Keras 是分布感知的,因此在这个MirroredStrategy上下文中,它知道必须在所有可用的 GPU 设备上复制所有变量和操作。如果你查看模型的权重,它们是MirroredVariable类型的:
>>> type(model.weights[0]) tensorflow.python.distribute.values.MirroredVariable
请注意,fit() 方法会自动将每个训练批次在所有副本之间进行分割,因此最好确保批次大小可以被副本数量(即可用的 GPU 数量)整除,以便所有副本获得相同大小的批次。就是这样!训练通常会比使用单个设备快得多,而且代码更改确实很小。
训练模型完成后,您可以使用它高效地进行预测:调用predict()方法,它会自动将批处理在所有副本之间分割,以并行方式进行预测。再次强调,批处理大小必须能够被副本数量整除。如果调用模型的save()方法,它将被保存为常规模型,而不是具有多个副本的镜像模型。因此,当您加载它时,它将像常规模型一样运行,在单个设备上:默认情况下在 GPU#0 上,如果没有 GPU 则在 CPU 上。如果您想加载一个模型并在所有可用设备上运行它,您必须在分发上下文中调用tf.keras.models.load_model():
with strategy.scope(): model = tf.keras.models.load_model("my_mirrored_model")
如果您只想使用所有可用 GPU 设备的子集,您可以将列表传递给MirroredStrategy的构造函数:
strategy = tf.distribute.MirroredStrategy(devices=["/gpu:0", "/gpu:1"])
默认情况下,MirroredStrategy类使用NVIDIA Collective Communications Library(NCCL)进行 AllReduce 均值操作,但您可以通过将cross_device_ops参数设置为tf.distribute.HierarchicalCopyAllReduce类的实例或tf.distribute.ReductionToOneDevice类的实例来更改它。默认的 NCCL 选项基于tf.distribute.NcclAllReduce类,通常更快,但这取决于 GPU 的数量和类型,因此您可能想尝试一下其他选择。
如果您想尝试使用集中式参数的数据并行性,请将MirroredStrategy替换为CentralStorageStrategy:
strategy = tf.distribute.experimental.CentralStorageStrategy()
您可以选择设置compute_devices参数来指定要用作工作器的设备列表-默认情况下将使用所有可用的 GPU-您还可以选择设置parameter_device参数来指定要存储参数的设备。默认情况下将使用 CPU,或者如果只有一个 GPU,则使用 GPU。
现在让我们看看如何在一组 TensorFlow 服务器上训练模型!
在 TensorFlow 集群上训练模型
TensorFlow 集群是一组在并行运行的 TensorFlow 进程,通常在不同的机器上,并相互通信以完成一些工作,例如训练或执行神经网络模型。集群中的每个 TF 进程被称为任务或TF 服务器。它有一个 IP 地址,一个端口和一个类型(也称为角色或工作)。类型可以是"worker"、"chief"、"ps"(参数服务器)或"evaluator":
- 每个worker执行计算,通常在一台或多台 GPU 的机器上。
- 首席执行计算任务(它是一个工作者),但也处理额外的工作,比如编写 TensorBoard 日志或保存检查点。集群中只有一个首席。如果没有明确指定首席,则按照惯例第一个工作者就是首席。
- 参数服务器只跟踪变量值,并且通常在仅有 CPU 的机器上。这种类型的任务只能与
ParameterServerStrategy一起使用。 - 评估者显然负责评估。这种类型并不经常使用,当使用时,通常只有一个评估者。
要启动一个 TensorFlow 集群,必须首先定义其规范。这意味着定义每个任务的 IP 地址、TCP 端口和类型。例如,以下集群规范定义了一个有三个任务的集群(两个工作者和一个参数服务器;参见图 19-18)。集群规范是一个字典,每个作业对应一个键,值是任务地址(IP:port)的列表:
cluster_spec = { "worker": [ "machine-a.example.com:2222", # /job:worker/task:0 "machine-b.example.com:2222" # /job:worker/task:1 ], "ps": ["machine-a.example.com:2221"] # /job:ps/task:0 }
通常每台机器上会有一个任务,但正如这个示例所示,如果需要,您可以在同一台机器上配置多个任务。在这种情况下,如果它们共享相同的 GPU,请确保 RAM 适当分配,如前面讨论的那样。
警告
默认情况下,集群中的每个任务可以与其他任务通信,因此请确保配置防火墙以授权这些机器之间这些端口上的所有通信(如果每台机器使用相同的端口,则通常更简单)。
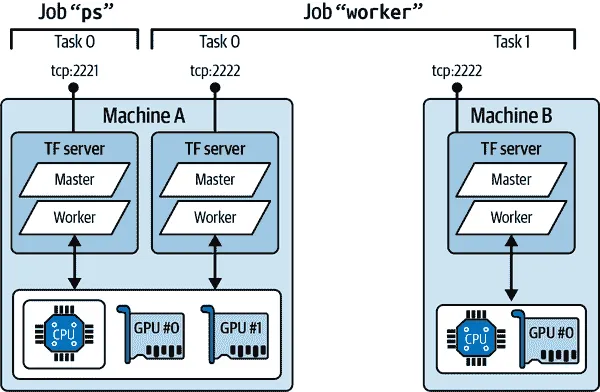
图 19-18。一个示例 TensorFlow 集群
当您开始一个任务时,您必须给它指定集群规范,并且还必须告诉它它的类型和索引是什么(例如,worker #0)。一次性指定所有内容的最简单方法(包括集群规范和当前任务的类型和索引)是在启动 TensorFlow 之前设置TF_CONFIG环境变量。它必须是一个 JSON 编码的字典,包含集群规范(在"cluster"键下)和当前任务的类型和索引(在"task"键下)。例如,以下TF_CONFIG环境变量使用我们刚刚定义的集群,并指定要启动的任务是 worker #0:
os.environ["TF_CONFIG"] = json.dumps({ "cluster": cluster_spec, "task": {"type": "worker", "index": 0} })
提示
通常您希望在 Python 之外定义TF_CONFIG环境变量,这样代码就不需要包含当前任务的类型和索引(这样可以在所有工作节点上使用相同的代码)。
现在让我们在集群上训练一个模型!我们将从镜像策略开始。首先,您需要为每个任务适当设置TF_CONFIG环境变量。集群规范中不应该有参数服务器(删除集群规范中的"ps"键),通常每台机器上只需要一个工作节点。确保为每个任务设置不同的任务索引。最后,在每个工作节点上运行以下脚本:
import tempfile import tensorflow as tf strategy = tf.distribute.MultiWorkerMirroredStrategy() # at the start! resolver = tf.distribute.cluster_resolver.TFConfigClusterResolver() print(f"Starting task {resolver.task_type} #{resolver.task_id}") [...] # load and split the MNIST dataset with strategy.scope(): model = tf.keras.Sequential([...]) # build the Keras model model.compile([...]) # compile the model model.fit(X_train, y_train, validation_data=(X_valid, y_valid), epochs=10) if resolver.task_id == 0: # the chief saves the model to the right location model.save("my_mnist_multiworker_model", save_format="tf") else: tmpdir = tempfile.mkdtemp() # other workers save to a temporary directory model.save(tmpdir, save_format="tf") tf.io.gfile.rmtree(tmpdir) # and we can delete this directory at the end!
这几乎是您之前使用的相同代码,只是这次您正在使用MultiWorkerMirroredStrategy。当您在第一个工作节点上启动此脚本时,它们将在 AllReduce 步骤处保持阻塞,但是一旦最后一个工作节点启动,训练将开始,并且您将看到它们以完全相同的速度前进,因为它们在每一步都进行同步。
警告
在使用MultiWorkerMirroredStrategy时,重要的是确保所有工作人员做同样的事情,包括保存模型检查点或编写 TensorBoard 日志,即使您只保留主要写入的内容。这是因为这些操作可能需要运行 AllReduce 操作,因此所有工作人员必须保持同步。
这个分发策略有两种 AllReduce 实现方式:基于 gRPC 的环形 AllReduce 算法用于网络通信,以及 NCCL 的实现。要使用哪种最佳算法取决于工作人员数量、GPU 数量和类型,以及网络情况。默认情况下,TensorFlow 会应用一些启发式方法为您选择合适的算法,但您可以强制使用 NCCL(或 RING)如下:
strategy = tf.distribute.MultiWorkerMirroredStrategy( communication_options=tf.distribute.experimental.CommunicationOptions( implementation=tf.distribute.experimental.CollectiveCommunication.NCCL))
如果您希望使用参数服务器实现异步数据并行处理,请将策略更改为ParameterServerStrategy,添加一个或多个参数服务器,并为每个任务适当配置TF_CONFIG。请注意,虽然工作人员将异步工作,但每个工作人员上的副本将同步工作。
最后,如果您可以访问Google Cloud 上的 TPU——例如,如果您在 Colab 中设置加速器类型为 TPU——那么您可以像这样创建一个TPUStrategy:
resolver = tf.distribute.cluster_resolver.TPUClusterResolver() tf.tpu.experimental.initialize_tpu_system(resolver) strategy = tf.distribute.experimental.TPUStrategy(resolver)
这需要在导入 TensorFlow 后立即运行。然后您可以正常使用这个策略。
提示
如果您是研究人员,您可能有资格免费使用 TPU;请查看https://tensorflow.org/tfrc获取更多详细信息。
现在您可以跨多个 GPU 和多个服务器训练模型:给自己一个鼓励!然而,如果您想训练一个非常大的模型,您将需要许多 GPU,跨多个服务器,这将要求要么购买大量硬件,要么管理大量云虚拟机。在许多情况下,使用一个云服务来为您提供所有这些基础设施的配置和管理会更方便、更经济,只有在您需要时才会提供。让我们看看如何使用 Vertex AI 来实现这一点。
在 Vertex AI 上运行大型训练作业
Vertex AI 允许您使用自己的训练代码创建自定义训练作业。实际上,您可以几乎使用与在自己的 TF 集群上使用的相同的训练代码。您必须更改的主要内容是首席应该保存模型、检查点和 TensorBoard 日志的位置。首席必须将模型保存到 GCS,使用 Vertex AI 在AIP_MODEL_DIR环境变量中提供的路径,而不是将模型保存到本地目录。对于模型检查点和 TensorBoard 日志,您应该分别使用AIP_CHECKPOINT_DIR和AIP_TENSORBOARD_LOG_DIR环境变量中包含的路径。当然,您还必须确保训练数据可以从虚拟机访问,例如在 GCS 上,或者从另一个 GCP 服务(如 BigQuery)或直接从网络上访问。最后,Vertex AI 明确设置了"chief"任务类型,因此您应该使用resolved.task_type == "chief"来识别首席,而不是使用resolved.task_id == 0:
import os [...] # other imports, create MultiWorkerMirroredStrategy, and resolver if resolver.task_type == "chief": model_dir = os.getenv("AIP_MODEL_DIR") # paths provided by Vertex AI tensorboard_log_dir = os.getenv("AIP_TENSORBOARD_LOG_DIR") checkpoint_dir = os.getenv("AIP_CHECKPOINT_DIR") else: tmp_dir = Path(tempfile.mkdtemp()) # other workers use temporary dirs model_dir = tmp_dir / "model" tensorboard_log_dir = tmp_dir / "logs" checkpoint_dir = tmp_dir / "ckpt" callbacks = [tf.keras.callbacks.TensorBoard(tensorboard_log_dir), tf.keras.callbacks.ModelCheckpoint(checkpoint_dir)] [...] # build and compile using the strategy scope, just like earlier model.fit(X_train, y_train, validation_data=(X_valid, y_valid), epochs=10, callbacks=callbacks) model.save(model_dir, save_format="tf")
提示
如果您将训练数据放在 GCS 上,您可以创建一个tf.data.TextLineDataset或tf.data.TFRecordDataset来访问它:只需将 GCS 路径作为文件名(例如,gs://my_bucket/data/001.csv)。这些数据集依赖于tf.io.gfile包来访问文件:它支持本地文件和 GCS 文件。
现在您可以在 Vertex AI 上基于这个脚本创建一个自定义训练作业。您需要指定作业名称、训练脚本的路径、用于训练的 Docker 镜像、用于预测的镜像(训练后)、您可能需要的任何其他 Python 库,以及最后 Vertex AI 应该使用作为存储训练脚本的暂存目录的存储桶。默认情况下,这也是训练脚本将保存训练模型、TensorBoard 日志和模型检查点(如果有的话)的地方。让我们创建这个作业:
custom_training_job = aiplatform.CustomTrainingJob( display_name="my_custom_training_job", script_path="my_vertex_ai_training_task.py", container_uri="gcr.io/cloud-aiplatform/training/tf-gpu.2-4:latest", model_serving_container_image_uri=server_image, requirements=["gcsfs==2022.3.0"], # not needed, this is just an example staging_bucket=f"gs://{bucket_name}/staging" )
现在让我们在两个拥有两个 GPU 的工作节点上运行它:
mnist_model2 = custom_training_job.run( machine_type="n1-standard-4", replica_count=2, accelerator_type="NVIDIA_TESLA_K80", accelerator_count=2, )
这就是全部内容:Vertex AI 将为您请求的计算节点进行配置(在您的配额范围内),并在这些节点上运行您的训练脚本。一旦作业完成,run()方法将返回一个经过训练的模型,您可以像之前创建的那样使用它:您可以部署到端点,或者用它进行批量预测。如果在训练过程中出现任何问题,您可以在 GCP 控制台中查看日志:在☰导航菜单中,选择 Vertex AI → 训练,点击您的训练作业,然后点击查看日志。或者,您可以点击自定义作业选项卡,复制作业的 ID(例如,1234),然后从☰导航菜单中选择日志记录,并查询resource.labels.job_id=1234。
提示
要可视化训练进度,只需启动 TensorBoard,并将其--logdir指向日志的 GCS 路径。它将使用应用程序默认凭据,您可以使用gcloud auth application-default login进行设置。如果您喜欢,Vertex AI 还提供托管的 TensorBoard 服务器。
如果您想尝试一些超参数值,一个选项是运行多个作业。您可以通过在调用run()方法时设置args参数将超参数值作为命令行参数传递给您的脚本,或者您可以使用environment_variables参数将它们作为环境变量传递。
然而,如果您想在云上运行一个大型的超参数调整作业,一个更好的选择是使用 Vertex AI 的超参数调整服务。让我们看看如何做。
Vertex AI 上的超参数调整
Vertex AI 的超参数调整服务基于贝叶斯优化算法,能够快速找到最佳的超参数组合。要使用它,首先需要创建一个接受超参数值作为命令行参数的训练脚本。例如,您的脚本可以像这样使用argparse标准库:
import argparse parser = argparse.ArgumentParser() parser.add_argument("--n_hidden", type=int, default=2) parser.add_argument("--n_neurons", type=int, default=256) parser.add_argument("--learning_rate", type=float, default=1e-2) parser.add_argument("--optimizer", default="adam") args = parser.parse_args()
超参数调整服务将多次调用您的脚本,每次使用不同的超参数值:每次运行称为trial,一组试验称为study。然后,您的训练脚本必须使用给定的超参数值来构建和编译模型。如果需要,您可以使用镜像分发策略,以便每个试验在多 GPU 机器上运行。然后脚本可以加载数据集并训练模型。例如:
import tensorflow as tf def build_model(args): with tf.distribute.MirroredStrategy().scope(): model = tf.keras.Sequential() model.add(tf.keras.layers.Flatten(input_shape=[28, 28], dtype=tf.uint8)) for _ in range(args.n_hidden): model.add(tf.keras.layers.Dense(args.n_neurons, activation="relu")) model.add(tf.keras.layers.Dense(10, activation="softmax")) opt = tf.keras.optimizers.get(args.optimizer) opt.learning_rate = args.learning_rate model.compile(loss="sparse_categorical_crossentropy", optimizer=opt, metrics=["accuracy"]) return model [...] # load the dataset model = build_model(args) history = model.fit([...])
提示
您可以使用我们之前提到的AIP_*环境变量来确定在哪里保存检查点、TensorBoard 日志和最终模型。
最后,脚本必须将模型的性能报告给 Vertex AI 的超参数调整服务,以便它决定尝试哪些超参数。为此,您必须使用hypertune库,在 Vertex AI 训练 VM 上自动安装:
import hypertune hypertune = hypertune.HyperTune() hypertune.report_hyperparameter_tuning_metric( hyperparameter_metric_tag="accuracy", # name of the reported metric metric_value=max(history.history["val_accuracy"]), # metric value global_step=model.optimizer.iterations.numpy(), )
现在您的训练脚本已准备就绪,您需要定义要在其上运行的机器类型。为此,您必须定义一个自定义作业,Vertex AI 将使用它作为每个试验的模板:
trial_job = aiplatform.CustomJob.from_local_script( display_name="my_search_trial_job", script_path="my_vertex_ai_trial.py", # path to your training script container_uri="gcr.io/cloud-aiplatform/training/tf-gpu.2-4:latest", staging_bucket=f"gs://{bucket_name}/staging", accelerator_type="NVIDIA_TESLA_K80", accelerator_count=2, # in this example, each trial will have 2 GPUs )
最后,您准备好创建并运行超参数调整作业:
from google.cloud.aiplatform import hyperparameter_tuning as hpt hp_job = aiplatform.HyperparameterTuningJob( display_name="my_hp_search_job", custom_job=trial_job, metric_spec={"accuracy": "maximize"}, parameter_spec={ "learning_rate": hpt.DoubleParameterSpec(min=1e-3, max=10, scale="log"), "n_neurons": hpt.IntegerParameterSpec(min=1, max=300, scale="linear"), "n_hidden": hpt.IntegerParameterSpec(min=1, max=10, scale="linear"), "optimizer": hpt.CategoricalParameterSpec(["sgd", "adam"]), }, max_trial_count=100, parallel_trial_count=20, ) hp_job.run()
在这里,我们告诉 Vertex AI 最大化名为 "accuracy" 的指标:这个名称必须与训练脚本报告的指标名称匹配。我们还定义了搜索空间,使用对数尺度来设置学习率,使用线性(即均匀)尺度来设置其他超参数。超参数的名称必须与训练脚本的命令行参数匹配。然后我们将最大试验次数设置为 100,同时最大并行运行的试验次数设置为 20。如果你将并行试验的数量增加到(比如)60,总搜索时间将显著减少,最多可减少到 3 倍。但前 60 个试验将同时开始,因此它们将无法从其他试验的反馈中受益。因此,您应该增加最大试验次数来补偿,例如增加到大约 140。
这将需要相当长的时间。一旦作业完成,您可以使用 hp_job.trials 获取试验结果。每个试验结果都表示为一个 protobuf 对象,包含超参数值和结果指标。让我们找到最佳试验:
def get_final_metric(trial, metric_id): for metric in trial.final_measurement.metrics: if metric.metric_id == metric_id: return metric.value trials = hp_job.trials trial_accuracies = [get_final_metric(trial, "accuracy") for trial in trials] best_trial = trials[np.argmax(trial_accuracies)]
现在让我们看看这个试验的准确率,以及其超参数值:
>>> max(trial_accuracies) 0.977400004863739 >>> best_trial.id '98' >>> best_trial.parameters [parameter_id: "learning_rate" value { number_value: 0.001 }, parameter_id: "n_hidden" value { number_value: 8.0 }, parameter_id: "n_neurons" value { number_value: 216.0 }, parameter_id: "optimizer" value { string_value: "adam" } ]
就是这样!现在您可以获取这个试验的 SavedModel,可选择性地再训练一下,并将其部署到生产环境中。
提示
Vertex AI 还包括一个 AutoML 服务,完全负责为您找到合适的模型架构并为您进行训练。您只需要将数据集以特定格式上传到 Vertex AI,这取决于数据集的类型(图像、文本、表格、视频等),然后创建一个 AutoML 训练作业,指向数据集并指定您愿意花费的最大计算小时数。请参阅笔记本中的示例。
现在你拥有了所有需要创建最先进的神经网络架构并使用各种分布策略进行规模化训练的工具和知识,可以在自己的基础设施或云上部署它们,然后在任何地方部署它们。换句话说,你现在拥有超能力:好好利用它们!
练习
- SavedModel 包含什么?如何检查其内容?
- 什么时候应该使用 TF Serving?它的主要特点是什么?有哪些工具可以用来部署它?
- 如何在多个 TF Serving 实例上部署模型?
- 在查询由 TF Serving 提供的模型时,何时应该使用 gRPC API 而不是 REST API?
- TFLite 通过哪些不同的方式减小模型的大小,使其能在移动设备或嵌入式设备上运行?
- 什么是量化感知训练,为什么需要它?
- 什么是模型并行和数据并行?为什么通常推荐后者?
- 在多台服务器上训练模型时,您可以使用哪些分发策略?您如何选择使用哪种?
- 训练一个模型(任何您喜欢的模型)并部署到 TF Serving 或 Google Vertex AI。编写客户端代码,使用 REST API 或 gRPC API 查询它。更新模型并部署新版本。您的客户端代码现在将查询新版本。回滚到第一个版本。
- 在同一台机器上使用
MirroredStrategy在多个 GPU 上训练任何模型(如果您无法访问 GPU,可以使用带有 GPU 运行时的 Google Colab 并创建两个逻辑 GPU)。再次使用CentralStorageStrategy训练模型并比较训练时间。 - 在 Vertex AI 上微调您选择的模型,使用 Keras Tuner 或 Vertex AI 的超参数调整服务。
这些练习的解决方案可以在本章笔记本的末尾找到,网址为https://homl.info/colab3。
谢谢!
在我们结束这本书的最后一章之前,我想感谢您读到最后一段。我真诚地希望您阅读这本书和我写作时一样开心,并且它对您的项目,无论大小,都有用。
如果您发现错误,请发送反馈。更一般地,我很想知道您的想法,所以请不要犹豫通过 O’Reilly、ageron/handson-ml3 GitHub 项目或 Twitter 上的@aureliengeron 与我联系。
继续前进,我给你的最好建议是练习和练习:尝试完成所有的练习(如果你还没有这样做),玩一下笔记本电脑,加入 Kaggle 或其他机器学习社区,观看机器学习课程,阅读论文,参加会议,与专家会面。事情发展迅速,所以尽量保持最新。一些 YouTube 频道定期以非常易懂的方式详细介绍深度学习论文。我特别推荐 Yannic Kilcher、Letitia Parcalabescu 和 Xander Steenbrugge 的频道。要了解引人入胜的机器学习讨论和更高层次的见解,请务必查看 ML Street Talk 和 Lex Fridman 的频道。拥有一个具体的项目要去做也会极大地帮助,无论是为了工作还是为了娱乐(最好两者兼顾),所以如果你一直梦想着建造某样东西,就试一试吧!逐步工作;不要立即朝着月球开火,而是专注于你的项目,一步一步地构建它。这需要耐心和毅力,但当你拥有一个行走的机器人,或一个工作的聊天机器人,或者其他你喜欢的任何东西时,这将是极其有益的!
我最大的希望是这本书能激发你构建一个美妙的 ML 应用程序,使我们所有人受益。它会是什么样的?
—Aurélien Géron
¹ A/B 实验包括在不同的用户子集上测试产品的两个不同版本,以检查哪个版本效果最好并获得其他见解。
² Google AI 平台(以前称为 Google ML 引擎)和 Google AutoML 在 2021 年合并为 Google Vertex AI。
³ REST(或 RESTful)API 是一种使用标准 HTTP 动词(如 GET、POST、PUT 和 DELETE)以及使用 JSON 输入和输出的 API。gRPC 协议更复杂但更高效;数据使用协议缓冲区进行交换(参见第十三章)。
如果您对 Docker 不熟悉,它允许您轻松下载一组打包在Docker 镜像中的应用程序(包括所有依赖项和通常一些良好的默认配置),然后使用Docker 引擎在您的系统上运行它们。当您运行一个镜像时,引擎会创建一个保持应用程序与您自己系统良好隔离的Docker 容器,但如果您愿意,可以给它一些有限的访问权限。它类似于虚拟机,但速度更快、更轻,因为容器直接依赖于主机的内核。这意味着镜像不需要包含或运行自己的内核。
还有 GPU 镜像可用,以及其他安装选项。有关更多详细信息,请查看官方安装说明。
公平地说,这可以通过首先序列化数据,然后将其编码为 Base64,然后创建 REST 请求来减轻。此外,REST 请求可以使用 gzip 进行压缩,从而显著减少有效负载大小。
还要查看 TensorFlow 的Graph Transform Tool,用于修改和优化计算图。
例如,PWA 必须包含不同移动设备大小的图标,必须通过 HTTPS 提供,必须包含包含应用程序名称和背景颜色等元数据的清单文件。
请查看 TensorFlow 文档,获取详细和最新的安装说明,因为它们经常更改。
¹⁰ 正如我们在第十二章中所看到的,内核是特定数据类型和设备类型的操作实现。例如,float32 tf.matmul() 操作有一个 GPU 内核,但 int32 tf.matmul() 没有 GPU 内核,只有一个 CPU 内核。
¹¹ 您还可以使用 tf.debugging.set_log_device_placement(True) 来记录所有设备放置情况。
¹² 如果您想要保证完美的可重现性,这可能很有用,正如我在这个视频中所解释的,基于 TF 1。
¹³ 在撰写本文时,它只是将数据预取到 CPU RAM,但使用 tf.data.experimental.prefetch_to_device() 可以使其预取数据并将其推送到您选择的设备,以便 GPU 不必等待数据传输而浪费时间。
如果两个 CNN 相同,则称为孪生神经网络。
如果您对模型并行性感兴趣,请查看Mesh TensorFlow。
这个名字有点令人困惑,因为听起来好像有些副本是特殊的,什么也不做。实际上,所有副本都是等价的:它们都努力成为每个训练步骤中最快的,失败者在每一步都会变化(除非某些设备真的比其他设备慢)。但是,这意味着如果一个或两个服务器崩溃,训练将继续进行得很好。
Jianmin Chen 等人,“重新审视分布式同步 SGD”,arXiv 预印本 arXiv:1604.00981(2016)。
¹⁸ Aaron Harlap 等人,“PipeDream: 快速高效的管道并行 DNN 训练”,arXiv 预印本 arXiv:1806.03377(2018)。
¹⁹ Paul Barham 等人,“Pathways: 异步分布式数据流 ML”,arXiv 预印本 arXiv:2203.12533(2022)。
²⁰ 有关 AllReduce 算法的更多详细信息,请阅读 Yuichiro Ueno 的文章,该文章介绍了深度学习背后的技术,以及 Sylvain Jeaugey 的文章,该文章介绍了如何使用 NCCL 大规模扩展深度学习训练。




