Sklearn、TensorFlow 与 Keras 机器学习实用指南第三版(六)(3)https://developer.aliyun.com/article/1482442
多变量时间序列预测
神经网络的一个很大的优点是它们的灵活性:特别是,它们几乎不需要改变架构就可以处理多变量时间序列。例如,让我们尝试使用公交和铁路数据作为输入来预测铁路时间序列。事实上,让我们也加入日期类型!由于我们总是可以提前知道明天是工作日、周末还是假日,我们可以将日期类型系列向未来推移一天,这样模型就会将明天的日期类型作为输入。为简单起见,我们将使用 Pandas 进行此处理:
df_mulvar = df[["bus", "rail"]] / 1e6 # use both bus & rail series as input df_mulvar["next_day_type"] = df["day_type"].shift(-1) # we know tomorrow's type df_mulvar = pd.get_dummies(df_mulvar) # one-hot encode the day type
现在 df_mulvar 是一个包含五列的 DataFrame:公交和铁路数据,以及包含下一天类型的独热编码的三列(请记住,有三种可能的日期类型,W、A 和 U)。接下来我们可以像之前一样继续。首先,我们将数据分为三个时期,用于训练、验证和测试:
mulvar_train = df_mulvar["2016-01":"2018-12"] mulvar_valid = df_mulvar["2019-01":"2019-05"] mulvar_test = df_mulvar["2019-06":]
然后我们创建数据集:
train_mulvar_ds = tf.keras.utils.timeseries_dataset_from_array( mulvar_train.to_numpy(), # use all 5 columns as input targets=mulvar_train["rail"][seq_length:], # forecast only the rail series [...] # the other 4 arguments are the same as earlier ) valid_mulvar_ds = tf.keras.utils.timeseries_dataset_from_array( mulvar_valid.to_numpy(), targets=mulvar_valid["rail"][seq_length:], [...] # the other 2 arguments are the same as earlier )
最后我们创建 RNN:
mulvar_model = tf.keras.Sequential([ tf.keras.layers.SimpleRNN(32, input_shape=[None, 5]), tf.keras.layers.Dense(1) ])
请注意,与我们之前构建的 univar_model RNN 唯一的区别是输入形状:在每个时间步骤,模型现在接收五个输入,而不是一个。这个模型实际上达到了 22,062 的验证 MAE。现在我们取得了很大的进展!
事实上,让 RNN 预测公交和铁路乘客量并不太难。您只需要在创建数据集时更改目标,将其设置为训练集的 mulvar_train[["bus", "rail"]][seq_length:],验证集的 mulvar_valid[["bus", "rail"]][seq_length:]。您还必须在输出 Dense 层中添加一个额外的神经元,因为现在它必须进行两次预测:一次是明天的公交乘客量,另一次是铁路乘客量。就是这样!
正如我们在第十章中讨论的那样,对于多个相关任务使用单个模型通常比为每个任务使用单独的模型效果更好,因为为一个任务学习的特征可能对其他任务也有用,而且因为在多个任务中表现良好可以防止模型过拟合(这是一种正则化形式)。然而,这取决于任务,在这种特殊情况下,同时预测公交和铁路乘客量的多任务 RNN 并不像专门预测其中一个的模型表现得那么好(使用所有五列作为输入)。尽管如此,它对铁路的验证 MAE 达到了 25,330,对公交达到了 26,369,这还是相当不错的。
提前预测多个时间步
到目前为止,我们只预测了下一个时间步的值,但我们也可以通过适当更改目标来预测几个步骤之后的值(例如,要预测两周后的乘客量,我们只需将目标更改为比 1 天后提前 14 天的值)。但是如果我们想预测接下来的 14 个值呢?
第一种选择是取我们之前为铁路时间序列训练的 univar_model RNN,让它预测下一个值,并将该值添加到输入中,就好像预测的值实际上已经发生了;然后我们再次使用模型来预测下一个值,依此类推,如下面的代码所示:
import numpy as np X = rail_valid.to_numpy()[np.newaxis, :seq_length, np.newaxis] for step_ahead in range(14): y_pred_one = univar_model.predict(X) X = np.concatenate([X, y_pred_one.reshape(1, 1, 1)], axis=1)
在这段代码中,我们取验证期间前 56 天的铁路乘客量,并将数据转换为形状为 [1, 56, 1] 的 NumPy 数组(请记住,循环层期望 3D 输入)。然后我们重复使用模型来预测下一个值,并将每个预测附加到输入系列中,沿着时间轴(axis=1)。生成的预测在图 15-11 中绘制。
警告
如果模型在一个时间步骤上出现错误,那么接下来的时间步骤的预测也会受到影响:错误往往会累积。因此,最好只在少数步骤中使用这种技术。
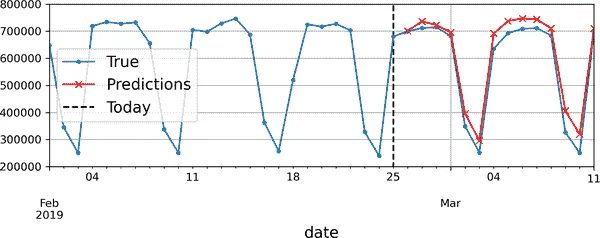
图 15-11。提前 14 步预测,一次预测一步
第二个选项是训练一个 RNN 一次性预测接下来的 14 个值。我们仍然可以使用一个序列到向量模型,但它将输出 14 个值而不是 1。然而,我们首先需要改变目标,使其成为包含接下来 14 个值的向量。为此,我们可以再次使用timeseries_dataset_from_array(),但这次要求它创建没有目标(targets=None)的数据集,并且具有更长的序列,长度为seq_length + 14。然后我们可以使用数据集的map()方法对每个序列批次应用自定义函数,将其分成输入和目标。在这个例子中,我们使用多变量时间序列作为输入(使用所有五列),并预测未来 14 天的铁路乘客量。
def split_inputs_and_targets(mulvar_series, ahead=14, target_col=1): return mulvar_series[:, :-ahead], mulvar_series[:, -ahead:, target_col] ahead_train_ds = tf.keras.utils.timeseries_dataset_from_array( mulvar_train.to_numpy(), targets=None, sequence_length=seq_length + 14, [...] # the other 3 arguments are the same as earlier ).map(split_inputs_and_targets) ahead_valid_ds = tf.keras.utils.timeseries_dataset_from_array( mulvar_valid.to_numpy(), targets=None, sequence_length=seq_length + 14, batch_size=32 ).map(split_inputs_and_targets)
现在我们只需要将输出层的单元数从 1 增加到 14:
ahead_model = tf.keras.Sequential([ tf.keras.layers.SimpleRNN(32, input_shape=[None, 5]), tf.keras.layers.Dense(14) ])
训练完这个模型后,你可以像这样一次性预测接下来的 14 个值:
X = mulvar_valid.to_numpy()[np.newaxis, :seq_length] # shape [1, 56, 5] Y_pred = ahead_model.predict(X) # shape [1, 14]
这种方法效果相当不错。它对于第二天的预测显然比对未来 14 天的预测要好,但它不会像之前的方法那样累积误差。然而,我们仍然可以做得更好,使用一个序列到序列(或seq2seq)模型。
使用序列到序列模型进行预测
不是只在最后一个时间步训练模型来预测接下来的 14 个值,而是在每一个时间步都训练它来预测接下来的 14 个值。换句话说,我们可以将这个序列到向量的 RNN 转变为一个序列到序列的 RNN。这种技术的优势在于损失函数将包含 RNN 在每一个时间步的输出,而不仅仅是最后一个时间步的输出。
这意味着会有更多的误差梯度通过模型流动,它们不需要像以前那样通过时间流动,因为它们将来自每一个时间步的输出,而不仅仅是最后一个时间步。这将使训练更加稳定和快速。
明确一点,在时间步 0,模型将输出一个包含时间步 1 到 14 的预测的向量,然后在时间步 1,模型将预测时间步 2 到 15,依此类推。换句话说,目标是连续窗口的序列,每个时间步向后移动一个时间步。目标不再是一个向量,而是一个与输入相同长度的序列,每一步包含一个 14 维向量。
准备数据集并不是简单的,因为每个实例的输入是一个窗口,输出是窗口序列。一种方法是连续两次使用我们之前创建的to_windows()实用函数,以获得连续窗口的窗口。例如,让我们将数字 0 到 6 的系列转换为包含 4 个连续窗口的数据集,每个窗口长度为 3:
>>> my_series = tf.data.Dataset.range(7) >>> dataset = to_windows(to_windows(my_series, 3), 4) >>> list(dataset) [<tf.Tensor: shape=(4, 3), dtype=int64, numpy= array([[0, 1, 2], [1, 2, 3], [2, 3, 4], [3, 4, 5]])>, <tf.Tensor: shape=(4, 3), dtype=int64, numpy= array([[1, 2, 3], [2, 3, 4], [3, 4, 5], [4, 5, 6]])>]
现在我们可以使用map()方法将这些窗口的窗口分割为输入和目标:
>>> dataset = dataset.map(lambda S: (S[:, 0], S[:, 1:])) >>> list(dataset) [(<tf.Tensor: shape=(4,), dtype=int64, numpy=array([0, 1, 2, 3])>, <tf.Tensor: shape=(4, 2), dtype=int64, numpy= array([[1, 2], [2, 3], [3, 4], [4, 5]])>), (<tf.Tensor: shape=(4,), dtype=int64, numpy=array([1, 2, 3, 4])>, <tf.Tensor: shape=(4, 2), dtype=int64, numpy= array([[2, 3], [3, 4], [4, 5], [5, 6]])>)]
现在数据集包含长度为 4 的输入序列,目标是包含下两个步骤的序列,每个时间步。例如,第一个输入序列是[0, 1, 2, 3],对应的目标是[[1, 2], [2, 3], [3, 4], [4, 5]],这是每个时间步的下两个值。如果你和我一样,可能需要几分钟来理解这个概念。慢慢来!
注意
也许令人惊讶的是,目标值包含在输入中出现的值。这是不是作弊?幸运的是,完全不是:在每一个时间步,RNN 只知道过去的时间步;它无法向前看。它被称为因果模型。
让我们创建另一个小型实用函数来为我们的序列到序列模型准备数据集。它还会负责洗牌(可选)和分批处理:
def to_seq2seq_dataset(series, seq_length=56, ahead=14, target_col=1, batch_size=32, shuffle=False, seed=None): ds = to_windows(tf.data.Dataset.from_tensor_slices(series), ahead + 1) ds = to_windows(ds, seq_length).map(lambda S: (S[:, 0], S[:, 1:, 1])) if shuffle: ds = ds.shuffle(8 * batch_size, seed=seed) return ds.batch(batch_size)
现在我们可以使用这个函数来创建数据集:
seq2seq_train = to_seq2seq_dataset(mulvar_train, shuffle=True, seed=42) seq2seq_valid = to_seq2seq_dataset(mulvar_valid)
最后,我们可以构建序列到序列模型:
seq2seq_model = tf.keras.Sequential([ tf.keras.layers.SimpleRNN(32, return_sequences=True, input_shape=[None, 5]), tf.keras.layers.Dense(14) ])
这几乎与我们之前的模型完全相同:唯一的区别是在SimpleRNN层中设置了return_sequences=True。这样,它将输出一个向量序列(每个大小为 32),而不是在最后一个时间步输出单个向量。Dense层足够聪明,可以处理序列作为输入:它将在每个时间步应用,以 32 维向量作为输入,并输出 14 维向量。实际上,获得完全相同结果的另一种方法是使用具有核大小为 1 的Conv1D层:Conv1D(14, kernel_size=1)。
提示
Keras 提供了一个TimeDistributed层,允许您将任何向量到向量层应用于输入序列中的每个向量,在每个时间步。它通过有效地重新塑造输入来实现这一点,以便将每个时间步视为单独的实例,然后重新塑造层的输出以恢复时间维度。在我们的情况下,我们不需要它,因为Dense层已经支持序列作为输入。
训练代码与往常一样。在训练期间,使用所有模型的输出,但在训练后,只有最后一个时间步的输出才重要,其余可以忽略。例如,我们可以这样预测未来 14 天的铁路乘客量:
X = mulvar_valid.to_numpy()[np.newaxis, :seq_length] y_pred_14 = seq2seq_model.predict(X)[0, -1] # only the last time step's output
如果评估此模型对t + 1 的预测,您将发现验证 MAE 为 25,519。对于t + 2,它为 26,274,随着模型试图进一步预测未来,性能会逐渐下降。在t + 14 时,MAE 为 34,322。
提示
您可以结合两种方法来预测多步:例如,您可以训练一个模型,预测未来 14 天,然后将其输出附加到输入,然后再次运行模型,以获取接下来 14 天的预测,并可能重复该过程。
简单的 RNN 在预测时间序列或处理其他类型的序列时可能表现得很好,但在长时间序列或序列上表现不佳。让我们讨论一下原因,并看看我们能做些什么。
处理长序列
要在长序列上训练 RNN,我们必须在许多时间步上运行它,使展开的 RNN 成为一个非常深的网络。就像任何深度神经网络一样,它可能会遇到不稳定的梯度问题,如第十一章中讨论的:可能需要很长时间来训练,或者训练可能不稳定。此外,当 RNN 处理长序列时,它将逐渐忘记序列中的第一个输入。让我们从不稳定的梯度问题开始,看看这两个问题。
解决不稳定梯度问题
许多我们在深度网络中用来缓解不稳定梯度问题的技巧也可以用于 RNN:良好的参数初始化,更快的优化器,辍学等。然而,非饱和激活函数(例如 ReLU)在这里可能不会有太大帮助。实际上,它们可能会导致 RNN 在训练过程中更加不稳定。为什么?嗯,假设梯度下降以一种增加第一个时间步输出的方式更新权重。由于相同的权重在每个时间步使用,第二个时间步的输出也可能略有增加,第三个时间步也是如此,直到输出爆炸——而非饱和激活函数无法阻止这种情况。
您可以通过使用较小的学习率来减少这种风险,或者可以使用饱和激活函数,如双曲正切(这解释了为什么它是默认值)。
同样,梯度本身也可能爆炸。如果注意到训练不稳定,可以监控梯度的大小(例如,使用 TensorBoard),并可能使用梯度裁剪。
此外,批量归一化不能像深度前馈网络那样有效地与 RNN 一起使用。实际上,您不能在时间步之间使用它,只能在循环层之间使用。
更准确地说,从技术上讲,可以在内存单元中添加一个 BN 层(您很快就会看到),以便在每个时间步上应用它(既在该时间步的输入上,也在上一个步骤的隐藏状态上)。然而,相同的 BN 层将在每个时间步上使用相同的参数,而不考虑输入和隐藏状态的实际比例和偏移。实际上,这并不会产生良好的结果,如 César Laurent 等人在2015 年的一篇论文中所证明的:作者发现,只有当 BN 应用于层的输入时才略有益处,而不是应用于隐藏状态。换句话说,当应用于循环层之间(即在图 15-10 中垂直地)时,它略好于什么都不做,但不适用于循环层内部(即水平地)。在 Keras 中,您可以通过在每个循环层之前添加一个 BatchNormalization 层来简单地在层之间应用 BN,但这会减慢训练速度,并且可能帮助不大。
另一种规范化方法在 RNN 中通常效果更好:层归一化。这个想法是由 Jimmy Lei Ba 等人在2016 年的一篇论文中提出的:它与批归一化非常相似,但不同的是,层归一化是在特征维度上进行归一化,而不是在批次维度上。一个优点是它可以在每个时间步上独立地为每个实例计算所需的统计数据。这也意味着它在训练和测试期间的行为是相同的(与 BN 相反),它不需要使用指数移动平均来估计训练集中所有实例的特征统计数据,就像 BN 那样。与 BN 类似,层归一化为每个输入学习一个比例和偏移参数。在 RNN 中,它通常在输入和隐藏状态的线性组合之后立即使用。
让我们使用 Keras 在简单内存单元中实现层归一化。为此,我们需要定义一个自定义内存单元,它就像一个常规层一样,只是它的 call() 方法接受两个参数:当前时间步的 inputs 和上一个时间步的隐藏 states。
请注意,states 参数是一个包含一个或多个张量的列表。在简单的 RNN 单元中,它包含一个张量,等于上一个时间步的输出,但其他单元可能有多个状态张量(例如,LSTMCell 有一个长期状态和一个短期状态,您很快就会看到)。一个单元还必须有一个 state_size 属性和一个 output_size 属性。在简单的 RNN 中,两者都简单地等于单元的数量。以下代码实现了一个自定义内存单元,它将表现得像一个 SimpleRNNCell,但它还会在每个时间步应用层归一化:
class LNSimpleRNNCell(tf.keras.layers.Layer): def __init__(self, units, activation="tanh", **kwargs): super().__init__(**kwargs) self.state_size = units self.output_size = units self.simple_rnn_cell = tf.keras.layers.SimpleRNNCell(units, activation=None) self.layer_norm = tf.keras.layers.LayerNormalization() self.activation = tf.keras.activations.get(activation) def call(self, inputs, states): outputs, new_states = self.simple_rnn_cell(inputs, states) norm_outputs = self.activation(self.layer_norm(outputs)) return norm_outputs, [norm_outputs]
让我们来看一下这段代码:
- 我们的
LNSimpleRNNCell类继承自tf.keras.layers.Layer类,就像任何自定义层一样。 - 构造函数接受单位数和所需的激活函数,并设置
state_size和output_size属性,然后创建一个没有激活函数的SimpleRNNCell(因为我们希望在线性操作之后但在激活函数之前执行层归一化)。然后构造函数创建LayerNormalization层,最后获取所需的激活函数。 call()方法首先应用simpleRNNCell,它计算当前输入和先前隐藏状态的线性组合,并返回结果两次(实际上,在SimpleRNNCell中,输出就等于隐藏状态:换句话说,new_states[0]等于outputs,因此我们可以在call()方法的其余部分安全地忽略new_states)。接下来,call()方法应用层归一化,然后是激活函数。最后,它将输出返回两次:一次作为输出,一次作为新的隐藏状态。要使用此自定义细胞,我们只需要创建一个tf.keras.layers.RNN层,将其传递给一个细胞实例:
custom_ln_model = tf.keras.Sequential([ tf.keras.layers.RNN(LNSimpleRNNCell(32), return_sequences=True, input_shape=[None, 5]), tf.keras.layers.Dense(14) ])
同样,您可以创建一个自定义细胞,在每个时间步之间应用 dropout。但有一个更简单的方法:Keras 提供的大多数循环层和细胞都有dropout和recurrent_dropout超参数:前者定义要应用于输入的 dropout 率,后者定义隐藏状态之间的 dropout 率,即时间步之间。因此,在 RNN 中不需要创建自定义细胞来在每个时间步应用 dropout。
通过这些技术,您可以缓解不稳定梯度问题,并更有效地训练 RNN。现在让我们看看如何解决短期记忆问题。
提示
在预测时间序列时,通常有必要在预测中包含一些误差范围。为此,一种方法是使用 MC dropout,介绍在第十一章中:在训练期间使用recurrent_dropout,然后在推断时通过使用model(X, training=True)来保持 dropout 处于活动状态。多次重复此操作以获得多个略有不同的预测,然后计算每个时间步的这些预测的均值和标准差。
解决短期记忆问题
由于数据在经过 RNN 时经历的转换,每个时间步都会丢失一些信息。过一段时间后,RNN 的状态几乎不包含最初输入的任何痕迹。这可能是一个停滞不前的问题。想象一下多莉鱼试图翻译一句长句子;当她读完时,她已经不记得它是如何开始的。为了解决这个问题,引入了各种具有长期记忆的细胞类型。它们已经被证明非常成功,以至于基本细胞不再被广泛使用。让我们首先看看这些长期记忆细胞中最受欢迎的:LSTM 细胞。
LSTM 细胞
长短期记忆(LSTM)细胞是由 Sepp Hochreiter 和 Jürgen Schmidhuber 于 1997 年提出的,并在多年来逐渐得到了几位研究人员的改进,如 Alex Graves,Haşim Sak 和 Wojciech Zaremba。如果将 LSTM 细胞视为黑匣子,它可以被用作基本细胞,只是它的性能会更好;训练会更快收敛,并且它会检测数据中更长期的模式。在 Keras 中,您可以简单地使用LSTM层而不是SimpleRNN层:
model = tf.keras.Sequential([ tf.keras.layers.LSTM(32, return_sequences=True, input_shape=[None, 5]), tf.keras.layers.Dense(14) ])
或者,您可以使用通用的tf.keras.layers.RNN层,将LSTMCell作为参数传递给它。但是,当在 GPU 上运行时,LSTM层使用了优化的实现(请参阅第十九章),因此通常最好使用它(RNN层在定义自定义细胞时非常有用,就像我们之前做的那样)。
那么 LSTM 细胞是如何工作的呢?其架构显示在图 15-12 中。如果不看盒子里面的内容,LSTM 细胞看起来与常规细胞完全相同,只是其状态分为两个向量:h[(t)]和c[(t)](“c”代表“cell”)。您可以将h[(t)]视为短期状态,将c[(t)]视为长期状态。
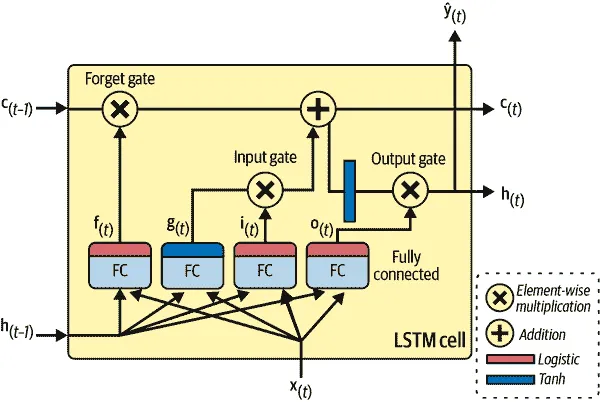
图 15-12. LSTM 单元
现在让我们打开盒子!关键思想是网络可以学习将什么存储在长期状态中,什么丢弃,以及从中读取什么。当长期状态c[(t–1)]从左到右穿过网络时,您可以看到它首先经过一个遗忘门,丢弃一些记忆,然后通过加法操作添加一些新的记忆(通过输入门选择的记忆)。结果c[(t)]直接发送出去,没有进一步的转换。因此,在每个时间步骤,一些记忆被丢弃,一些记忆被添加。此外,在加法操作之后,长期状态被复制并通过 tanh 函数传递,然后结果由输出门过滤。这产生了短期状态h[(t)](这等于此时间步骤的单元输出y[(t))。现在让我们看看新记忆来自哪里以及门是如何工作的。
首先,当前输入向量x[(t)]和先前的短期状态h[(t–1)]被馈送到四个不同的全连接层。它们各自有不同的作用:
- 主要层是输出g[(t)]的层。它通常的作用是分析当前输入x[(t)]和先前(短期)状态h[(t–1)]。在基本单元中,除了这一层外没有其他内容,其输出直接发送到y[(t)]和h[(t)]。但在 LSTM 单元中,这一层的输出不会直接输出;相反,其最重要的部分存储在长期状态中(其余部分被丢弃)。
- 其他三个层是门控制器。由于它们使用逻辑激活函数,输出范围从 0 到 1。正如您所看到的,门控制器的输出被馈送到逐元素乘法操作:如果它们输出 0,则关闭门,如果它们输出 1,则打开门。具体来说:
- 遗忘门(由f[(t)]控制)控制着应该擦除长期状态的哪些部分。
- 输入门(由i[(t)]控制)控制着应该将g[(t)]的哪些部分添加到长期状态中。
- 最后,输出门(由o[(t)]控制)控制着长期状态的哪些部分应该在此时间步骤被读取并输出,既输出到h[(t)],也输出到y[(t)]。
简而言之,LSTM 单元可以学习识别重要的输入(这是输入门的作用),将其存储在长期状态中,保留它直到需要(这是遗忘门的作用),并在需要时提取它。这解释了为什么这些单元在捕捉时间序列、长文本、音频记录等长期模式方面取得了惊人的成功。
方程 15-4 总结了如何计算单元的长期状态、短期状态以及每个时间步骤的输出,针对单个实例(整个小批量的方程非常相似)。
方程 15-4. LSTM 计算
i (t) = σ ( W xi ⊺ x (t) + W hi ⊺ h (t-1) + b i ) f (t) = σ ( W xf ⊺ x (t) + W hf ⊺ h (t-1) + b f ) o (t) = σ ( W xo ⊺ x (t) + W ho ⊺ h (t-1) + b o ) g (t) = tanh ( W xg ⊺ x (t) + W hg ⊺ h (t-1) + b g ) c (t) = f (t) ⊗ c (t-1) + i (t) ⊗ g (t) y (t) = h (t) = o (t) ⊗ tanh ( c (t) )
在这个方程中:
- W[xi]、W[xf]、W[xo]和W[xg]是每个四层的权重矩阵,用于它们与输入向量x[(t)]的连接。
- W[hi]、W[hf]、W[ho]和W[hg]是每个四层的权重矩阵,用于它们与先前的短期状态h[(t–1)]的连接。
- b[i]、b[f]、b[o]和b[g]是每个四层的偏置项。请注意,TensorFlow 将b[f]初始化为一个全为 1 的向量,而不是 0。这可以防止在训练开始时忘记所有内容。
LSTM 单元有几个变体。一个特别流行的变体是 GRU 单元,我们现在将看一下。
GRU 单元
门控循环单元 (GRU)单元(见图 15-13)由 Kyunghyun Cho 等人在2014 年的一篇论文中提出,该论文还介绍了我们之前讨论过的编码器-解码器网络。
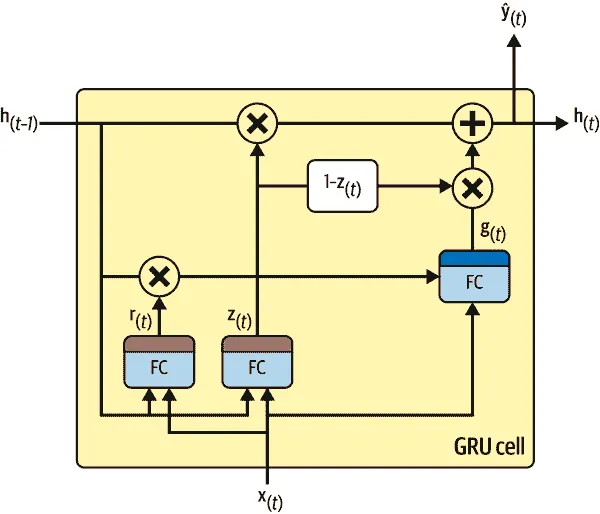
图 15-13. GRU 单元
GRU 单元是 LSTM 单元的简化版本,看起来表现同样出色(这解释了它日益增长的受欢迎程度)。这些是主要的简化:
- 两个状态向量合并成一个单一向量h[(t)]。
- 一个单一的门控制器z[(t)]控制遗忘门和输入门。如果门控制器输出 1,则遗忘门打开(= 1),输入门关闭(1 - 1 = 0)。如果输出 0,则相反发生。换句话说,每当必须存储一个记忆时,将首先擦除将存储它的位置。这实际上是 LSTM 单元的一个常见变体。
- 没有输出门;完整状态向量在每个时间步输出。然而,有一个新的门控制器r[(t)],控制哪部分先前状态将被显示给主层(g[(t)])。
方程 15-5 总结了如何计算每个时间步的单个实例的单元状态。
方程 15-5. GRU 计算
z (t) = σ ( W xz ⊺ x (t) + W hz ⊺ h (t-1) + bz ) r (t) = σ ( W xr ⊺ x (t) + W hr ⊺ h (t-1) + br ) g (t) = tanh W xg ⊺ x (t) + W hg ⊺ ( r (t) ⊗ h (t-1) ) + bg h (t) = z (t) ⊗ h (t-1) + ( 1 - z (t) ) ⊗ g (t)
Keras 提供了一个tf.keras.layers.GRU层:使用它只需要将SimpleRNN或LSTM替换为GRU。它还提供了一个tf.keras.layers.GRUCell,以便根据 GRU 单元创建自定义单元。
LSTM 和 GRU 单元是 RNN 成功的主要原因之一。然而,虽然它们可以处理比简单 RNN 更长的序列,但它们仍然有相当有限的短期记忆,并且很难学习 100 个时间步或更多的序列中的长期模式,例如音频样本、长时间序列或长句子。解决这个问题的一种方法是缩短输入序列;例如,使用 1D 卷积层。
使用 1D 卷积层处理序列
在第十四章中,我们看到 2D 卷积层通过在图像上滑动几个相当小的卷积核(或滤波器),产生多个 2D 特征图(每个卷积核一个)。类似地,1D 卷积层在序列上滑动多个卷积核,每个卷积核产生一个 1D 特征图。每个卷积核将学习检测单个非常短的连续模式(不超过卷积核大小)。如果使用 10 个卷积核,则该层的输出将由 10 个 1D 序列组成(长度相同),或者您可以将此输出视为单个 10D 序列。这意味着您可以构建一个由循环层和 1D 卷积层(甚至 1D 池化层)组成的神经网络。如果使用步幅为 1 和"same"填充的 1D 卷积层,则输出序列的长度将与输入序列的长度相同。但是,如果使用"valid"填充或大于 1 的步幅,则输出序列将短于输入序列,因此请确保相应调整目标。
例如,以下模型与之前的模型相同,只是它以一个 1D 卷积层开始,通过步幅为 2 对输入序列进行下采样。卷积核的大小大于步幅,因此所有输入都将用于计算该层的输出,因此模型可以学习保留有用信息,仅丢弃不重要的细节。通过缩短序列,卷积层可能有助于GRU层检测更长的模式,因此我们可以将输入序列长度加倍至 112 天。请注意,我们还必须裁剪目标中的前三个时间步:实际上,卷积核的大小为 4,因此卷积层的第一个输出将基于输入时间步 0 到 3,第一个预测将是时间步 4 到 17(而不是时间步 1 到 14)。此外,由于步幅,我们必须将目标下采样一半:
conv_rnn_model = tf.keras.Sequential([ tf.keras.layers.Conv1D(filters=32, kernel_size=4, strides=2, activation="relu", input_shape=[None, 5]), tf.keras.layers.GRU(32, return_sequences=True), tf.keras.layers.Dense(14) ]) longer_train = to_seq2seq_dataset(mulvar_train, seq_length=112, shuffle=True, seed=42) longer_valid = to_seq2seq_dataset(mulvar_valid, seq_length=112) downsampled_train = longer_train.map(lambda X, Y: (X, Y[:, 3::2])) downsampled_valid = longer_valid.map(lambda X, Y: (X, Y[:, 3::2])) [...] # compile and fit the model using the downsampled datasets
如果您训练和评估此模型,您会发现它的性能优于之前的模型(略有优势)。事实上,实际上可以仅使用 1D 卷积层并完全放弃循环层!
WaveNet
在2016 年的一篇论文,¹⁶ Aaron van den Oord 和其他 DeepMind 研究人员介绍了一种名为WaveNet的新颖架构。他们堆叠了 1D 卷积层,每一层的扩张率(每个神经元的输入间隔)都加倍:第一个卷积层一次只能看到两个时间步,而下一个卷积层则看到四个时间步(其感受野为四个时间步),下一个卷积层看到八个时间步,依此类推(参见图 15-14)。通过加倍扩张率,较低层学习短期模式,而较高层学习长期模式。由于加倍扩张率,网络可以非常高效地处理极大的序列。

图 15-14。WaveNet 架构
论文的作者实际上堆叠了 10 个具有 1、2、4、8、…、256、512 扩张率的卷积层,然后他们又堆叠了另一组 10 个相同的层(扩张率也是 1、2、4、8、…、256、512),然后再次堆叠了另一组相同的 10 层。他们通过指出,具有这些扩张率的单个 10 个卷积层堆栈将像具有大小为 1,024 的卷积核的超高效卷积层一样(速度更快,更强大,参数数量显著减少)。他们还在每一层之前用与扩张率相等的零填充输入序列,以保持整个网络中相同的序列长度。
以下是如何实现一个简化的 WaveNet 来处理与之前相同的序列的方法:¹⁷
wavenet_model = tf.keras.Sequential() wavenet_model.add(tf.keras.layers.Input(shape=[None, 5])) for rate in (1, 2, 4, 8) * 2: wavenet_model.add(tf.keras.layers.Conv1D( filters=32, kernel_size=2, padding="causal", activation="relu", dilation_rate=rate)) wavenet_model.add(tf.keras.layers.Conv1D(filters=14, kernel_size=1))
这个Sequential模型从一个明确的输入层开始——这比仅在第一层上设置input_shape要简单。然后,它继续使用“因果”填充的 1D 卷积层,这类似于“相同”填充,只是零值仅附加在输入序列的开头,而不是两侧。这确保了卷积层在进行预测时不会窥视未来。然后,我们添加使用不断增长的扩张率的类似对层:1、2、4、8,再次是 1、2、4、8。最后,我们添加输出层:一个具有 14 个大小为 1 的滤波器的卷积层,没有任何激活函数。正如我们之前看到的那样,这样的卷积层等效于具有 14 个单元的Dense层。由于因果填充,每个卷积层输出与其输入序列相同长度的序列,因此我们在训练期间使用的目标可以是完整的 112 天序列:无需裁剪或降采样。
我们在本节讨论的模型对乘客量预测任务提供了类似的性能,但它们在任务和可用数据量方面可能会有很大差异。在 WaveNet 论文中,作者在各种音频任务(因此该架构的名称)上实现了最先进的性能,包括文本转语音任务,在多种语言中产生令人难以置信的逼真声音。他们还使用该模型逐个音频样本生成音乐。当您意识到一秒钟的音频可能包含成千上万个时间步时,这一壮举就显得更加令人印象深刻——即使是 LSTM 和 GRU 也无法处理如此长的序列。
警告
如果您在测试期间评估我们最佳的芝加哥乘客量模型,从 2020 年开始,您会发现它们的表现远远不如预期!为什么呢?嗯,那时候是 Covid-19 大流行开始的时候,这对公共交通产生了很大影响。正如前面提到的,这些模型只有在它们从过去学到的模式在未来继续时才能很好地工作。无论如何,在将模型部署到生产环境之前,请验证它在最近的数据上表现良好。一旦投入生产,请确保定期监控其性能。
有了这个,您现在可以处理各种时间序列了!在第十六章中,我们将继续探索 RNN,并看看它们如何处理各种 NLP 任务。
练习
- 您能想到一些序列到序列 RNN 的应用吗?序列到向量 RNN 和向量到序列 RNN 呢?
- RNN 层的输入必须具有多少维度?每个维度代表什么?输出呢?
- 如果您想构建一个深度序列到序列 RNN,哪些 RNN 层应该具有
return_sequences=True?序列到向量 RNN 呢? - 假设您有一个每日单变量时间序列,并且您想要预测接下来的七天。您应该使用哪种 RNN 架构?
- 在训练 RNN 时主要的困难是什么?您如何处理它们?
- 您能勾画出 LSTM 单元的架构吗?
- 为什么要在 RNN 中使用 1D 卷积层?
- 您可以使用哪种神经网络架构来对视频进行分类?
- 为 SketchRNN 数据集训练一个分类模型,该数据集可在 TensorFlow Datasets 中找到。
- 下载巴赫赞美诗数据集并解压缩。这是由约翰·塞巴斯蒂安·巴赫创作的 382 首赞美诗。每首赞美诗长 100 至 640 个时间步长,每个时间步长包含 4 个整数,其中每个整数对应于钢琴上的一个音符的索引(除了值为 0,表示没有播放音符)。训练一个模型——循环的、卷积的,或两者兼而有之——可以预测下一个时间步长(四个音符),给定来自赞美诗的时间步长序列。然后使用这个模型生成类似巴赫的音乐,一次一个音符:您可以通过给模型提供赞美诗的开头并要求它预测下一个时间步长来实现这一点,然后将这些时间步长附加到输入序列并要求模型预测下一个音符,依此类推。还要确保查看谷歌的 Coconet 模型,该模型用于关于巴赫的一个不错的谷歌涂鸦。
这些练习的解决方案可在本章笔记本的末尾找到,网址为https://homl.info/colab3。
¹ 请注意,许多研究人员更喜欢在 RNN 中使用双曲正切(tanh)激活函数,而不是 ReLU 激活函数。例如,参见 Vu Pham 等人的2013 年论文“Dropout Improves Recurrent Neural Networks for Handwriting Recognition”。基于 ReLU 的 RNN 也是可能的,正如 Quoc V. Le 等人的2015 年论文“初始化修正线性单元的循环网络的简单方法”中所示。
² Nal Kalchbrenner 和 Phil Blunsom,“循环连续翻译模型”,2013 年经验方法自然语言处理会议论文集(2013):1700–1709。
³ 芝加哥交通管理局的最新数据可在芝加哥数据门户上找到。
⁴ 有其他更有原则的方法来选择好的超参数,基于分析自相关函数(ACF)和偏自相关函数(PACF),或最小化 AIC 或 BIC 指标(在第九章中介绍)以惩罚使用太多参数的模型并减少过拟合数据的风险,但网格搜索是一个很好的起点。有关 ACF-PACF 方法的更多详细信息,请查看 Jason Brownlee 的这篇非常好的文章。
⁵ 请注意,验证期从 2019 年 1 月 1 日开始,因此第一个预测是 2019 年 2 月 26 日,八周后。当我们评估基线模型时,我们使用了从 3 月 1 日开始的预测,但这应该足够接近。
⁶ 随意尝试这个模型。例如,您可以尝试预测接下来 14 天的公交和轨道乘客量。您需要调整目标,包括两者,并使您的模型输出 28 个预测,而不是 14 个。
⁷ César Laurent 等人,“批量归一化循环神经网络”,IEEE 国际声学、语音和信号处理会议论文集(2016):2657–2661。
⁸ Jimmy Lei Ba 等人,“层归一化”,arXiv 预印本 arXiv:1607.06450(2016)。
⁹ 更简单的方法是继承自SimpleRNNCell,这样我们就不必创建内部的SimpleRNNCell或处理state_size和output_size属性,但这里的目标是展示如何从头开始创建自定义单元。
¹⁰ 动画电影海底总动员和海底奇兵中一个患有短期记忆丧失的角色。
¹¹ Sepp Hochreiter 和 Jürgen Schmidhuber,“长短期记忆”,神经计算 9,第 8 期(1997 年):1735–1780。
¹² Haşim Sak 等,“基于长短期记忆的大词汇语音识别循环神经网络架构”,arXiv 预印本 arXiv:1402.1128(2014 年)。
¹³ Wojciech Zaremba 等,“循环神经网络正则化”,arXiv 预印本 arXiv:1409.2329(2014 年)。
¹⁴ Kyunghyun Cho 等,“使用 RNN 编码器-解码器学习短语表示进行统计机器翻译”,2014 年经验方法自然语言处理会议论文集(2014 年):1724–1734。
¹⁵ 请参阅 Klaus Greff 等的“LSTM:搜索空间奥德赛”,IEEE 神经网络与学习系统交易 28,第 10 期(2017 年):2222–2232。这篇论文似乎表明所有 LSTM 变体表现大致相同。
¹⁶ Aaron van den Oord 等,“WaveNet:原始音频的生成模型”,arXiv 预印本 arXiv:1609.03499(2016 年)。
¹⁷ 完整的 WaveNet 使用了更多技巧,例如类似于 ResNet 中的跳过连接和类似于 GRU 单元中的门控激活单元。有关更多详细信息,请参阅本章的笔记本。




