0. 前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
本文的主旨是基于TorchViz模块详细说明计算图以及叶子节点等相关概念。
创作本文的目的主要有两个:
- 计算图这个概念在深度学习中经常被提及,但是对于新手(甚至部分老手)而言,可能很少人能明白计算图究竟是个什么东西,用来干嘛的;
- CSDN上关于计算图的介绍文章不少,但基本都是引用TorchViz生成计算图后就完事了,缺乏对计算图的理解。
1. 计算图是什么?
答:计算图是用于表示计算过程的图,例如下面这个:

这个图可以理解为最简单的单层神经元网络,其中:x为训练输入数据,w和b 是要优化的参数,y 为训练输出数据,loss为损失值。
PyTorch官方对计算图(Computational Graph)的介绍是:一个有向开环图(DAG),这个有向开环图记录了①所有的输入数据(张量),②这些数据(张量)的计算过程,③通过这些计算过程生成的新数据(张量)。
在计算图中,“叶子”代表了输入数据(张量),“根”代表了输出数据(张量)。追溯从“根”到“叶子”的过程,通过链式法则可以计算出(损失值对神经元网络模型参数的)偏导。
PyTorch官网原文链接:https://pytorch.org/tutorials/beginner/blitz/autograd_tutorial.html?highlight=grad_fn
2. TorchViz的安装
TorchViz是一个用于可视化 PyTorch计算图的工具库,后面的说明都是使用TorchViz生成的计算图来讲解,所以先介绍下TorchViz的安装。
其方法非常简单。。。使用Conda直接安装TorchViz:首先进入到Pycharm/settings/Python Interpreter,然后点“+”。
再搜torchviz,点“Install Package”

因为TorchViz中引用了GraphViz库中的方法,所以也得把GraphViz安装上。

其实不太想水这一章的内容,但是我实在不理解为什么大家都千篇一律喜欢用pip?
3. 计算图详解
首先我们先生成一个最简单的 h = w × x + b h = w×x + b h=w×x+b的计算图,代码如下:
import torch from torchviz import make_dot x = torch.tensor([1],dtype=torch.float32,requires_grad=True) w = torch.tensor([4],dtype=torch.float32,requires_grad=True) b = torch.tensor([0.5],dtype=torch.float32,requires_grad=True) h = w*x + b graph_forward = make_dot(h) graph_forward.render(filename='C:\\Users\\Lenovo\\Desktop\\DL\\calc_graph\\graph_forward', view=False, format='pdf')
这里的路径filename一定要写道最终文件的名字,而不是最终文件夹!!!也就是说calc_graph最后一层文件夹,生成的文件是graph_forward.pdf
生成的计算图如下:
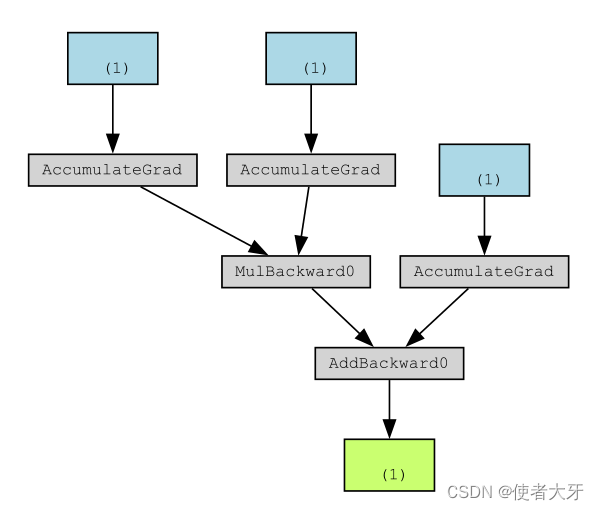
其中,蓝底色的3个(1)即是第1章中说明的计算图中的“叶子”,绿底色的(1)是“根”。
这里的“叶子”即为我们经常听说的叶子节点(leaf node)。PyTorch为了节省内存,只会记录叶子节点的相关操作,计算梯度时也只对叶子节点进行计算。
回到 h = w × x + b h = w×x + b h=w×x+b的计算图,如果它代表的是某个深度学习网络模型中的某个隐层的计算过程,那显然我们不用知道对 x x x的偏导,这样我们就可以把它从计算图中剥离出来,把计算资源都给到对参数 w w w和 b b b的计算。把 x x x从计算图中剥离出来的方式也很简单,只要指定requires_grad为False就可以了。
x = torch.tensor([1],dtype=torch.float32,requires_grad=False)
这里再说明另外一个方法——.detach()。有人也会介绍.detach()的作用也是把张量从计算图中剥离出来,甚至有人不明所以会说.detach()和requires_grad=False作用等效。
这里最大的区别就是requires_grad=False会把这个张量直接从计算图中砍掉,这点在下面的计算图中也可以看出来。
而.detach()的作用更类似于“复制”,张量在.detach()操作后在原来的计算图中仍然存在,只是把这个节点的数据复制出来用作别的计算而不会影响原来的计算图。
这样新的计算图就成了这样:

其中左上角的蓝框代表权重w (x 已经被砍掉),(1)代表1维向量且只有1个元素,右边蓝框代表偏差b ,下边绿框代表“根”h ,箭头方向代表正向传播方向。
反向传播是从“根”通过链式法则回溯到“叶子”的过程,这里从“根”往上回溯,经历了如下操作过程(灰色框):
- AddBackward0:加法过程,代表 h = w × x + b h = w×x + b h=w×x+b中的“+”;
- MulBackward0:乘法过程,代表 h = w × x + b h = w×x + b h=w×x+b中的“×”;
- AccumulateGrad:梯度积累,在Pytorch中,权重梯度的计算是累加的,这是为了提升训练效率,在每个batch中梯度都进行累加,不同batch间进行梯度清零,这也就是为什么训练的时候要用.zero_grad()的原因;
在 <操作>Backward<层数>中,常见的<操作>有以下几种:
Add代表加法;
Sub代表减法;
Mul代表乘法;
Mm代表矩阵乘法;
Div代表除法;
T代表矩阵转置;
Pow代表乘方;
Squeeze, Unsqueeze, Relu, Sigmoid就代表原本的含义;
<层数>为从"根"到"叶子"的操作层数,本示例中只有1层,所以Backward后面都为0。这里需要注意<层数>是从"根"到"叶子"从下往上数的,所以离"根"越近<层数>越小。
这样我们就把计算图说明白了,无论多复杂的模型,原理都是一样的,只不过是输入输出,操作的复杂度不同而已。
最后需要说明的一点是:计算图在PyTorch中是动态的,在每次调用.backward()之后都会生成一个新的计算图,这样就可以允许在每次学习迭代中调整计算图。
