
问题一:PolarDB有没有IMCI的最佳实践相关文档呢?
PolarDB有没有IMCI的最佳实践相关文档呢? 比如列存下索引的创建方式等等。
参考答案:
列存其实就是一个只读实例,不能建索引,只能建一组排序键https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/imcis/?spm=a2c4g.11186623.0.0.1eef8050rhNwJg
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/598261?spm=a2c6h.12873639.article-detail.82.787343787T80t7
问题二:PolarDB有一个SQL.语句。没有group by 的时候很快0.4S。请问还有什么优化方案吗?
PolarDB有一个SQL.语句。 没有group by 的时候很快 0.4S。有group by 就很慢很慢 60S。我调整 tmp_table_size 参数,几乎没有作用。 请问还有什么优化方案吗?explain
select a.,d. ,b.advanceid,b1.BUF10,b2.qty,b3.BUF10,c.attrpricetrace,bu.b2b_isputon,mu.b2b_isputon,bg.billdetailid,bs.Flag
from erp_bill_index a force index(idx_for_sale_analysis)
#
datascope_join_d
inner join erp_goods_Stock_inout_deal d force index(idx_for_sale_analysis)
ON d.profileid= a.profileid AND d.billid= a.billid
LEFT JOIN erp_bill_sale b force index(idx_for_sale_analysis) ON-- b.billid = a.billid AND a.profileid= b.profileid and
b.billid = a.billid and d.billdetailid= b.billdetailid -- and b.billtype in (601,607)
LEFT JOIN erp_bill_sale_exchange b1 ON b1.billid = a.billid AND a.profileid= b1.profileid and d.billdetailid= b1.billdetailid
LEFT JOIN erp_bill_real_inout b2 ON b2.frombillid = a.billid AND a.profileid= b2.profileid AND b2.frombilldetailid=d.billdetailid AND a.billtype=611
LEFT JOIN erp_bill_sale_return b3 ON b3.billid = a.billid AND a.profileid= b3.profileid and d.billdetailid= b3.billdetailid
LEFT JOIN erp_bill_detail_goods_attribute c ON c.billdetailid= d.billdetailid AND c.billid = d.billid AND c.profileid= d.profileid
left join erp_bill_index_ext e force index(idx_for_sale_analysis)
on e.billid=a.billid and e.profileid=a.profileid
LEFT JOIN bas_goods_unit bu ON d.gid=bu.gid AND d.profileid=bu.profileid AND bu.uid=d.muid
left join bas_goods_unit mu on mu.gid=d.gid and mu.profileid=b.profileid and mu.usetype&1>0
LEFT JOIN erp_contract_bill_goodscash bg ON bg.billid=d.billid AND bg.billdetailid=d.billdetailid AND bg.profileid=d.profileid
left join bas_store bs on d.sid = bs.sid
#
shownode inner join bas_goods g on g.profileid=d.profileid and g.gid=d.gid
#
dealer left join bas_dealer bd on bd.did=a.did and bd.profileid=a.profileid
LEFT JOIN bas_goods_unit big ON d.gid=big.gid AND d.profileid=big.profileid AND big.sort=3 and big.Flag = 0
LEFT JOIN bas_goods_unit middle ON d.gid=middle.gid AND d.profileid=middle.profileid AND middle.sort=2 and middle.flag = 0
left join bas_clerk bc on bc.cid=a.cid and bc.profileid=a.profileid
#
showbranch left join bas_branch br on br.profileid=a.profileid and br.bid=a.bid
where a.billtype in(601,607,603,715,602) AND a.status >=20 and a.ifred = 0 and a.profileid = 200015950
AND ( TRUE or bc.cid=638839)
#
ginfo
and true and a.billdate>='2023-01-01' and a.billdate<'2024-01-09'
这个是没有group by 的, show profile 查看。耗时都在sending_data
参考答案:
而不加GROUP BY检索到500条数据就结束了,两个肯本不在一个量级上,你先包一层先LIMIT在去group by那也很快就会结束了,如果您希望提高group by..limit...的性能,可以尝试在group by的表上建立对应索引。这样可以使用流式计算,有limit的时候可以提前结束。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/598260?spm=a2c6h.12873639.article-detail.83.787343787T80t7
问题三:PolarDB5.6 的这个秒加字段的版本 目前运行稳定么 ?
PolarDB5.6 的这个秒加字段的版本 目前运行稳定么 这个我们也需要, 在8.0的目标版本上之前 我们得一直用 5.6 每周都有需求加字段?
参考答案:
目前还在小范围灰度,推荐您这边在测试环境先测试,如果有需求,我可以在您的测试环境先开放这个功能。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/598259?spm=a2c6h.12873639.article-detail.84.787343787T80t7
问题四:PolarDB我想备份用从节点备份,怎么弄?
PolarDB我想备份用从节点备份,怎么弄?我看用集群地址备份,直接把主节点搞异常了 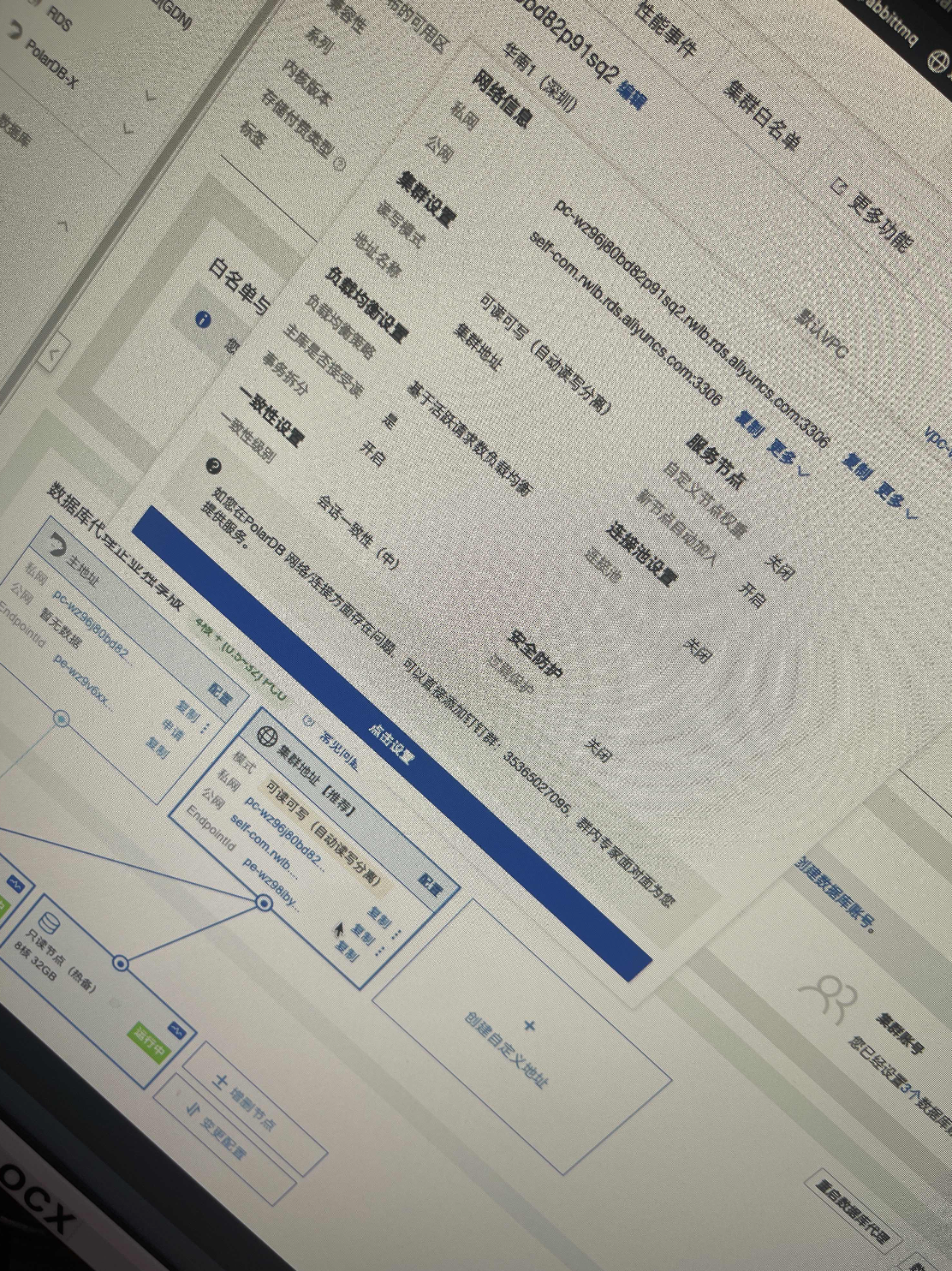
参考答案:
在PolarDB中,使用从节点进行备份是一种常见的数据保护策略。以下是创建从节点备份的步骤:
- 了解PolarDB备份机制:PolarDB支持全量备份和增量备份。全量备份是指在某个时间点上集群的全量数据生成一个备份集(快照),而增量备份则是记录生成备份集后的增量数据,即物理日志备份。
- 创建数据备份:根据存储类型,数据备份可以分为不同情况。如果存储类型为标准版ESSD云盘,备份将按照该类型进行。如果存储类型为企业版或标准版PSL4、PSL5,数据备份可以分为一级备份和二级备份。
- 配置物理日志备份:物理日志备份是通过实时并行上传Redo日志到OSS来达到备份的目的。您可以选择同地域备份或跨地域备份,并设置日志的保留时间,最短保留时间为3天,最长保留时间为7300天。如果需要,您还可以开启“删除集群前长期保留”功能以长期保存日志备份。
- 恢复数据:通过一个完整的数据备份以及后续一段时间的Redo日志备份,您可以将整个PolarDB集群或特定库表恢复到任意时间点。这一过程可以精确到秒级。
- 监控和管理备份:确保定期检查备份的状态和完整性,以便在需要时能够迅速恢复数据。同时,也要确保备份策略符合业务需求和合规要求。
- 测试恢复流程:在实际需要恢复数据之前,建议进行恢复流程的测试,以确保在紧急情况下能够顺利进行数据恢复。
请注意,进行任何备份操作之前,最好先阅读官方文档或咨询技术支持,以确保理解所有的步骤和潜在的影响。此外,备份和恢复操作可能会对数据库性能产生影响,因此建议在业务低峰期进行这些操作。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/598256?spm=a2c6h.12873639.article-detail.85.787343787T80t7
问题五:PolarDB有空看下为啥 serverless 试用时无法选择已有的 vpc?
PolarDB有空看下为啥 serverless 试用时无法选择已有的 vpc? 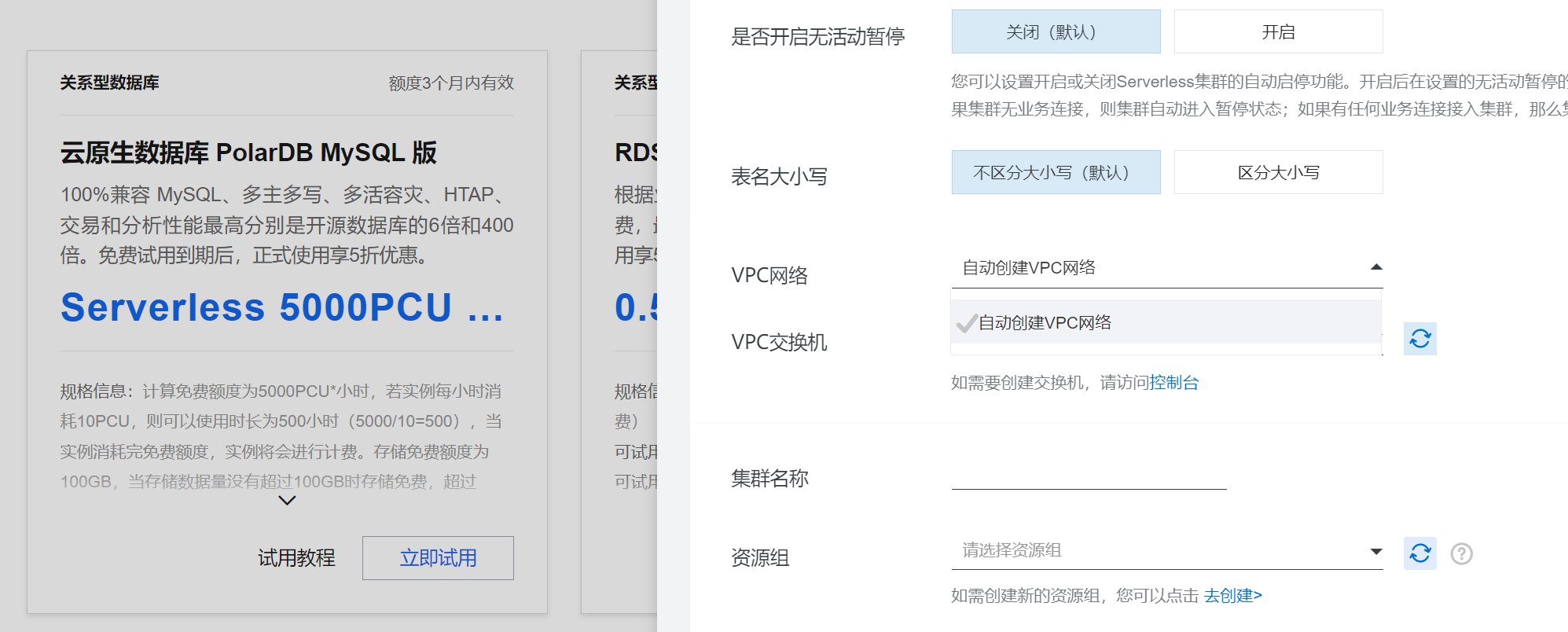
参考答案:
据我所知阿里云PolarDB的Serverless模式在试用时无法选择已有的VPC,这是因为Serverless模式的实例是通过阿里云Function Compute服务进行部署和管理的,而Function Compute服务与传统的VPC网络有所不同Serverless实例没有与VPC直接关联的概念,因此无法选择已有的VPC。
在Serverless模式下,PolarDB实例将使用一个单独的专有网络(VPC),该VPC由阿里云自动创建和管理,该VPC会与你所选择的地域和可用区相关联,你可以通过访问控制策略和安全组来控制PolarDB实例的网络访问权限。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/598255?spm=a2c6h.12873639.article-detail.86.787343787T80t7
