词法分析
编译器的前端可以分成如下过程:
=》前端=》词法分析器=》记号=》语法分析器=》抽象语法树=》语义分析器=》中间表示=》
词法分析的任务是将程序员所写的程序切分成记号流。
if (x > 5) y = "hello"; else z = 1;
经过词法分析器分析之后,会被字符切分为如下内容
IF LPAREN IDENT(x) GT INT(5) RPAREN IDENT(y) ASSIGN STRING("hello") SEMICOLON ELSE IDENT(z) ASSIGN INT(1) SEMICOLON EOF
记号
记号的数据结构定义,类似如下代码
enum kind {IF, LPAREM, ID, INTLIT, ...} struct token { enum kind k; char *lexeme; }
词法分析器的任务:字符流到记号流的转换
- 字符流:和被编译的语言密切相关(Unicode, ASCII)
- 记号流:编译器内部定义的数据结构,编码所识别出的词法单元
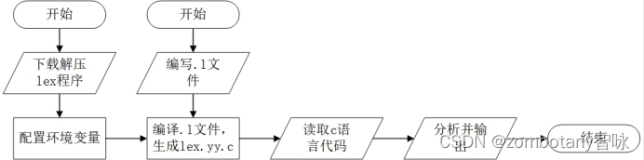
词法分析器的实现方法
至少两种的实现方案:
- 手工编码实现法
- 相对复杂,且容易出错
- 但是目前非常流行的实现方法
- GCC,LLVM,…
- 词法分析器的生成器
- 可快速原型,代码量少
- 但是较难控制细节
手工编码实现法
如果我们有<=、<>、<、=、>、>=、>符号,如下图,我们的提取步骤,根据第一个字符,我们可以按照下图步骤读取对应的符号。

其他的标识符转移图和上述的类似。
标识符和关键字
- 很多语言中标识符和关键字是有交集的
- 从词法分析的角度看,关键字是标识符的一部分
- 以C语言为例:
- 标识符:以字母或者下划线开头,后面跟了零个或者多个字母,下划线或者数字
- 关键字:if while else
如何识别关键字
- 在标识符识别的时候,单独加上标识符的识别
- 关键字表算法
对给定语言中的所有的关键字,构造关键字构成的hash表
对所有的标识符和关键字,先统一按照标识符的转移图进行识别
识别完成之后进一步查询hash表看是否有关键字
通过合理的构造hash表,可以在O(1)时间内完成查询
词法分析器的生成器
正则表达式
- 对给定的字符集 A = {c1, c2…cn}
- 归纳定义
空串a是正则表达式
对于任意的c 属于A, c是正则表达式
如果M和N是正则表达式,则一下也是正则表达式
选择 M | N = {M, N}
连接 MN = {mn | m属于M, n属于N}
闭包 M* = {c, M,MM, MMM, … }
如何使用正则表达式?
- 关键字
- C语言中的关键字 if while 如何使用正则表达式表示呢 if
- 表示符
- C语言中的标识符需要以字母或下划线开头,后面跟零个或者多个字母i,数字或者下划线。 如何使用正则表达式表示呢?
正则表达式语法糖
参见正则表达式文章连接:正则表达式-CSDN博客
有限状态自动机(FA)
输入的字符串=》FA=》{YES, NO}
- 确定的有限状态自动机:DFA
- 对任意字符,对多只有一个状态可以转移
- 非确定的有限状态自动机:NFA
- 对任意的字符,有多余一个状态可以转移
DFA的实现
可以看成一个有边和节点的有向图;
- 边上有信息
- 节点上也有信息
正则表达式到非确定有限状态自动机
- Thompson算法:正则表达式=》NFA
- 子集构造算法:NFA=>DFA
- Hopcroft最小化算法:DFA=>词法分析器代码
Thompson算法
- 基于对RE的构造做归纳
- 对基于的RE直接构造
- 对复合的RE递归构造
- 递归算法,容易实现
子集构造算法
- 不动点算法
- 算法为什么能工运行终止
- 时间复杂度
- 最坏情况O(2^n)
- 但是在实际中不常发生
- 因为并不是每个子集都会出现
- ε-闭包的计算:深度优先或者是广度优先
Hopcroft最小化算法
DFA的代码表示
- 概念上讲,DFA是一个有向图
- 实际上,有不同的DFA的代码表示
- 转移表
- 哈希表
- 跳表等
- 取决于在实际实现中,对时间空间的权衡
转移表
nextToken() state = 0 stack = [] while (state != ERROR) c = getChar() if (state is ACCEPT) clear(stack) push(state) state = table[state][c] while (state is not ACCEPT) state = pop() rollback() z
上述伪代码中的stack 是为了 最长匹配
跳转表
netxToken() state = 0 stack = [] goto q0 q0: c = getChar() if (state is ACCEPT) clear(stack) push (state) if (c == 'a') goto q1 q1: c = getChar() if (state is ACCEPT) clear(stack) push(state) if (c == 'b' || c == 'c') goto q1