免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector

一、简介
在大语言模型应用的场景中,我们会自然想到一个常见的场景--智能问答机器人。对于不同公司而言,这种问答机器人所依赖的知识库是很个性的,因为每个公司的业务场景、业务流程、业务规则等都不相同。如何利用大语言模型技术构建这样一个问答机器人呢?显然我们不能直接问gpt某个公司的内部业务知识库中的信息,因为它的训练数据中不包含这些内容,而且知识库还会经常更新。那能否用这些知识库数据对预训练模型进行继续训练从而让大模型适应公司特定的数据集或案例呢?
一般不建议这么做,因为这种方式(openai称为微调模型)更适合于教授专门的任务或风格,而对于事实回忆则不太可靠。当对模型进行微调时,就像是在为一周后的考试复习。当考试来临时,模型可能会忘记细节,或记错从未读过的事实。
微调模型不合适,能否在对gpt做问答时,直接把知识库的信息给到gpt让gpt直接回答呢?这样实时给gpt信息就不会像微调模型一样可能记错事实了。显然也不行,因为gpt的上下文窗口目前最大只能有128K的token量,这显然满足不了公司搭建智能问答机器人的会话需求。
那怎样才能既能让模型清楚的记住知识库的知识,又能不受gpt上下文token量限制的制约呢?这时候,emdeddings模型就派上用场了。
二、基本概念和原理
什么是embeddings呢?
在自然语言处理和机器学习领域,"embeddings" 是指将单词、短语或文本转换成连续向量空间的过程。这个向量空间通常被称为嵌入空间(embedding space),而生成的向量则称为嵌入向量(embedding vector)或向量嵌入(vector embedding)。
嵌入向量可以捕获单词、短语或文本的语义信息,使得它们可以在数学上进行比较和计算。这种比较和计算在自然语言处理和机器学习中经常被用于各种任务,例如文本分类、语义搜索、词语相似性计算等。
用通俗的语言理解embeddings就是将文本等信息转换为机器能理解的数学表示,也就是向量化。有了向量表示,就可以对它们进行数学计算,比如通过计算两个向量的角度来度量它们之间的相似度。比如:"机器学习"表示为 [1,2,3] "深度学习"表示为[2,3,3] "英雄联盟"表示为[9,1,3] 使用余弦相似度(余弦相似度是一种用于衡量向量之间相似度的指标,可以用于文本嵌入之间的相似度)在计算机中来判断文本之间的距离:“机器学习”与“深度学习”的距离:

"机器学习”与“英雄联盟“的距离":

“机器学习”与“深度学习”两个文本之间的余弦相似度更高,表示它们在语义上更相似。
当然上面的例子只是一个三维的数据,它显然满足不了复杂的的语义场景。在机器学习领域,这个维度可以达到几百甚至上千,维度越高,对语言的理解就会越精确。不同的模型有不同的维度,比如OpenAI 的 text-embedding-ada-002 有 1536 维。
文本embedding的算法:
文本嵌入算法是指将文本数据转化为向量表示的具体算法,通常包括以下几个步骤:
1. 分词:将文本划分成一个个单词或短语。
2. 构建词汇表:将分词后的单词或短语建立词汇表,并为每个单词或短语赋予一个唯一的编号。
3. 计算词嵌入:使用预训练的模型或自行训练的模型,将每个单词或短语映射到向量空间中。
4. 计算文本嵌入:将文本中每个单词或短语的向量表示取平均或加权平均,得到整个文本的向量表示。常见的文本嵌入算法包括 Word2Vec、GloVe、FastText 等。这些算法通过预训练或自行训练的方式,将单词或短语映射到低维向量空间中,从而能够在计算机中方便地处理文本数据。
三、如何利用embedding技术构建智能问答机器人
那么有了embeddings技术之后有什么用呢?我们可以将公司知识库数据向量化,当用户提问时,我们把用户的问题也向量化,然后根据向量化后的问题到向量化后的知识库中进行搜索,将搜索结果按照相关性进行排序。(按照上文embeddings的逻辑,相关性越强,值越大)之后把用户的问题和相关性最强的知识库中的文本给到gpt,让它根据实时数据给出最终的回答。
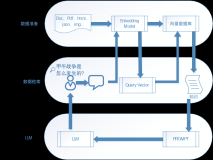
具体流程如下:
【1】准备嵌入数据
(1)收集:公司知识库中的文档;
(2)分块:文件被分割成简短、大部分自成一体的部分,以便嵌入其中;
(3)嵌入:每个部分用 OpenAI API进行嵌入;
(4)存储:保存嵌入(对于大型数据集,可使用矢量数据库)。
【2】 搜索
(1)给定用户问题,通过 OpenAI API 生成查询的嵌入式内容;
(2)进行搜索,根据查询嵌入和文本嵌入之间的距离对文本进行排序。
搜索后返回两个列表:
- 按相关性排序的前 N 个文本
- 相应的相关性得分
【3】提问
(1)将问题和最相关的文本插入给 GPT 的Prompt中;
(2)返回 GPT 的答案。
以下是整个流程的示意图,根据此我们就可以搭建一个依靠大语言模型的公司专属问答机器人了。

四、embeddings更多应用场景
1. 从数据集获取嵌入式数据
2. 使用嵌入式进行语义文本搜索
通过嵌入式的搜索查询,就能以非常高效的方式和极低的成本对所有评论进行语义搜索。比如搜索“物流太慢”的评论,通过嵌入式的搜索进行相关性对比,就能拿到相关性排序前N的评论。
3. 使用嵌入和最近邻搜索进行推荐
演示了如何使用嵌入式查找类似的推荐项目。比如给定一篇文章,还有哪些文章与之最相似?
要找到相似文章,我们可以分三步走:
4. 二维嵌入可视化
t-SNE(t-Distributed Stochastic Neighbor Embedding)是一种用于降低数据维度的非线性方法,通常用于可视化高维数据。它的目标是将高维空间中的数据点映射到二维或三维空间,同时保持相似度关系。这使得我们能够在较低维度中更好地观察数据点之间的关系,特别是在探索数据集结构和发现簇群时非常有用。
5. 使用嵌入式进行回归
根据评论文本的嵌入情况预测得分。
6. 使用嵌入式进行分类
在文本分类任务中,我们根据评论文本的嵌入情况来预测食品评论的得分(1 到 5 分)。
7. 使用嵌入式进行零点分类
在没有任何训练的情况下预测样本的标签。可以简单地嵌入每个标签的简短描述,例如正标签和负标签,然后比较样本嵌入和标签描述之间的余弦距离。与样本输入相似度最高的标签就是预测标签。
8. 为冷启动推荐获取用户和产品嵌入信息
9. 聚类
了解更多阿里云向量检索服务DashVector的使用方法,请点击:
https://help.aliyun.com/product/2510217.html?spm=a2c4g.2510217.0.0.54fe155eLs1wkT