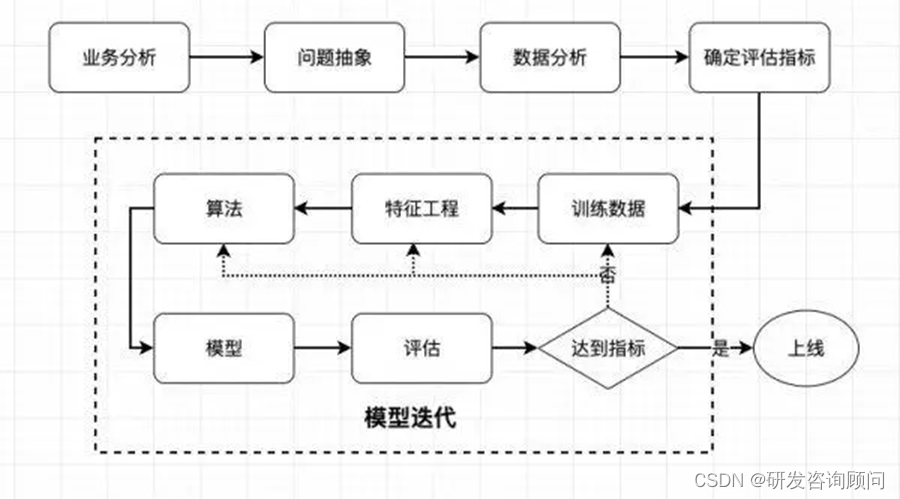
1.机器学习开发流程
机器学习开发流程是指从数据收集、数据预处理、模型选择和训练、模型评估和优化,到模型部署和应用的整个过程。下面将详细介绍机器学习开发流程和用到的数据。
2.数据收集
数据收集是机器学习开发的第一步。数据可以来自各种渠道,如传感器、数据库、API等。收集到的数据可能是结构化数据(如表格数据)或非结构化数据(如图片、文本)。在数据收集阶段,需要考虑数据的质量、数量和多样性,以确保模型训练的有效性和泛化能力。
3.数据预处理
数据预处理是清洗、转换和整合数据的过程。在这个阶段,需要对数据进行缺失值处理、异常值处理、特征选择、特征缩放、数据转换等操作,以便为模型训练做好准备。常用的工具包括Pandas和Scikit-learn等。
# 数据预处理示例代码 import pandas as pd from sklearn.preprocessing import StandardScaler from sklearn.impute import SimpleImputer # 读取数据 data = pd.read_csv('data.csv') # 处理缺失值 imputer = SimpleImputer(strategy='mean') data['age'] = imputer.fit_transform(data['age'].values.reshape(-1, 1)) # 特征缩放 scaler = StandardScaler() data[['income', 'expenditure']] = scaler.fit_transform(data[['income', 'expenditure']]) |
4.模型选择和训练
在模型选择阶段,需要根据问题的性质和数据的特点选择合适的模型,如决策树、逻辑回归、神经网络等。然后利用训练数据对模型进行训练,使其能够学习数据的模式和规律。常用的工具包括Scikit-learn、TensorFlow和PyTorch等。
# 模型选择和训练示例代码 from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(data[['age', 'income', 'expenditure']], data['label'], test_size=0.2) # 选择决策树模型 model = DecisionTreeClassifier() # 训练模型 model.fit(X_train, y_train) # 预测并评估 y_pred = model.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print('Accuracy:', accuracy) |
5.模型评估和优化
模型评估是对训练好的模型进行性能评估的过程,常用的评估指标包括准确率、精确率、召回率、F1值等。在评估的基础上,可以进行模型优化,包括调参、特征工程、集成学习等方法,以提高模型的性能和泛化能力。
# 模型优化示例代码 from sklearn.model_selection import GridSearchCV # 网格搜索调参 param_grid = {'max_depth': [3, 5, 7], 'min_samples_split': [2, 4, 6]} grid_search = GridSearchCV(model, param_grid, scoring='accuracy', cv=5) grid_search.fit(X_train, y_train) best_model = grid_search.best_estimator_ |
6.模型部署和应用
模型部署是将训练好的模型应用到实际场景中的过程。可以将模型部署到服务器上,也可以封装成API接口供其他系统调用。在部署后,可以通过输入新数据进行预测和应用。
以上就是机器学习开发流程和用到的数据的详细介绍,包括数据收集、数据预处理、模型选择和训练、模型评估和优化,以及模型部署和应用的流程和方法。通过这个流程,可以有效地开发出高质量的机器学习模型,为实际问题提供解决方案。
