
作为一名对技术充满热情的学习者,我一直以来都深刻地体会到知识的广度和深度。在这个不断演变的数字时代,我远非专家,而是一位不断追求进步的旅行者。通过这篇博客,我想分享我在某个领域的学习经验,与大家共同探讨、共同成长。请大家以开放的心态阅读,相信你们也会在这段知识之旅中找到启示。
前言
我们已经将所有的排序算法讲解完毕,通过对数组进行排序和面试题的训练,相信大家收获了干货,今天我们就来对排序算法进行总结,讨论在不同场景下应该挑选什么样的算法,这也是实际开发中我们经常需要思考的问题。
一、挑选适当的排序算法
在数据结构中挑选适当的排序算法取决于以下几个因素:
- 数据大小:
- 小规模数据集:简单排序算法(如插入排序、选择排序)表现得比较好,因为它们的常数因素较小,复杂度高的部分不会显著影响整体效率。
- 中到大规模数据集:高效的算法如快速排序、归并排序和堆排序更合适,因为它们提供了更好的分摊时间复杂性(O(n log n))。
- 数据的初始状态:
- 基本有序的数据集:插入排序或者希尔排序会表现得很好,因为它们能够利用数据的初始有序状态减少计算。
- 完全无序的数据集:快速排序、归并排序或者堆排序是较好的选择。
- 内存使用:
- 如果内存是限制,就可能需要避免使用归并排序这样的算法,因为归并排序在合并阶段需要与原数组相等大小的辅助空间。
- 原地排序算法(如快速排序和希尔排序)不需要额外的存储空间。
- 数据存储:
- 如果数据无法全部加载到内存中(外部排序),需要使用如归并排序这样可以与外部存储很好合作的算法。
- 数据的复杂度和关键字:
- 简单数据可以使用任何排序算法。
- 对于复杂的数据对象,稳定排序(如归并排序)可能更加有利,因为稳定性能保持数据的其他排序特性。
- 时间与空间的权衡:
- 如果时间是最重要的资源,则应该选择平均情况下最快的算法(如快速排序)。
- 如果空间是最重要的资源,则应该选择复杂度较低,或者不需要额外空间的算法(如堆排序、希尔排序)。
- 算法的稳定性:
- 如果稳定性(排序后两个相等键值的元素之间的相对位置不变)很重要,则应该选择稳定的排序算法(如归并排序、冒泡排序、插入排序)。
总结来看,以下是一些场景与推荐算法的对应:
- 对实时系统中小数据集进行排序:插入排序或希尔排序。
- 对大数据集进行内存中的排序:快速排序、堆排序或归并排序。
- 对巨量数据集进行外部排序:外部归并排序。
- 对有限范围整数进行排序:计数排序、基数排序或桶排序。
- 要求稳定排序:归并排序、冒泡排序、插入排序。
- 对性能有极度要求,可以预知数据分布:可以根据数据的特点定制或优化排序算法。
最后需要注意的一点是,具体选择哪种排序算法,还应该酌情考虑程序员的熟悉度、实现的难易程度以及环境的支持等多方面因素。在做出决定之前最好对目标数据集进行分析,实践检验在特定情境下各算法的绩效,以作出最合理的选择。
二、时间空间复杂度分析
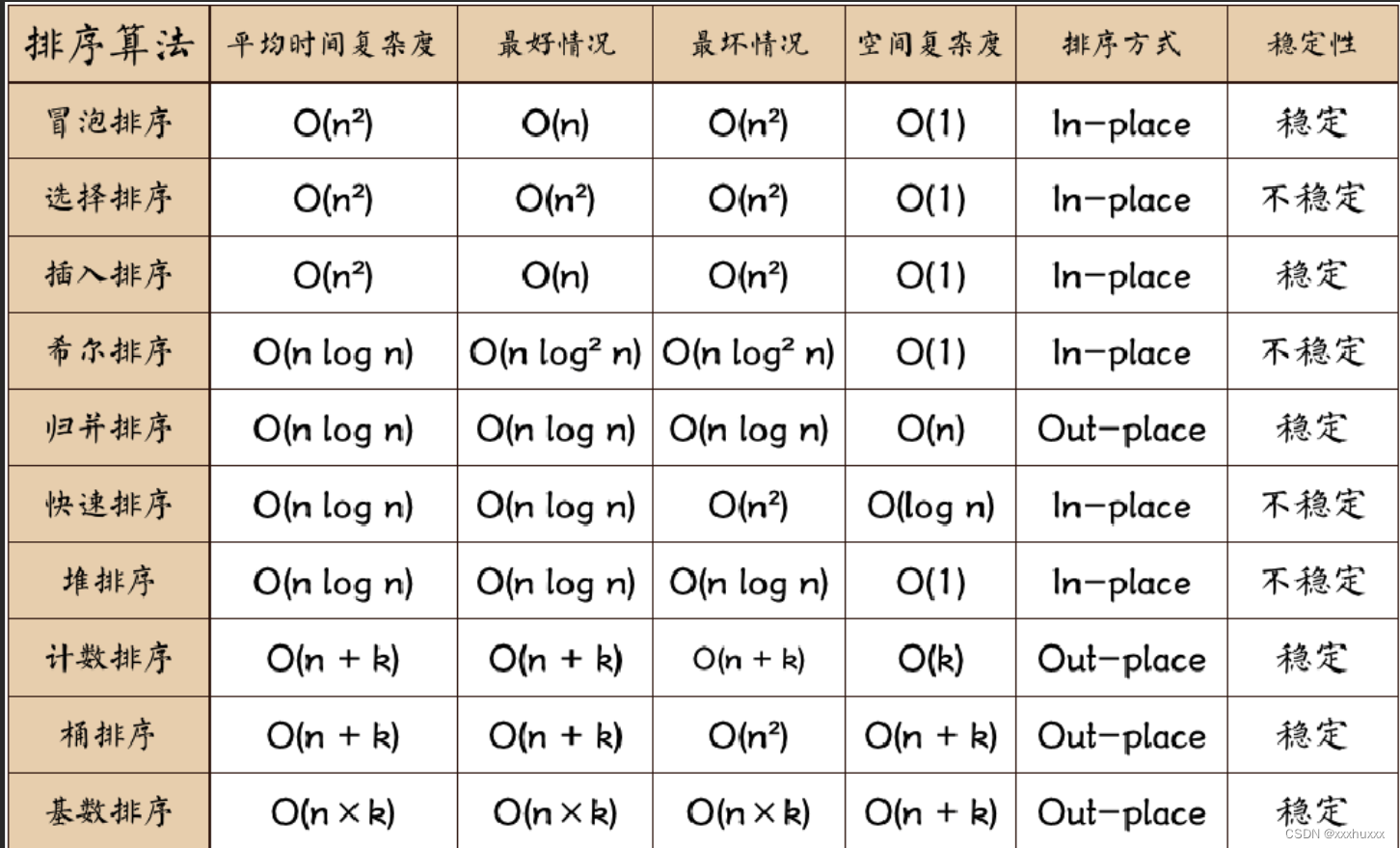
三、十大经典排序算法
十大排序算法各有特点和使用场景。在计算机科学中不同的排序算法适用于不同的问题和数据集。以下是常见的十种排序算法及其之间的区别:
- 冒泡排序:
- 算法过程:通过不断交换相邻元素位置以移动最大元素到数组末尾。
- 时间复杂度:平均和最坏情况下都是 O(n^2),最好情况下是 O(n)(已经排序好的情况)。
- 空间复杂度:O(1),是一种原地排序算法。
- 稳定性:稳定排序算法。
- 选择排序:
- 算法过程:每次从未排序部分找到最小元素,然后放到已排序部分的末尾。
- 时间复杂度:无论数据如何都是 O(n^2)。
- 空间复杂度:O(1),是一种原地排序算法。
- 稳定性:不稳定排序算法。
- 插入排序:
- 算法过程:类似于打扑克时整理手中牌的方法,逐个将元素插入到已排序部分的适当位置。
- 时间复杂度:最坏和平均情况下是 O(n^2),最好情况下是 O(n)。
- 空间复杂度:O(1),是一种原地排序算法。
- 稳定性:稳定排序算法。
- 希尔排序:
- 算法过程:基于插入排序的一种算法,通过引入间隔合并的办法,使得数组变得基本有序,再使用插入排序完成。
- 时间复杂度:取决于间隔序列,理论上可以达到 O(n log n)。
- 空间复杂度:O(1),是一种原地排序算法。
- 稳定性:不稳定排序。
- 归并排序:
- 算法过程:采用分治法的思想,将数组递归地分成半子数组直至单个元素,然后合并。
- 时间复杂度:所有情况下都是 O(n log n)。
- 空间复杂度:O(n),不是原地排序算法。
- 稳定性:稳定排序算法。
- 快速排序:
- 算法过程:同样采用分治法,选择一个元素作为轴点(pivot),根据轴点分成两部分,使得左侧小于轴点,右侧大于轴点,然后递归对两部分进行快速排序。
- 时间复杂度:平均情况下是 O(n log n),最坏情况(划分不平衡)是 O(n^2),但通常通过随机化选择轴点可以避免最坏情况。
- 空间复杂度:O(log n),在最坏情况下是 O(n)。
- 稳定性:不稳定排序算法。
- 堆排序:
- 算法过程:利用二叉堆的特性来排序,通过构建最大堆前半部分(或最小堆后半部分),反复将最大元素移除堆并保持堆的性质。
- 时间复杂度:所有情况下都是 O(n log n)。
- 空间复杂度:O(1),是一种原地排序算法。
- 稳定性:不稳定排序算法。
- 计数排序:
- 算法过程:非比较型排序,统计每个值的元素数量,然后依次输出正确数量的元素。
- 时间复杂度:O(n + k),其中 k 是数据范围大小。
- 空间复杂度:O(k),因为需要额外空间来存储各个值的计数。
- 稳定性:可以实现为稳定排序算法。
- 桶排序:
- 算法过程:将元素分布到多个桶中,对每个桶内部进行排序,然后按顺序将各个桶的元素串联起来。
- 时间复杂度:平均情况下是 O(n + k),取决于桶的数量和分布。
- 空间复杂度:O(n + k)。
- 稳定性:可以实现为稳定排序算法。
- 基数排序:
- 算法过程:通过按照数字位数逐级排序,先按低位排序,再按高位排序。
- 时间复杂度:O(d(n + k)),其中 d 是位数,k 是基数(一般为 10)。
- 空间复杂度:O(n + k)。
- 稳定性:稳定排序算法。
四、稳定排序算法
在以上列举的十大排序算法中,稳定的排序算法是指排序过程不会改变相同元素原本的相对顺序。以下是稳定的排序算法:
- 冒泡排序:在冒泡排序中,当遇到相等的元素时,它们不会交换位置,保持了原有的顺序。
- 插入排序:插入排序也维持了相等元素的初始顺序,当找到合适的插入位置时,后面的元素移动不会改变相同元素的相对位置。
- 归并排序:在归并排序过程中,合并两个有序数组时,会从两个数组的开始比较,相等时首先复制前面数组的元素,这样保持了元素的稳定性。
- 计数排序:计数排序不是基于比较的,它依靠统计每个元素的出现次数然后直接放置到输出数组,可以维持相等元素的原始顺序。
- 桶排序:桶排序将数据分散到多个桶中,并分别对每个桶进行排序。在每个桶内部排序时如果采用稳定排序,那么整个排序过程也是稳定的。
- 基数排序:基数排序通过逐个位数对数据进行排序,因为在每一位的排序过程中使用的都是稳定排序算法(如计数排序),所以整个排序过程保持了稳定性。
不稳定的排序算法包括选择排序、希尔排序、快速排序和堆排序。这些算法在排序过程中可能会改变相同元素的相对顺序。
五、实际开发中我们常见问题
在实际开发中,排序算法相关的问题非常广泛,从简单的数据显示排序到复杂的业务逻辑中的数据排列。以下是一些可能遇到的问题以及解决方式:
- 性能问题:
当处理大量数据时,性能可能成为问题。解决这个问题的关键通常在于选择适当的排序算法,比如快速排序、归并排序或者非比较排序,比如计数排序或基数排序(如果数据特点允许)。 - 内存使用:
对于内存敏感的应用,如在内存受限的环境下排序大数据集,需要选择空间复杂度低的算法,如原地排序算法(堆排序、快速排序、插入排序等)。 - 比较次数和交换(或移动)操作:
在某些情况下,比如数据读取非常耗费资源的时候,减少数据移动可以提高性能。插入排序在这方面表现良好,尤其当数据已经部分排序时。 - 算法稳定性:
如果保持等值元素间的相对顺序很重要,应该选择稳定的排序算法,比如归并排序、冒泡排序或插入排序。 - 数据结构特点:
数据的结构和存储方式也会影响排序算法的选择。例如,链表结构可能更适合使用归并排序,因为它可以避免额外的内存使用并且可以顺序访问。 - 数据集的特征:
数据的大小(小数据集或大数据集)、是否有部分已排序(接近有序的数据集)或是否允许额外空间(非原地排序),都是选择排序算法时需要考虑的问题。 - 外部排序:
当数据集太大以至于不能完全加载到内存时,需要使用外部排序技术。外部排序通常依赖于归并排序,将数据分成可管理的块,分别排序,然后合并。 - 并行和分布式排序:
在有多个处理器或者需要跨多台机器排序时,需要考虑并行和分布式排序方法,如并行归并排序或MapReduce中的排序。
针对上述问题,实际解决策略包括:
- 分析数据及其特点:根据数据量大小、是否存在大量重复值、是否接近有序等因素来选择算法。
- 测试和比较不同算法:对具体应用和数据集测试各种排序算法,从而选出最优的排序方法。
- 利用现成的库和函数:编程语言通常提供优化和通用的排序函数。例如,在C++中是
std::sort,在Python中是sorted()和list.sort(),它们通常经过优化,性能很好。 - 考虑非传统排序:对于特殊的需求,可能需要考虑计数排序、基数排序或桶排序这样的非比较排序算法。
- 空间与时间权衡:评估可用内存与运行时间的权衡,选择最合适的算法。
- 考虑实现复杂性:在有限的开发时间和资源下,可能需要在高度优化与实现复杂性之间找到平衡。
通过理解和评估这些问题和策略,开发人员可以在不同的情况下做出更好的排序算法选择,以满足实际应用中的性能和资源需求。
总结
对十大排序算法的学习篇也就到此结束,但还是有更多的任务等着我们去完成,在实际开发和学习中我们还是会遇到各种问题等待我们去探索和解决。博主也会不断更新,接下来我们还会开始新的专栏,继续对数据结构这门课程成进行学习,希望同学们可以持之以恒,继续加油!
感谢大家抽出宝贵的时间来阅读博主的博客,新人博主,感谢大家关注点赞,祝大家未来的学习工作生活一帆风顺,加油!!!

