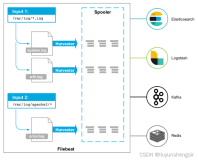
一、环境准备
部署模式:单节点部署。
安装包:ELK安装包下载地址
注意事项:
1. 部署及安装所用的用户不能是root。
| 192.168.122.239 | Centos7.6 |
二、安装部署
2.1 下载安装包到指定文件夹,并解压
# 切换到非root用户,这里用的elasticsearch su - elasticsearch # 进入安装目录 cd /opt/module # 解压安装包 tar xf filebeat-8.11.0-linux-x86_64.tar.gz # 给文件赋权 chown -R elasticsearch:elasticsearch /opt/module/filebeat-8.11.0-linux-x86_64
2.2 编辑配置文件
cd filebeat-8.11.0-linux-x86_64 vim filebeat.yml
# 数据采集输入配置 filebeat.inputs: - type: log enabled: true # 日志采集路径 paths: - /home/data/ipu/ipu-cbs-server-tst/logs/ipu-cbs-server-tst-10002/console.log # 日志采集频率 scan_frequency: 10s # 日志行匹配模式,这里匹配yy-MM-dd HH:mm:ss.SSS 格式的时间开头的内容为行首,一直匹配到下一个之前算一行日志。 multiline.pattern: '^\d{2}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d{3}' multiline.negate: true multiline.match: after # 数据采集输出配置 # 这里配置的是redis哨兵模式的1主2从共三个节点地址。filebeat本身不支持哨兵、cluster集群模式。可以采用这种配置起到高可用的作用。 # 因为从节点只读,所以实际上永远只会将数据发送到一个主节点上。 output.redis: enabled: true hosts: ["192.168.122.227:6379","192.168.122.237:6379","192.168.122.238:6379"] key: "ipu-cbs-server-test-log" datatype: list password: "Redis@123456" # 添加 Redis 访问密码 db: 0 codec: [ json ] loadbalance: true # 配置filebeat的输出日志 logging.level: info logging.to_files: true logging.files: path: /opt/module/filebeat-8.11.0-linux-x86_64 name: filebeat.log
更多es配置可以参考官方文档:Fleet and Elastic Agent Guide [8.11] | Elastic
2.3 启动服务
# 编写启动命令文件 echo "nohup ./filebeat -e -c filebeat.yml > filebeat.log 2>&1 &" > start.sh # 赋予文件权限 chmod a+x start.sh # 启动服务 ./start.sh # 查看日志 tail -200f /opt/module/filebeat-8.11.0-linux-x86_64/filebeat.log
本人多年技术架构设计经验,长期从事IT技术资源整合,廉价出售各类课程视频,有需要请私信联系