1. 前言
MySQL 中针对表的操作可以分为增、删、改、查四种操作,也就是我们所说的 CRUD 大法,根据类型分为DML(增删改)和DQL(查),不管是 DML 和 DQL 都要经过连接器、查询缓存、分析器、优化器、执行器调用存储引擎的API执行最优路径。前四个阶段流程都是一样的,接下来我们一起学习执行器在存储引擎上是如何进行查询和更新(增删改查)的。
PS:查询缓存在 MySQL5.7.20 版本已过时,在 MySQL8.0 版本中被移除,这里不再单独介绍查询缓存这一流程;连接器、查询缓存、分析器、优化器、执行器的具体作用见:一文了解MySQL的基础架构及各个组件的作用。
2. MySQL是如何执行查询语句的?
如下SQL:实现查询名字为 “javaBoy001” 和年龄为 18 的用户
select id, name, sex, age from user where name = 'javaBoy001' and age = 18;
2.1 连接器
先检查该语句是否有权限,如果没有权限,直接返回错误信息。
2.2 分析器
分析器会通过词法分析,提取 SQL 语句的关键字,比如提取上面 SQL 语句的 “select”、“from”、"where"等,并可以知道这是一条查询语句,提取查询的表名为 user,提取查询的条件为 name = ‘javaBoy001’ and age = 18。
然后根据词法分析的结果,语法分析器会根据语法规则,判断你输入的SQL语句是否满足MySQL语法,没问题的执行下一步。
2.3 优化器
MySQL判断出了一条SQL语句要做什么之后,对其进行各种优化,包括重写查询语句、选择合适的索引、表的读取顺序等确定执行方案。上面的 SQL 语句存在两种执行方案:
方案1. 先查询名字为javaBoy001的所有用户,再查询年龄为18的用户;
方案2. 先查询年龄为18的用户,再查询名字为javaBoy001的所有用户;
因此,优化器需根据自己的优化算法选择自己认为执行效率最高的一个方案(优化器认为不一定是最好)。
2.4 执行器
语句经过优化后,就要进入执行阶段,开始执行的时候,要先判断权限,如果没有,就返回没有权限的错误。如果有权限,就调用存储引擎的API,返回查询结果。
3. MySQL是如何执行更新语句的?
如下SQL:实现更新名字为 “javaBoy001” 和年龄为 18 用户的手机号为 “15211111111”
update user set phone = '15211111111' where name = 'javaBoy001' and age = 18;
3.1 连接器
先检查该语句是否有权限,如果没有权限,直接返回错误信息。
3.2 分析器
分析器会通过词法分析和语法分析知道这是一条更新语句。
3.3 优化器
MySQL判断出了一条SQL语句要做什么之后,对其进行各种优化,选择合适的索引等。
3.4 执行器
语句经过优化后,就要进入执行阶段,开始执行的时候,要先判断权限,如果没有,就返回没有权限的错误。如果有权限,就调用存储引擎的API操作数据。
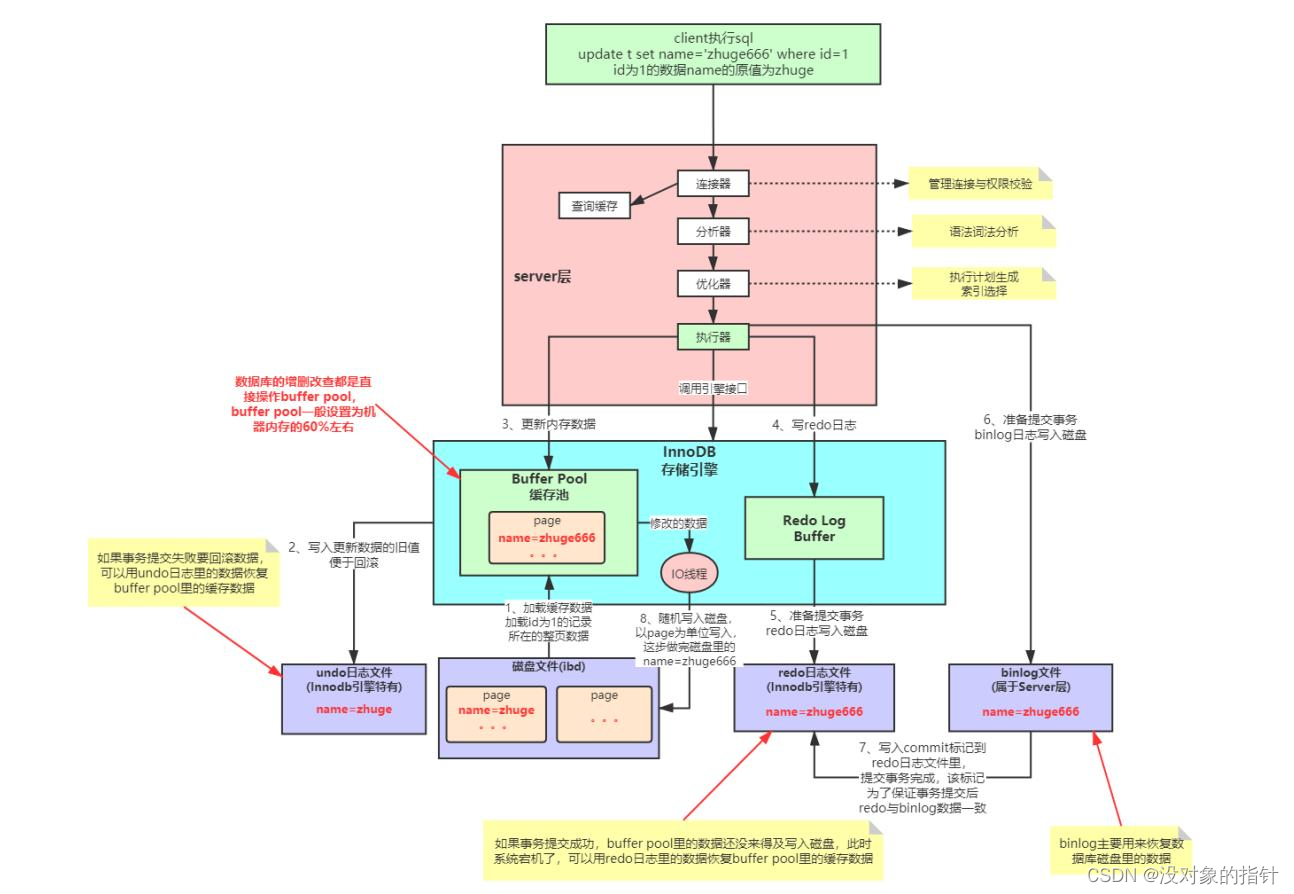
3.5 存储引擎更新数据
- InnoDB 存储引擎有一个缓冲池(Buffer Pool),查询时缓冲池里有数据就不去读取磁盘,没有就会把数据直接从磁盘里加载到缓冲池(Buffer Pool),同时加独占锁。
- 写入数据的旧值(原有的值)到 undo_log,实现事务的原子性,提供回滚操作。
- 更新 Buffer Pool 中的缓存数据为新数据,此时这个新值为脏数据,因为磁盘为旧值。
- 为了防止 MySQL 服务器宕机,Buffer Pool 内存中的数据丢失,把 Buffer Pool 更新新值的操作写入 Redo log Buffer,这时的 redo_log 还仅仅停留在内存缓冲里。
如果还没提交事务,如果 MySQL 宕机,必然会导致 Buffer Pool 中的数据丢失,同时写入 Redo Log Buffer 中的redo_log 也会丢失。
而此时丢失的数据其实无关紧要,因为事务没有提交,则代表此次更新操作没有成功,MySQL 宕机导致内存里的数据丢失,但磁盘上的数据还是原来的值,重启 MySQL 后,数据并没有改变。
- 如果想要提交一个事务,此时就会根据一定的策略把 redo_log 从 redo log buffer 里刷入到磁盘,这个策略是根据 innodb_flush_log_at_trx_commit 来配置的:
(1)值为0:提交事务时,不会把 redo log buffer 里的数据刷入磁盘,MySQL 宕机,内存中的数据和 redo_log 都会丢失。
(2)值为1:提交事务时,一定会把 redo log buffer 从内存刷入到磁盘,MySQL 宕机,可以通过 redo_log 进行数据恢复。
(3)值为2:提交事务时,把 redo_log 写入磁盘文件对应的 os cache 缓存里,每隔1秒后才会把 os cache 里的数据写入到磁盘文件里。MySQL 宕机,会丢失 1s 内的更新数据。