我是码哥,拥抱硬核技术和对象,面向人民币编程。公众号设置「星标」,才能收到我的文章推送哦。
在移动互联网的业务场景中,数据量很大,系统需要保存这样的信息:一个 key 关联了一个数据集合,同时对这个数据集合做统计做一个报表给运营人员看。
比如。
- 统计一个
APP的日活、月活数。 - 统计一个页面的每天被多少个不同账户访问量(Unique Visitor,UV)。
- 统计用户每天搜索不同词条的个数。
- 统计注册 IP 数。
通常情况下,系统面临的用户数量以及访问量都是巨大的,比如百万、千万级别的用户数量,或者千万级别、甚至亿级别的访问信息,咋办呢?
❝Redis:“这些就是典型的基数统计应用场景,基数统计:统计一个集合中不重复元素,这被称为基数。”
1. 是什么
HyperLogLog 是一种概率数据结构,用于估计集合的基数。每个 HyperLogLog 最多只需要花费 12KB 内存,在标准误差 0.81%的前提下,就可以计算 2 的 64 次方个元素的基数。
HyperLogLog 的优点在于它所需的内存并不会因为集合的大小而改变,无论集合包含的元素有多少个,HyperLogLog 进行计算所需的内存总是固定的,并且是非常少的。
主要特点如下。
- 高效的内存使用:HyperLogLog 的内存消耗是固定的,与集合中的元素数量无关。这使得它特别适用于处理大规模数据集,因为它不需要存储每个不同的元素,只需要存储估计基数所需的信息。
- 概率估计:HyperLogLog 提供的结果是概率性的,而不是精确的基数计数。它通过哈希函数将输入元素映射到位图中的某些位置,并基于位图的统计信息来估计基数。由于这是一种概率性方法,因此可能存在一定的误差,但通常在实际应用中,这个误差是可接受的。
- 高速计算:HyperLogLog 可以在常量时间内计算估计的基数,无论集合的大小如何。这意味着它的性能非常好,不会受到集合大小的影响。
2. 修炼心法
基本原理
HyperLogLog 是一种概率数据结构,它使用概率算法来统计集合的近似基数。而它算法的最本源则是伯努利过程。
伯努利过程就是一个抛硬币实验的过程。抛一枚正常硬币,落地可能是正面,也可能是反面,二者的概率都是 1/2 。
伯努利过程就是一直抛硬币,直到落地时出现正面位置,并记录下抛掷次数k。
比如说,抛一次硬币就出现正面了,此时 k 为 1; 第一次抛硬币是反面,则继续抛,直到第三次才出现正面,此时 k 为 3。
对于 n 次伯努利过程,我们会得到 n 个出现正面的投掷次数值 k1, k2 ... kn, 其中这里的最大值是 k_max。
根据一顿数学推导,我们可以得出一个结论:2^{k_ max} 来作为 n 的估计值。
也就是说你可以根据最大投掷次数近似的推算出进行了几次伯努利过程。
所以 HyperLogLog 的基本思想是利用集合中数字的比特串第一个 1 出现位置的最大值来预估整体基数,但是这种预估方法存在较大误差,为了改善误差情况,HyperLogLog 中引入分桶平均的概念,计算 m 个桶的调和平均值。
Redis 内部使用字符串位图来存储 HyperLogLog 所有桶的计数值,一共分了 2^14 个桶,也就是 16384 个桶。每个桶中是一个 6 bit 的数组。
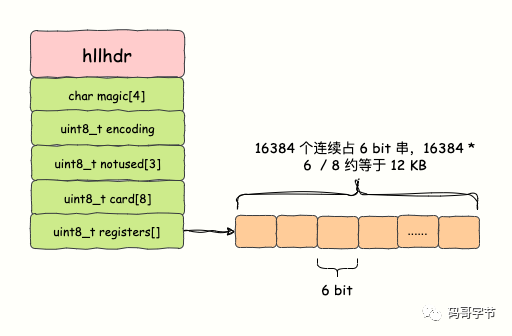
这段代码描述了 Redis HyperLogLog 数据结构的头部定义(hyperLogLog.c 中的 hllhdr 结构体)。以下是关于这个数据结构的各个字段的解释。
struct hllhdr { char magic[4]; uint8_t encoding; uint8_t notused[3]; uint8_t card[8]; uint8_t registers[]; };
- magic[4]:这个字段是一个 4 字节的字符数组,用来表示数据结构的标识符。在 HyperLogLog 中,它的值始终为"HYLL",用来标识这是一个 HyperLogLog 数据结构。
- encoding:这是一个 1 字节的字段,用来表示 HyperLogLog 的编码方式。它可以取两个值之一:
HLL_DENSE:表示使用稠密表示方式。HLL_SPARSE:表示使用稀疏表示方式。
notused[3]:这是一个 3 字节的字段,目前保留用于未来的扩展,要求这些字节的值必须为零。
card[8]:这是一个 8 字节的字段,用来存储缓存的基数(基数估计的值)。
egisters[]:这个字段是一个可变长度的字节数组,用来存储 HyperLogLog 的数据。
 4-45
4-45
图 2-45
Redis 对 HyperLogLog 的存储进行了优化,在计数比较小的时候,存储空间采用系数矩阵,占用空间很小。
只有在计数很大,稀疏矩阵占用的空间超过了阈值才会转变成稠密矩阵,占用 12KB 空间。
3. 出招实战:网页访问量统计
在移动互联网的业务场景中,数据量很大,系统需要保存这样的信息:一个 key 关联了一个数据集合,同时对这个数据集合做统计做一个报表给运营人员看。
比如。
- 统计一个
APP的日活、月活数。 - 统计一个页面的每天被多少个不同账户访问量(Unique Visitor,UV)。
- 统计用户每天搜索不同词条的个数。
- 统计注册 IP 数。
通常情况下,系统面临的用户数量以及访问量都是巨大的,比如百万、千万级别的用户数量,或者千万级别、甚至亿级别的访问信息,咋办呢?
使用 Set 实现
一个用户一天内多次访问一个网站只能算作一次,所以很容易就想到通过 Redis 的 Set 集合来实现。
比如微信昵称叫 “Chaya” 的小姐姐访问【爱一个人总是要掉眼泪的风险】这篇文章时,我把这个微信昵称 “Chaya” 存到 Set 集合中。
SADD 爱一个人总是要掉眼泪的风险:uv 码哥 Chaya 赵小因 Chaya (integer) 3
“Chaya” 多次访问这篇文章, Set 的去重特性保证集合中只有一个记录。接着,通过 SCARD 命令,统计页面 UV。指令返回这个集合的元素个数(也就是微信昵称个数)。
SCARD 爱一个人总是要掉眼泪的风险:uv (integer) 3
使用 HyperLogLog 实现
❝Chaya:“Set 集合虽好,如果文章非常火爆达到千万级别,一个 Set 集合就保存了千万个用户的 ID,页面多了消耗的内存也太大了。”
不要怕,只要思想不滑坡,办法总比困难多。这些就是典型的基数统计应用场景,基数统计:统计一个集合中不重复元素的个数。
HyperLogLog 的优点在于它所需的内存并不会因为集合的大小而改变,无论集合包含的元素有多少个,HyperLogLog 进行计算所需的内存总是固定的,并且是非常少的。
每个 HyperLogLog 最多只需要花费 12KB 内存,在标准误差 0.81%的前提下,就可以计算 2 的 64 次方个元素的基数。
HyperLogLog 使用太简单了。PFADD、PFCOUNT、PFMERGE三个指令打天下。
PFADD
每访问一次页面,调用 PFADD 指令 将这个用户 ID 添加到 HyperLogLog 中。如下 一共有三个用户访问了这页面,其中 Chaya 访问了两次,但只算一次。
PFADD 爱一个人总是要掉眼泪的风险:uv 码哥 Chaya 赵小因 Chaya
如果执行命令后 HyperLogLog 估计的近似基数发生变化,PFADD则返回 1,否则返回 0。如果指定的键不存在,该命令会自动创建一个空的 HyperLogLog 结构。
pfadd 命令并不会一次性分配 12k 内存,而是随着基数的增加而逐渐增加内存分配;
PFCOUNT
接下来,通过 PFCOUNT 指令获取文章【爱一个人总是要掉眼泪的风险】的 UV 值,可以看到返回值是 3 ,符合预期。
> PFCOUNT 爱一个人总是要掉眼泪的风险:uv 3
PFMERGE 合并统计
❝Chaya:“还有一个变态需求,对文章进行标签分类,运营说要把都是情感文章标签的几个页面数据合并统计。”
其中页面的 UV 访问量也需要合并,那这个时候 PFMERGE 就可以派上用场了,也就是同样的用户访问这两个页面则只算做一次。
如下指令,把爱一个人总是要掉眼泪的风险:uv和爱情是幸福和不委屈:uv 两个 HyperLogLog 集合数据合并到情感分类文章:uv这个集合中。
PFADD 爱情是幸福和不委屈:uv Chaya 赵小因 幸运草 # 合并两个页面 UV PFMERGE 情感分类文章:uv 爱一个人总是要掉眼泪的风险:uv 爱情是幸福和不委屈:uv
接着,执行 PFCOUNT 情感分类文章:uv 统计合并后的数据。
> PFCOUNT 情感分类文章:uv 4
将多个 HyperLogLog 合并(merge)为一个 HyperLogLog , 合并后的 HyperLogLog 的基数接近于所有输入 HyperLogLog 的可见集合(observed set)的并集。
4. Redisson 实战
开门见山,Spring Boot 与 Redisson 集成详见前面篇章,主要有四个方法。
add、addAll,阅读文章调用该方法将数据存入 HyperLogLog 中。count,统计基数。merge,合并多个 HyperLogLog 为一个。
@Service public class HyperLogLogService { @Autowired private RedissonClient redissonClient; /** * 将数据添加到 HyperLogLog * * @param logName * @param item * @param <T> */ public <T> void add(String logName, T item) { RHyperLogLog<T> hyperLogLog = redissonClient.getHyperLogLog(logName); hyperLogLog.add(item); } /** * 将集合数据添加到 HyperLogLog * @param logName * @param items * @param <T> */ public <T> void addAll(String logName, List<T> items) { RHyperLogLog<T> hyperLogLog = redissonClient.getHyperLogLog(logName); hyperLogLog.addAll(items); } /** * 将 otherLogNames 的 log 合并到 logName * * @param logName 当前 log * @param otherLogNames 需要合并到当前 log 的其他 logs * @param <T> */ public <T> void merge(String logName, String... otherLogNames) { RHyperLogLog<T> hyperLogLog = redissonClient.getHyperLogLog(logName); hyperLogLog.mergeWith(otherLogNames); } /** * 统计基数 * * @param logName 需要统计的 logName * @param <T> * @return */ public <T> long count(String logName) { RHyperLogLog<T> hyperLogLog = redissonClient.getHyperLogLog(logName); return hyperLogLog.count(); } }