需要源码请点赞关注收藏后评论区留言私信~~~
支持向量机(Support Vetor Machine,SVM)由Vapnik等人于1995年首先提出,在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并推广到人脸识别、行人检测和文本分类等其他机器学习问题中
SVM建立在统计学习理论的VC维理论和结构风险最小原理基础上,根据有限的样本信息在模型的复杂性和学习能力之间寻求最佳平衡,以求获得最好的推广能力。SVM可以用于数值预测和分类
算法原理
支持向量机(Support Vetor Machine,SVM)是一种对线性和非线性数据进行分类的方法。SVM 使用一种非线性映射,把原训练数据映射到较高的维上,在新的维上,搜索最佳分离超平面

由简至繁SVM可分类为三类:线性可分(linear SVM in linearly separable case)的线性SVM、线性不可分的线性SVM、非线性(nonlinear)SVM
SVM可分类为三类:线性可分的线性SVM、线性不可分的线性SVM、非线性SVM。如果训练数据线性可分,则通过硬间隔最大化学习一个线性分类器即线性可分支持向量机,也称为硬间隔支持向量机;如果训练数据近似线性可分,则通过软间隔最大化学习得到一个线性分类器即线性支持向量机,也称为软间隔支持向量机;对于数据非线性可分的情况,通过扩展线性SVM的方法,得到非线性的SVM,即采用非线性映射把输入数据变换到较高维空间,在新的空间搜索分离超平面
1. 数据线性可分的情况
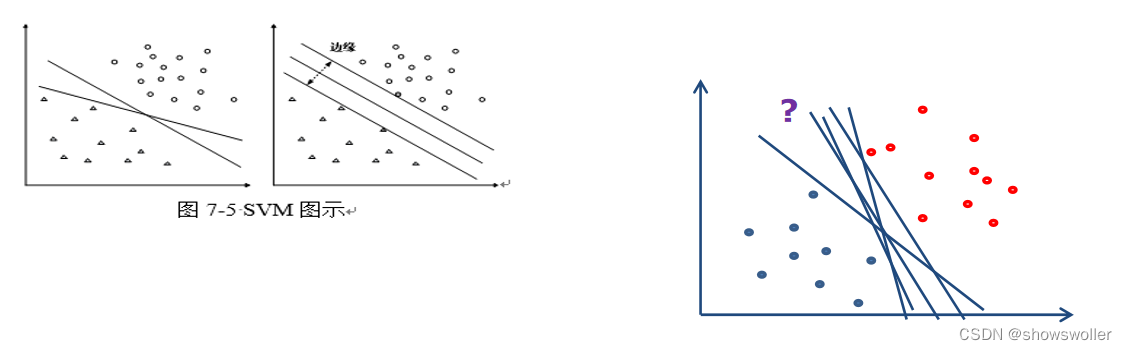
SVM的主要目标是找到最佳超平面,以便在不同类的数据点之间进行正确分类。超平面的维度等于输入特征的数量减去1。图7-5显示了分类的最佳超平面和支持向量(实心的数据样本)

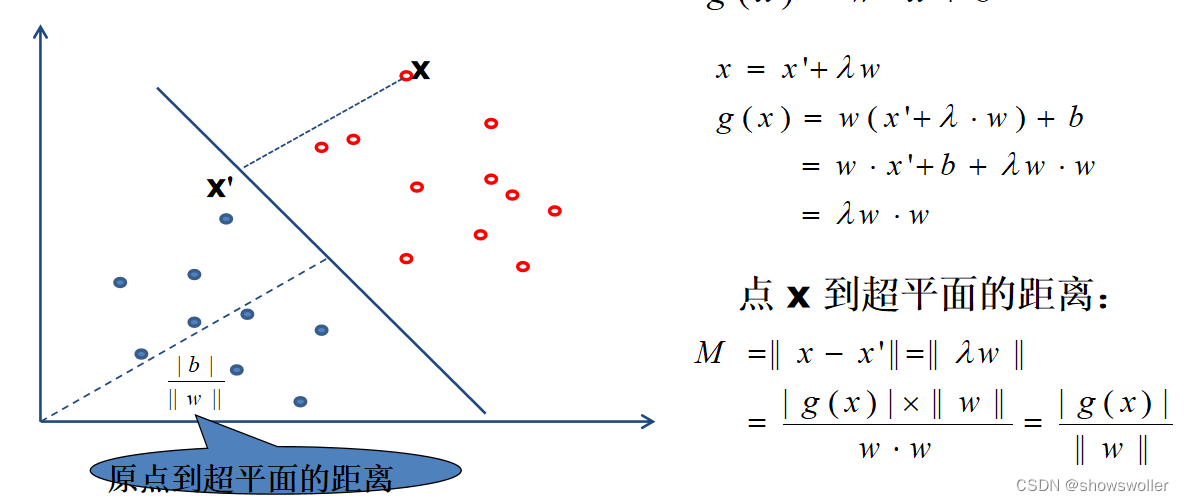
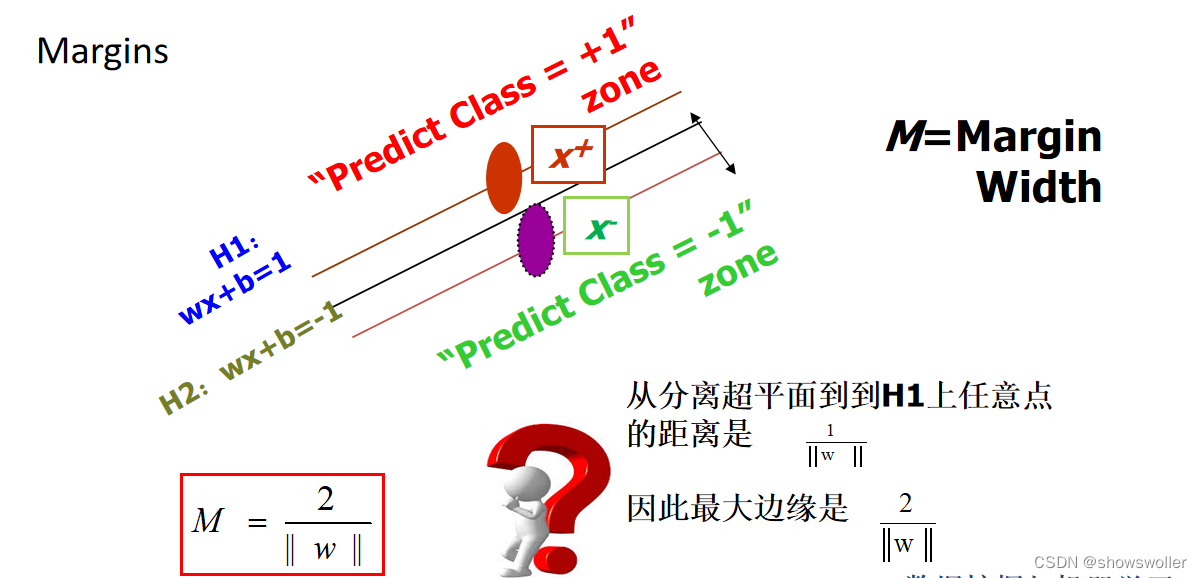
向量到超平面距离公式如下



2.数据非线性可分的情况
在某些情况下,训练数据甚至连近似的线性划分也找不到,线性超平面无法有效划分正类与负类,而是需要超曲面等非线性划分。然而,非线性的优化问题很难求解。通常的做法是将输入向量从输入的空间投射到另一个空间,如图7-6所示。在这个特征空间中,投射后的特征向量线性可分或者近似线性可分,然后通过线性支持向量机的方法求解
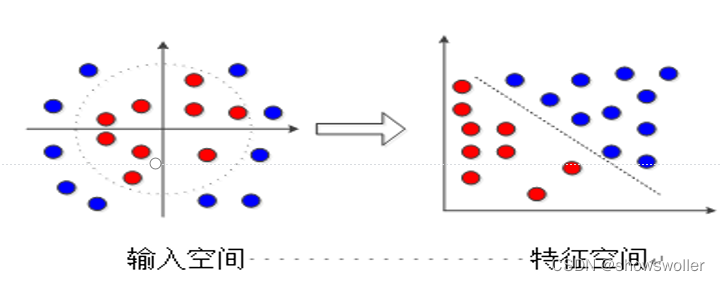
然而这样做也带来一个新的问题,即使得投射后的特征向量(近似)线性可分的特征空间维度往往比原输入空间的维度高很多,甚至具有无限个维度。为了解决新特征空间维度高的问题,引入核方法(Kernal Method),在计算中不需要直接进行非线性变换,从而避免由计算高维度向量带来的问题
常用核函数如下图

支持向量机在高维空间中非常高效,即使在数据维度比样本数量大的情况下仍然有效,而且在决策函数中使用了训练集的自己,因此它也是高效利用内存的,但是如果特征数量比样本数量大得多,在选择核函数时就要避免过拟合
SVM算法实战
在sklearn中SVM的算法库分为两类,一类是分类的算法库,包括SVC、NuSVC和LinearSVC 3个类。另一类是回归算法库,包括SVR、NuSVR和LinearSVR 3个类。相关的类都包括在sklearn.svm模块之中
下面利用SV对Iris数据集进行分类
输出结果如下

部分代码如下
import numpy as np from sklearn import svm from sklearn import datasets from sklearn import metrics from sklearn import model_selection import matplotlib.pyplot as plt iris = datasets.load_iris() x, y = iris.data,iris.target x_train, x_test, y_train, y_test = model_selection.train_test_split(x, y, random_state = 1, test_size = 0.2) classifier=svm.SVC(kernel='linear',gamma=0.1,decision_function_shape='ovo',C=0.1) classifier.fit(x_train, y_train.ravel()) print("SVM-输出训练集的准确率为:", classifier.score(x_train, y_train)) print("SVM-输出测ification_report(y_test,y_hat) print(classreport)
创作不易 觉得有帮助请点赞关注收藏~~~

