CreatePartition API执行流程源码解析
milvus版本:v2.3.2
syncNewCreatedPartitionStep_milvus源码解析
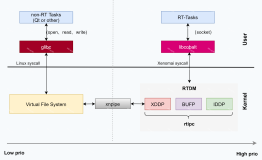
整体架构:
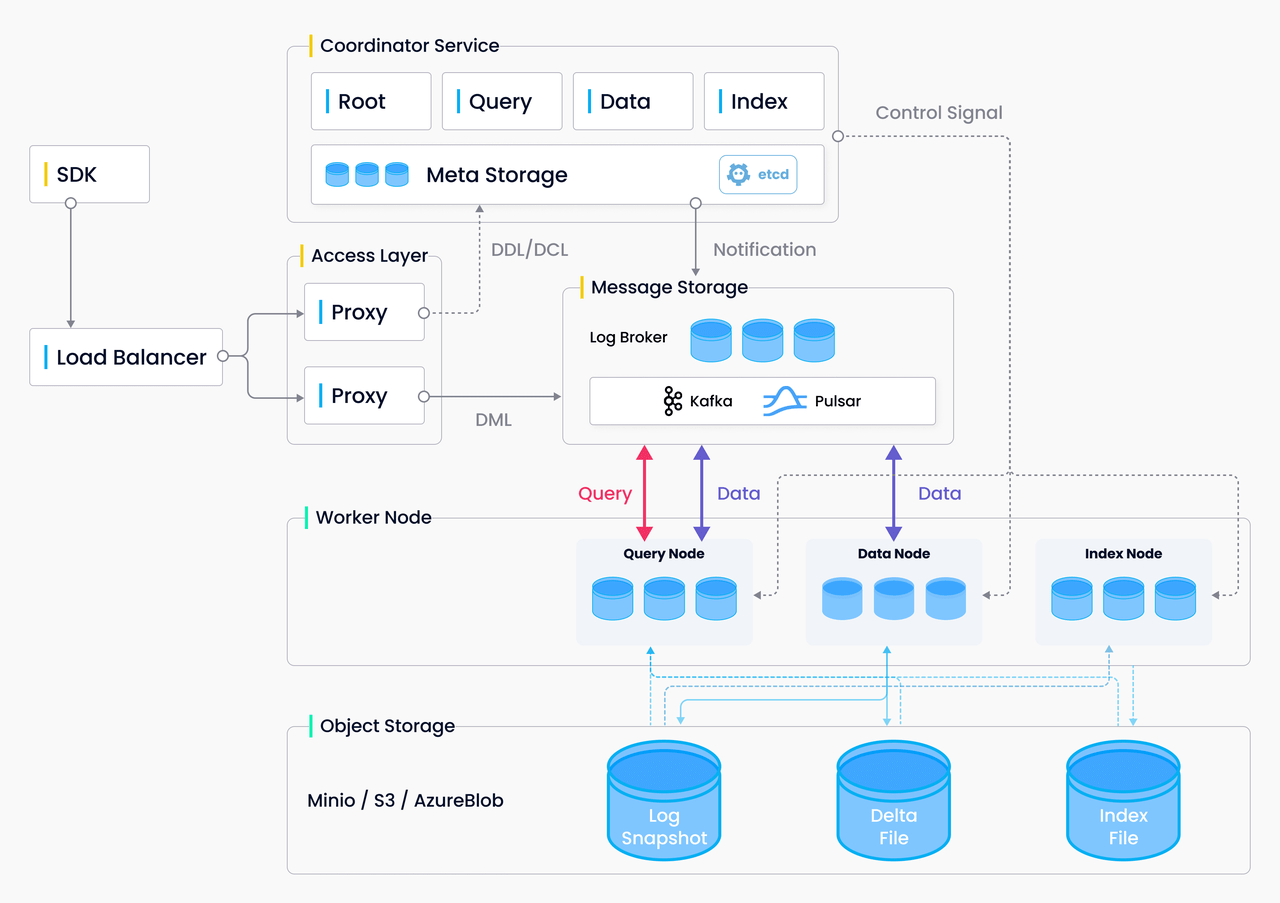
CreatePartition 的数据流向:
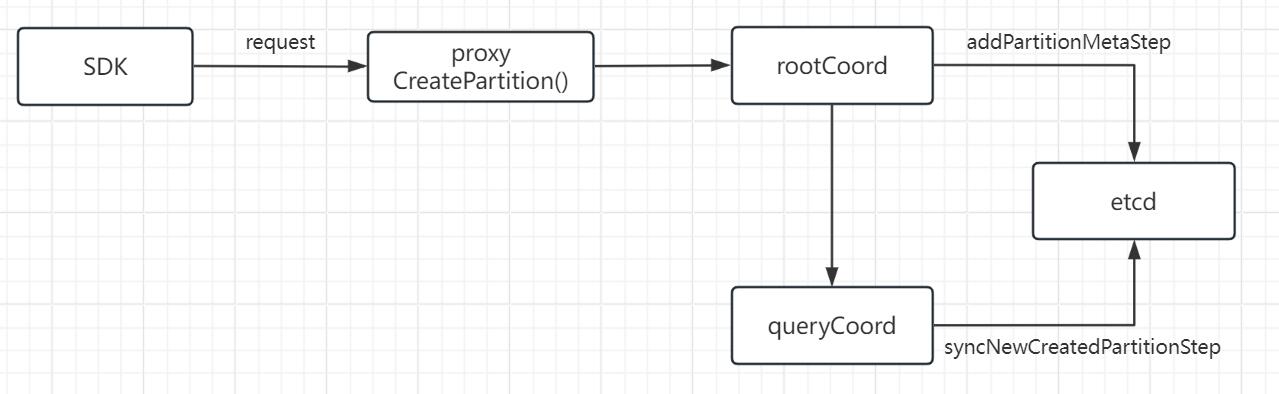
1.客户端sdk发出CreatePartition API请求。
from pymilvus import (
connections,
Collection, Partition,
)
print("start connecting to Milvus")
connections.connect(db_name="default", host="192.168.230.71", port="19530")
hello_milvus = Collection("hello_milvus")
print("create a partition")
partition = Partition(hello_milvus, name="part01", description="this is a partition")
客户端SDK向proxy发送一个CreatePartition API请求,在hello_milvus这个collection下创建一个名为part01的partition。
2.客户端接受API请求,将request封装为createPartitionTask,并压入ddQueue队列。
代码路径:internal\proxy\impl.go
// CreatePartition create a partition in specific collection.
func (node *Proxy) CreatePartition(ctx context.Context, request *milvuspb.CreatePartitionRequest) (*commonpb.Status, error) {
......
// request封装为task
cpt := &createPartitionTask{
ctx: ctx,
Condition: NewTaskCondition(ctx),
CreatePartitionRequest: request,
rootCoord: node.rootCoord,
result: nil,
}
......
// 将task压入ddQueue队列
if err := node.sched.ddQueue.Enqueue(cpt); err != nil {
......
}
......
// 等待cct执行完
if err := cpt.WaitToFinish(); err != nil {
......
}
......
}
3.执行createPartitionTask的3个方法PreExecute、Execute、PostExecute。
PreExecute()一般为参数校验等工作。
Execute()一般为真正执行逻辑。
代码路径:internal\proxy\task.go
func (t *createPartitionTask) Execute(ctx context.Context) (err error) {
t.result, err = t.rootCoord.CreatePartition(ctx, t.CreatePartitionRequest)
if err != nil {
return err
}
if t.result.ErrorCode != commonpb.ErrorCode_Success {
return errors.New(t.result.Reason)
}
return err
}
从代码可以看出调用了rootCoord的CreatePartition接口。
4.进入rootCoord的CreatePartition接口。
代码路径:internal\rootcoord\root_coord.go
继续将请求封装为rootcoord里的createDatabaseTask
// CreatePartition create partition
func (c *Core) CreatePartition(ctx context.Context, in *milvuspb.CreatePartitionRequest) (*commonpb.Status, error) {
......
// 封装为createPartitionTask
t := &createPartitionTask{
baseTask: newBaseTask(ctx, c),
Req: in,
}
// 加入调度
if err := c.scheduler.AddTask(t); err != nil {
......
}
// 等待task完成
if err := t.WaitToFinish(); err != nil {
......
}
......
}
5.执行createPartitionTask的Prepare、Execute、NotifyDone方法。
Execute()为核心方法。
代码路径:internal\rootcoord\create_partition_task.go
func (t *createPartitionTask) Execute(ctx context.Context) error {
for _, partition := range t.collMeta.Partitions {
if partition.PartitionName == t.Req.GetPartitionName() {
log.Warn("add duplicate partition", zap.String("collection", t.Req.GetCollectionName()), zap.String("partition", t.Req.GetPartitionName()), zap.Uint64("ts", t.GetTs()))
return nil
}
}
cfgMaxPartitionNum := Params.RootCoordCfg.MaxPartitionNum.GetAsInt()
if len(t.collMeta.Partitions) >= cfgMaxPartitionNum {
return fmt.Errorf("partition number (%d) exceeds max configuration (%d), collection: %s",
len(t.collMeta.Partitions), cfgMaxPartitionNum, t.collMeta.Name)
}
// 分配partID
partID, err := t.core.idAllocator.AllocOne()
if err != nil {
return err
}
// 构建partition结构体
// 包含partID,partName,collectID等
partition := &model.Partition{
PartitionID: partID,
PartitionName: t.Req.GetPartitionName(),
PartitionCreatedTimestamp: t.GetTs(),
Extra: nil,
CollectionID: t.collMeta.CollectionID,
State: pb.PartitionState_PartitionCreating,
}
undoTask := newBaseUndoTask(t.core.stepExecutor)
// 分为多个step执行,每一个undoTask由todoStep和undoStep构成
// 执行todoStep,报错则执行undoStep
undoTask.AddStep(&expireCacheStep{
baseStep: baseStep{
core: t.core},
dbName: t.Req.GetDbName(),
collectionNames: []string{
t.collMeta.Name},
collectionID: t.collMeta.CollectionID,
ts: t.GetTs(),
}, &nullStep{
})
// 添加partition元数据
undoTask.AddStep(&addPartitionMetaStep{
baseStep: baseStep{
core: t.core},
partition: partition,
}, &removePartitionMetaStep{
baseStep: baseStep{
core: t.core},
dbID: t.collMeta.DBID,
collectionID: partition.CollectionID,
partitionID: partition.PartitionID,
ts: t.GetTs(),
})
undoTask.AddStep(&nullStep{
}, &releasePartitionsStep{
baseStep: baseStep{
core: t.core},
collectionID: t.collMeta.CollectionID,
partitionIDs: []int64{
partID},
})
// 同样也是添加partition元数据,侧重于load后的partition
undoTask.AddStep(&syncNewCreatedPartitionStep{
baseStep: baseStep{
core: t.core},
collectionID: t.collMeta.CollectionID,
partitionID: partID,
}, &nullStep{
})
undoTask.AddStep(&changePartitionStateStep{
baseStep: baseStep{
core: t.core},
collectionID: t.collMeta.CollectionID,
partitionID: partID,
state: pb.PartitionState_PartitionCreated,
ts: t.GetTs(),
}, &nullStep{
})
return undoTask.Execute(ctx)
}
创建partition涉及多个步骤,可以看出这里依次分为expireCacheStep、addPartitionMetaStep、syncNewCreatedPartitionStep、changePartitionStateStep这几个步骤,关于etcd元数据的操作,这里重点关注syncNewCreatedPartitionStep。
6.进入syncNewCreatedPartitionStep,执行其Execute()方法。
代码路径:internal\rootcoord\step.go
func (s *syncNewCreatedPartitionStep) Execute(ctx context.Context) ([]nestedStep, error) {
err := s.core.broker.SyncNewCreatedPartition(ctx, s.collectionID, s.partitionID)
return nil, err
}
在这里重点研究s.core.broker.SyncNewCreatedPartition()这个方法做了什么事情。
调用栈如下(分2种情况):
s.core.meta.AddPartition()
|--AddPartition()(internal\rootcoord\meta_table.go)
|--mt.catalog.CreatePartition()(同上)
|--CreatePartition()(internal\metastore\kv\rootcoord\kv_catalog.go)
|--kc.Snapshot.Save()
collection未load:
s.core.broker.SyncNewCreatedPartition()
|--SyncNewCreatedPartition()(internal\rootcoord\broker.go)
|--b.s.queryCoord.SyncNewCreatedPartition(同上)
|--SyncNewCreatedPartition()(internal\querycoordv2\services.go)
|--job.NewSyncNewCreatedPartitionJob()(同上)
|--Execute()(internal\querycoordv2\job\job_sync.go)
这种情况下,返回nil,不操作etcd。
collection已load:
s.core.broker.SyncNewCreatedPartition()
|--SyncNewCreatedPartition()(internal\rootcoord\broker.go)
|--b.s.queryCoord.SyncNewCreatedPartition(同上)
|--SyncNewCreatedPartition()(internal\querycoordv2\services.go)
|--job.NewSyncNewCreatedPartitionJob()(同上)
|--Execute()(internal\querycoordv2\job\job_sync.go)
|--job.meta.CollectionManager.PutPartition()(同上)
|--m.putPartition()(internal\querycoordv2\meta\collection_manager.go)
|--m.catalog.SavePartition(同上)
|--SavePartition()(internal\metastore\kv\querycoord\kv_catalog.go)
|--s.cli.Save()(同上)
这种情况下,会操作etcd。
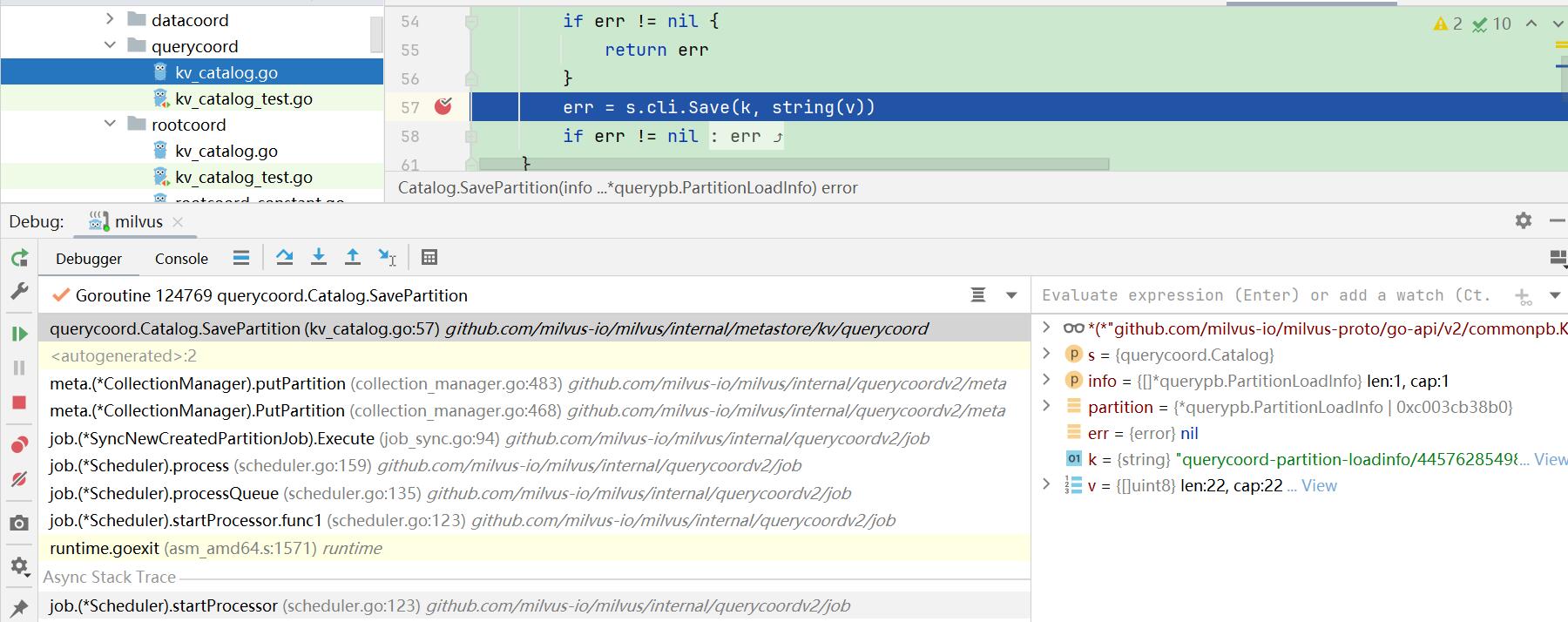
在etcd产生partition相关的key:
==querycoord-partition-loadinfo/445762854989594797/445788143864261250==
value的值的结构为querypb.PartitionLoadInfo,然后进行protobuf序列化后存入etcd。
因此etcd存储的是二进制数据。
type PartitionLoadInfo struct {
CollectionID int64
PartitionID int64
ReplicaNumber int32
Status LoadStatus
FieldIndexID map[int64]int64
RecoverTimes int32
XXX_NoUnkeyedLiteral struct{
}
XXX_unrecognized []byte
XXX_sizecache int32
}
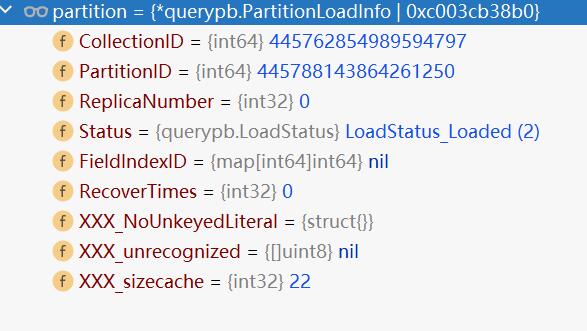
可以看出partitionLoadInfo由collectionID、partitionID等组成。
func (s Catalog) SavePartition(info ...*querypb.PartitionLoadInfo) error {
for _, partition := range info {
// 构建key规则
// querycoord-partition-loadinfo/collectionID/partitionID
k := EncodePartitionLoadInfoKey(partition.GetCollectionID(), partition.GetPartitionID())
// 序列化
v, err := proto.Marshal(partition)
if err != nil {
return err
}
// 写入etcd
err = s.cli.Save(k, string(v))
if err != nil {
return err
}
}
return nil
}
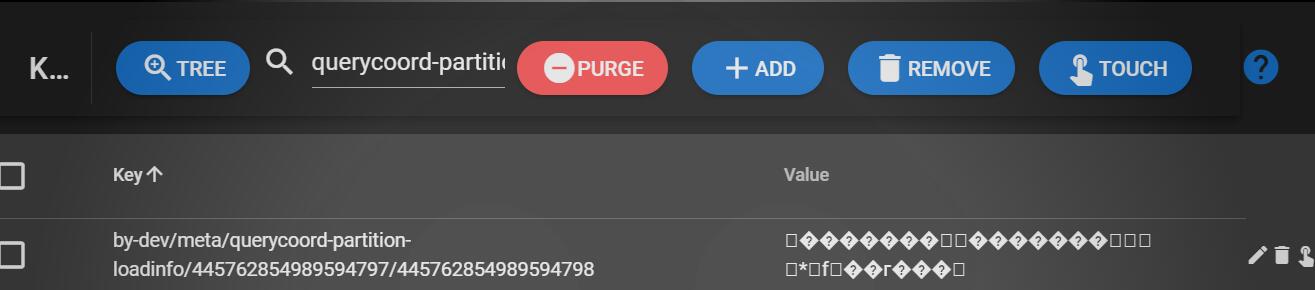
跟踪EncodePartitionLoadInfoKey()函数,不难得出key的规则。整理如下:
key规则:
- 前缀/querycoord-partition-loadinfo/{collectionID}/{partitionID}
已load的partition会产生这种类型的key,即如果有这种类型的key,就可以判断哪些partition已经load。
使用etcd-manager查看etcd:
总结:
1.CreatePartition由proxy传递给协调器rootCoord,rootCoord调用queryCoord再操作etcd。
2.CreatePartition最终会在etcd上写入一种类型的key
- 前缀/querycoord-partition-loadinfo/{collectionID}/{partitionID}