

PostgreSQL从小白到专家,是从入门逐渐能力提升的一个系列教程,内容包括对PG基础的认知、包括安装使用、包括角色权限、包括维护管理、、等内容,希望对热爱PG、学习PG的同学们有帮助,欢迎持续关注CUUG PG技术大讲堂。
第32讲:数据库参数调整
第32讲:11月04日(周六)19:30-20:30,往期文档及视频,联系CUUG
内容 : 数据库常用参数调整:shared_buffers、wal_buffer、effective_cache_size、等等
shared_buffers
· PostgreSQL使用自己的缓冲区,也使用操作系统缓冲IO。这意味着数据存储在内存中两次,首先是PostgreSQL缓冲区,然后是操作系统缓冲区。
· 与其他数据库不同,PostgreSQL不提供直接IO。这称为双缓冲。
· PostgreSQL缓冲区称为shared_buffers,它是大多数操作系统最有效的可调参数。
· PostgreSQL将用shared_buffers参数缓存如下数据:
表数据
索引
执行计划
· 初始化参考值:物理内存1/4
wal_buffer
· PostgreSQL将其WAL(预写日志)记录写入缓冲区,然后将这些缓冲区刷新到磁盘。
· 缓冲区的默认大小,由wal_buffers定义,但如果您有大量并发连接,则较高的值可以提供更好的性能。
· 该缓冲区的作用是临时存放redo log,所以分配太大不会对性能有好处,一般10MB左右。
effective_cache_size
· 该effective_cache_size提供了可以用于磁盘缓存存储器的估计。
· 它只是一个指导原则,而不是确切分配的内存或缓存大小。
· 它不分配实际内存,而是告诉优化器内核中可用的缓存量。
· 如果将此值设置得太低,查询计划程序可以决定不使用某些索引,即使它们有用。
· 因此,设置较大的值总是有益的。
· 建议使用默认值。
work_mem
· 指定在写入磁盘上的临时文件之前,ORDER BY,DISTINCT,JOIN和哈希表的内部操作将使用的内存量。
· 此配置用于复杂排序,如果必须进行复杂排序,则增加work_mem的值以获得良好结果。内存中的排序比溢出到磁盘的排序快得多。
· 设置非常高的值可能会导致部署环境出现内存瓶颈,因为此参数是按用户排序操作。
· 如果您有许多用户尝试执行排序操作,系统将为所有用户分配 work_mem * 总排序操作 。
· 全局设置此参数可能会导致内存使用率过高,强烈建议在会话级别修改它。
· postgres=# SET work_mem=“2MB”; (会话级配置)
maintenance_work_mem
· maintenance_work_mem是用于维护任务的内存设置。默认值为64MB。本参数可以针对每个session设置。
· 设置较大的值有助于执行VACUUM,RESTORE,CREATE INDEX,ADD FOREIGN KEY和ALTER TABLE等任务。
· 由于会话中只能同时执行其中一个操作,并且通常没有多个同时运行,因此它可能比work_mem大。
· 较大的配置可以提高VACUUM和数据库还原的性能。
· 执行autovacuum时,或者配置autovacuum_work_mem参数来单独管理它。
FSYNC
· 如果启用了fsync,PostgreSQL将尝试确保将更新写入物理磁盘,会延长响应时间对性能有一定影响。
· 这可确保在操作系统或硬件崩溃后可以将数据库群集恢复到一致状态。
· 禁用fsync通常可以提高性能,但在发生电源故障或系统崩溃时可能会导致数据丢失。
· 从外部数据重新创建整个数据库,则建议停用fsync。
synchronous_commit
· 指定在命令向客户端返回“成功”指示之前,事务提交是否将等待WAL记录写入磁盘。这是性能和可靠性之间的权衡。默认设置为“on”。
· 可能的值包括:“on”,“remote_apply”,“remote_write”,“local”和“off”。
· 与fsync不同,禁用此参数不会产生任何数据库不一致的风险:操作系统或数据库崩溃可能导致丢失一些最近发生的可能提交的事务,但数据库的状态将与这些事务完全相同,未提交的将被抛弃。
· 当性能比事务持久性更重要时,停用synchronous_commit可能是一个有用的替代方法。
· 这意味着成功状态与保证写入磁盘之间会存在时间差。在服务器崩溃的情况下,即使客户端在提交时收到成功消息,数据也可能丢失。在这种情况下,事务提交非常快,因为它不会等待刷新WAL文件,但可靠性受到损害。
checkpoint_timeout
· checkpoint_timeout:检查点启动的时间间隔
· 将此设置得太低会减少崩溃恢复时间,因为更多数据会写入磁盘,但由于每个检查点都会占用宝贵的系统资源,因此也会损害性能。高频率的检查点可能会影响性能。实例崩溃的机率与长时间运行的性能相比,实例崩溃所占的比重要小的多,该值设置为实例崩溃后客户允许恢复的时间。
· 检查点进程将数据刷新到数据文件中。
· 发生CHECKPOINT时完成此活动。这是一项昂贵的操作,可能会导致大量的IO。 整个过程涉及昂贵的磁盘读/写操作。
· checkpoint_completion_target衡量检查点完成的时间长度。
checkpoint_completion_target
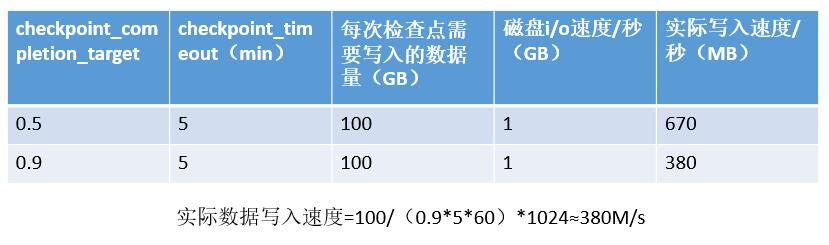
· 数据库中一个至关重要的参数,主要与参数checkpoint_timeout(checkpoint_timeout)配合使用,值越小意味着检查点要越快完成,要求写得要快。
· 控制每次检查点发生时i/o的吞吐量,值越高,则i/o占用的资源越少,数据库性能越好;值越低,则i/o占用的资源越多,影响数据库性能,但是提高检查点完成速度。
其它常见参数
· max_connections
确定与数据库同时连接的最大数量。因为每个客户端都可以配置内存资源,因此,客户机的最大数量表明使用的内存的最大数量。
· superuser_reserved_connections
在达到max_connection限制的情况下,这些连接保留给超级用户。
· temp_buffers
设置每个会话使用的最大临时缓冲区数。 这些是仅用于访问临时表的本地会话缓冲区。 会话将根据需要分配临时缓冲区,直到temp_buffers给出的限制。
· max_wal_size
允许WAL日志所在目录使用的最大尺寸,默认为1GB。
该参数与wal_segment_size相关,默认是16MB,允许存放64个wal段文件。
