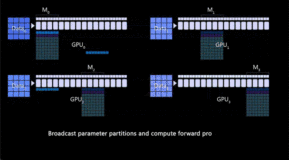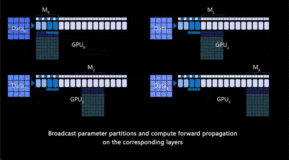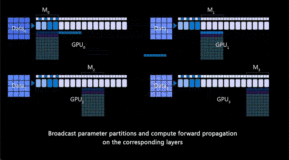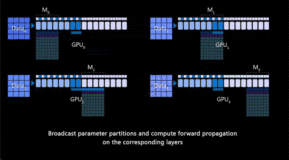
chatGPT是一种基于GPT模型的对话生成模型,它能够根据输入的对话历史和上下文生成自然流畅的回复。chatGPT的训练主要分为两个阶段:预训练和微调。
1. 预训练
chatGPT的预训练阶段与GPT模型的预训练类似,主要是在大规模无监督数据上进行语言模型的训练。在预训练阶段,模型会通过多层的Transformer结构对输入的文本进行编码,学习到文本中的语言知识和上下文关联性。预训练的目的是让模型具有强大的语言理解和生成能力,从而能够在特定任务上进行微调。
具体来说,chatGPT的预训练过程包括以下几个步骤:
(1)数据收集和清洗。chatGPT需要大规模的对话数据来进行预训练,因此需要从各种渠道收集对话数据,并对数据进行清洗和预处理。清洗的目的是去除噪声和无效数据,保证数据的质量和可靠性。
(2)数据预处理。对于每个对话,需要将其转换成一系列的文本序列,并添加特殊的标记来表示对话开始和结束的位置。这些序列会作为模型的输入进行训练。
(3)模型训练。chatGPT的预训练使用的是基于自回归的语言模型,即模型在生成每个单词时都会考虑前面生成的单词。具体来说,模型会根据前面生成的单词和上下文信息,预测下一个单词的概率分布,然后根据概率分布随机生成下一个单词。这个过程会一直进行下去,直到生成完整的文本序列。
在预训练过程中,模型会根据生成的文本序列和真实的文本序列之间的差异来更新模型参数,使得模型能够更好地预测下一个单词。预训练的目的是让模型学习到文本中的语言知识和上下文关联性,从而能够在特定任务上进行微调。
2. 微调
在预训练完成后,chatGPT需要在特定任务上进行微调,以便将其应用到实际场景中。微调的目的是让模型在特定任务上学习到更具体的知识和技能,从而提高模型的性能和效果。
对于对话生成任务,微调的过程包括以下几个步骤:
(1)数据准备。需要将对话数据分成训练集、验证集和测试集,并进行数据清洗和预处理。同时,需要将对话数据转换成模型能够处理的格式,即将每个对话转换成一系列的文本序列,并添加特殊的标记来表示对话开始和结束的位置。
(2)模型微调。在微调阶段,chatGPT使用的是基于有监督学习的方法。具体来说,模型会根据输入的对话历史和上下文信息,生成回复文本序列,并根据真实的回复文本序列之间的差异来更新模型参数。微调的目的是让模型在特定任务上学习到更具体的知识和技能,从而提高模型的性能和效果。
(3)评估和调优。在微调完成后,需要对模型进行评估和调优,以确保模型的性能和效果达到要求。评估的方法包括计算模型在测试集上的准确率、召回率、F1值等指标,同时需要对模型进行调优,包括调整模型的超参数、优化算法等。
总之,chatGPT的训练主要包括预训练和微调两个阶段。预训练的目的是让模型学习到文本中的语言知识和上下文关联性,微调的目的是让模型在特定任务上学习到更具体的知识和技能,从而提高模型的性能和效果。