1、初识数据库
1.1、什么是数据库
数据库:DB(DataBase)
概念:数据仓库,软件,安装在操作系统之上
作用:存储数据,管理数据
1.2、数据库分类
1.2.1、关系型数据库:SQL(Structured Query Language)
MySQL、Oracle、Sql Server、DB2、SQLlite
通过表和表之间,行和列之间的关系进行数据的存储
通过外键关联来建立表与表之间的关系
1.2.2、非关系型数据库:NoSQL(Not Only SQL)
Redis、MongoDB
指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定
1.2.3 时序数据库
influxDB , IOTDB
2、数据定义语言(DDL)
2.1、操作数据库
2.1.1、创建数据库
CREATE DATABASE [IF NOT EXISTS] 数据库名;
CREATE DATABASE [IF NOT EXISTS] `launch_mysql` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
1
2.1.2、删除数据库
DROP DATABASE [if EXISTS] 数据库名;
2.1.3、使用数据库
如果表名或者字段名是特殊字符,则需要带``
use 数据库名;
2.1.4、查看数据库
SHOW DATABASES;
2.2、数据库的列类型
2.2.1、数值
数据类型 描述 大小
tinyint 十分小的数据 1个字节
smallint 较小的数据 2个字节
mediumint 中等大小的数据 3个字节
int 标准的整数 4个字节
bigint 较大的数据 8个字节
float 浮点数 4个字节
double 浮点数 8个字节
decimal 字符串形式的浮点数,一般用于金融计算
2.2.2、字符串
数据类型 描述 大小
char 字符串固定大小 0~255
varchar 可变字符串 0~65535
tinytext 微型文本 2^8-1
text 文本串 2^16-1
2.2.3、时间日期
数据类型 描述 格式
date 日期格式 YYYY-MM-DD
time 时间格式 HH:mm:ss
datetime 最常用的时间格式 YYYY-MM-DD HH:mm:ss
timestamp 时间戳,1970.1.1到现在的毫秒数
year 年份表示
2.2.4、null
没有值,未知
不要使用NULL值进行计算
2.3、数据库的字段属性
2.3.1、UnSigned
无符号的
声明了该列不能为负数
2.3.2、ZEROFILL
0填充的
不足位数的用0来填充 , 如int(3),5则为005
2.3.3、Auto_InCrement
通常理解为自增,自动在上一条记录的基础上默认+1
通常用来设计唯一的主键,必须是整数类型
可定义起始值和步长
当前表设置步长(AUTO_INCREMENT=100) : 只影响当前表 当前自增字段的值从100开始累加1
SET @@auto_increment_increment=5 ; 影响所有使用自增的表(全局)
2.3.4、NULL 和 NOT NULL
默认为NULL , 即没有插入该列的数值
如果设置为NOT NULL , 则该列必须有值
2.3.5、DEFAULT
默认的
用于设置默认值
例如,性别字段,默认为"男" , 否则为 “女” ; 若无指定该列的值 , 则默认值为"男"的值
拓展
每一个表,都必须存在以下五个字段:
名称 描述
id 主键(自增)
version 乐观锁
is_elete 伪删除(逻辑删除)(物理删除)
gmt_create 创建时间
gmt_update 修改时间
2.4、创建数据库表
2.4.1、语法
CREATE TABLE IF NOT EXISTS `student`( '字段名' 列类型 [属性] [索引] [注释], '字段名' 列类型 [属性] [索引] [注释], ...... '字段名' 列类型 [属性] [索引] [注释] )[表的类型][字符集设置][注释]
2.4.2、示例
CREATE TABLE IF NOT EXISTS `student`( `id` INT(4) NOT NULL AUTO_INCREMENT COMMENT '学号', `name` VARCHAR(30) NOT NULL DEFAULT '匿名' COMMENT '姓名', `pwd` VARCHAR(20) NOT NULL DEFAULT '123456' COMMENT '密码', `sex` VARCHAR(2) NOT NULL DEFAULT '女' COMMENT '性别', `birthday` DATETIME DEFAULT NULL COMMENT '出生日期', `address` VARCHAR(100) DEFAULT NULL COMMENT '家庭住址', `email` VARCHAR(50) DEFAULT NULL COMMENT '邮箱', PRIMARY KEY (`id`) )ENGINE=INNODB DEFAULT CHARSET=utf8
2.4.3、注意
表名和字段尽量使用``括起来
AUTO_INCREMENT 代表自增
所有的语句后面加逗号,最后一个不加
字符串使用单引号括起来
主键的声明一般放在最后,便于查看
不设置字符集编码的话,会使用MySQL默认的字符集编码Latin1,不支持中文,可以在my.ini里修改
2.4.4、常用命令
SHOW CREATE DATABASE 数据库名;-- 查看创建数据库的语句 SHOW CREATE TABLE 表名;-- 查看表的定义语句 DESC 表名;-- 显示表的具体结构
2.5、修改表
2.5.1、修改语法
-- 修改表名 -- ALTER TABLE 旧表名 RENAME AS 新表名 ALTER TABLE student RENAME AS students; -- 增加表的字段 -- ALTER TABLE 表名 ADD 字段名 列属性 ALTER TABLE students ADD age INT(11); -- 修改表的字段(重命名,修改列的属性) -- ALTER TABLE 表名 MODIFY 字段名 [列属性]; ALTER TABLE students MODIFY age VARCHAR(11);-- 修改列的属性 -- ALTER TABLE 表名 CHANGE 旧名字 新名字 [列属性]; ALTER TABLE students CHANGE age age1 INT(1);-- 字段重命名 -- 删除表的字段 -- ALTER TABLE 表名 DROP 字段名 ALTER TABLE students DROP age1;
2.5.2、删除语法
DROP TABLE [IF EXISTS] 表名
IF EXISTS为可选 , 判断是否存在该数据表
如删除不存在的数据表会抛出错误
2.5.3、示例
-- 删除表(如果存在再删除) DROP TABLE IF EXISTS teachers;
2.5.4、注意
所有的创建和删除尽量加上判断,以免报错
2.6、清空表TRUNCATE
完全清空一个数据库表,表的结构和索引约束不会变!
2.6.1、语法
TRUNCATE 表名;
2.6.2、示例
TRUNCATE students;
2.7、删除表
2.7.1、语法
DROP TABLE 表名;
2.7.2、示例
DROP TABLE students;
3.数据操作语言(DML)
数据库的意义:数据存储,数据管理
3.1、添加insert
3.1.1、语法
INSERT INTO 表名([字段1,字段2..])VALUES('值1','值2'..),[('值1','值2'..)..];
3.1.2、注意:
字段和字段之间使用英文逗号隔开
字段是可以省略的,但是值必须完整且一一对应
3.1.3、示例
可以同时插入多条数据,VALUES后面的值需要使用逗号隔开
-- 普通用法 INSERT INTO `student`(`name`) VALUES ('zsr'); -- 插入多条数据 INSERT INTO `student`(`name`,`pwd`,`sex`) VALUES ('zsr','200024','男'),('gcc','000421','女'); -- 省略字段 INSERT INTO `student` VALUES (5,'Bareth','123456','男','2000-02-04','武汉','1412@qq.com',1);
3.2、修改update
3.2.1、语法
UPDATE 表名 SET 字段1=值1,[字段2=值2...]WHERE 条件[];
3.2.2、示例
-- 修改学员名字,指定条件 UPDATE `student` SET `name`='zsr204' WHERE id=1; -- 不指定条件的情况,会改动所有表 UPDATE `student` SET `name`='zsr204'; -- 修改多个属性 UPDATE `student` SET `name`='zsr',`address`='湖北' WHERE id=1; -- 通过多个条件定位数据 UPDATE `student` SET `name`='zsr204' WHERE `name`='zsr' AND `pwd`='200024';
3.2.3、where条件
操作符 含义
= 等于
<>或!= 不等于
> 大于
< 小于
<= 小于等于
>= 大于等于
BETWEEN…AND… 闭合区间
AND 和
OR 或
3.3、删除 delete
3.3.1、语法
DELETE FROM 表名 [WHERE 条件]
3.3.2、示例
-- 删除数据(避免这样写,会全部删除) DELETE FROM `student`; -- 删除指定数据 DELETE FROM `student` WHERE id=1;
作用:完全删除一个数据库表,表的结构和索引约束不会变!
3.3.3、DELETE和TRUNCATE 和DROP的区别
truncate与drop是DDL语句,执行后无法回滚;delete是DML语句,可回滚。
truncate只能作用于表;delete,drop可作用于表、视图等。
truncate会清空表中的所有行,但表结构及其约束、索引等保持不变;drop会删除表的结构及其所依赖的约束、索引等。
truncate会重置表的自增值;delete不会。
truncate后会使表和索引所占用的空间会恢复到初始大小;delete操作不会减少表或索引所占用的空间,drop语句将表所占用的空间全释放掉。
4.数据库查询语言(DQL)
4.1、语法
SELECT [ALL | DISTINCT] {* | table.* | [table.field1[as alias1][,table.field2[as alias2]][,...]]} FROM table_name [as table_alias] [left | right | inner join table_name2] -- 联合查询 [WHERE ...] -- 指定结果需满足的条件 [GROUP BY ...] -- 指定结果按照哪几个字段来分组 [HAVING] -- 过滤分组的记录必须满足的次要条件 [ORDER BY ...] -- 指定查询记录按一个或多个条件排序 [LIMIT {[offset,]row_count | row_countOFFSET offset}]; -- 指定查询的记录从哪条至哪条
查询数据库数据 , 如SELECT语句
简单的单表查询或多表的复杂查询和嵌套查询
是数据库语言中最核心,最重要的语句
使用频率最高的语句
4.2、前提配置
-- 创建学校数据库 CREATE DATABASE IF NOT EXISTS `school`; -- 用school数据库 USE `school`; -- 创建年级表grade表 CREATE TABLE `grade`( `GradeID` INT(11) NOT NULL AUTO_INCREMENT COMMENT '年级编号', `GradeName` VARCHAR(50) NOT NULL COMMENT '年纪名称', PRIMARY KEY (`GradeID`) )ENGINE=INNODB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8; -- 给grade表插入数据 INSERT INTO `grade`(`GradeID`,`GradeName`) VALUES (1,'大一'),(2,'大二'),(3,'大三'),(4,'大四'); -- 创建成绩result表 CREATE TABLE `result`( `StudentNo` INT(4) NOT NULL COMMENT '学号', `SubjectNo` INT(4) NOT NULL COMMENT '考试编号', `ExamDate` DATETIME NOT NULL COMMENT '考试日期', `StudentResult` INT(4) NOT NULL COMMENT '考试成绩', KEY `SubjectNo` (`SubjectNo`) )ENGINE=INNODB DEFAULT CHARSET=utf8; -- 给result表插入数据 INSERT INTO `result`(`StudentNo`,`SubjectNo`,`ExamDate`,`StudentResult`) VALUES (1000,1,'2019-10-21 16:00:00',97),(1001,1,'2019-10-21 16:00:00',96), (1000,2,'2019-10-21 16:00:00',87),(1001,3,'2019-10-21 16:00:00',98); -- 创建学生表student CREATE TABLE `student`( `StudentNo` INT(4) NOT NULL COMMENT '学号', `LoginPwd` VARCHAR(20) DEFAULT NULL, `StudentName` VARCHAR(20) DEFAULT NULL COMMENT '学生姓名', `Sex` TINYINT(1) DEFAULT NULL COMMENT '性别,取值0或1', `GradeID` INT(11) DEFAULT NULL COMMENT '年级编号', `Phone` VARCHAR(50) NOT NULL COMMENT '联系电话,允许为空,即可选输入', `Adress` VARCHAR(255) NOT NULL COMMENT '地址,允许为空,即可选输入', `BornDate` DATETIME DEFAULT NULL COMMENT '出生时间', `Email` VARCHAR(50) NOT NULL COMMENT '邮箱账号,允许为空,即可选输入', `IdentityCard` VARCHAR(18) DEFAULT NULL COMMENT '身份证号', PRIMARY KEY (`StudentNo`), UNIQUE KEY `IdentityCard` (`IdentityCard`), KEY `Email` (`Email`) )ENGINE=MYISAM DEFAULT CHARSET=utf8; -- 给学生表插入数据 INSERT INTO `student`(`StudentNo`,`LoginPwd`,`StudentName`,`Sex`,`GradeID`,`Phone`,`Adress`,`BornDate`,`Email`,`IdentityCard`) VALUES (1000,'1241','dsaf',1,2,'24357','unknow','2000-09-16 00:00:00','1231@qq.com','809809'), (1001,'1321','dfdj',0,2,'89900','unknow','2000-10-16 00:00:00','5971@qq.com','908697'); -- 创建科目表 CREATE TABLE `subject`( `SubjectNo` INT(11) NOT NULL AUTO_INCREMENT COMMENT '课程编号', `SubjectName` VARCHAR(50) DEFAULT NULL COMMENT '课程名称', `ClassHour` INT(4) DEFAULT NULL COMMENT '学时', `GradeID` INT(4) DEFAULT NULL COMMENT '年级编号', PRIMARY KEY (`SubjectNo`) )ENGINE=INNODB AUTO_INCREMENT=18 DEFAULT CHARSET=utf8; -- 给科目表subject插入数据 INSERT INTO `subject`(`SubjectNo`,`SubjectName`,`ClassHour`,`GradeID`) VALUES(1,'高数','96',2),(2,'大物','112',2),(3,'程序设计',64,3);
4.2、基础查询
4.2.1、语法
SELECT 查询列表 FROM 表名;
查询列表可以是:表中的(一个或多个)字段,常量,变量,表达式,函数
查询结果是一个虚拟的表格
4.2.2、示例
-- 查询全部学生 SELECT * FROM student; -- 查询指定的字段 SELECT `LoginPwd`,`StudentName` FROM student; -- 别名 AS(可以给字段起别名,也可以给表起别名) SELECT `StudentNo` AS 学号,`StudentName` AS 学生姓名 FROM student AS 学生表; -- 函数 CONCAT(str1,str2,...) SELECT CONCAT('姓名',`name`) AS '新名字' FROM student; -- 查询系统版本(函数) SELECT VERSION(); -- 用来计算(计算表达式) SELECT 100*53-90 AS 计算结果; -- 查询自增步长(变量) SELECT @@auto_increment_increment; -- 查询有哪写同学参加了考试,重复数据要去重 SELECT DISTINCT `StudentNo` FROM result;
4.3、条件查询
where 条件字句:检索数据中符合条件的值
4.3.1、语法
select 查询列表 from 表名 where 筛选条件;
4.3.2、示例
-- 查询考试成绩在95~100之间的 SELECT `StudentNo`,`StudentResult` FROM result WHERE `StudentResult`>=95 AND `StudentResult`<=100; -- && SELECT `StudentNo`,`StudentResult` FROM result WHERE `StudentResult`>=95 && `StudentResult`<=100; -- BETWEEN AND SELECT `StudentNo`,`StudentResult` FROM result WHERE `StudentResult`BETWEEN 95 AND 100; -- 查询除了1000号以外的学生 SELECT `StudentNo`,`StudentResult` FROM result WHERE `StudentNo`!=1000; -- NOT SELECT `StudentNo`,`StudentResult` FROM result WHERE NOT `StudentNo`=1000; -- 查询名字含d的同学 SELECT `StudentNo`,`StudentName` FROM student WHERE `StudentName` LIKE '%d%'; -- 查询名字倒数第二个为d的同学 SELECT `StudentNo`,`StudentName` FROM student WHERE `StudentName` LIKE '%d_'; -- 查询1000,1001学员 SELECT `StudentNo`,`StudentName` FROM student WHERE `StudentNo` IN (1000,1001);
4.4、分组查询
4.4.1、语法
select 分组函数,分组后的字段 from 表 [where 筛选条件] [group by 分组的字段] [having 分组后的筛选] [order by 排序列表]
4.4.2、示例
-- 查询不同科目的平均分、最高分、最低分且平均分大于90 -- 核心:根据不同的课程进行分组 SELECT SubjectName,AVG(StudentResult),MAX(`StudentResult`),MIN(`StudentResult`) FROM result r INNER JOIN `subject` s on r.SubjectNo=s.SubjectNo GROUP BY r.SubjectNo HAVING AVG(StudentResult)>90;
4.4.3、where和having的区别
**
使用关键字 筛选的表 位置
分组前筛选 where 原始表 group by的前面
分组后筛选 having 分组后的结果 group by 的后面
使用HAVING 可以对分完组之后的数据进行进一步过滤
HAVING不能单独使用,HAVING不能代替WHERE
HAVING必须和GROUP BY 联合使用
优化策略: WHERE 和 HAVING , 优先选择 WHERE , WHERE实在完成不了,再选择HAVING
4.5、连接查询
4.5.1、左连接
左表的记录会全部显示出来 , 而右表只会显示符合匹配条件的记录 , 匹配不到的显示为NULL
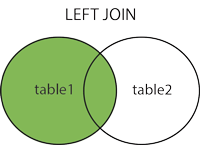
SELECT s1.*, s2.* FROM students_copy1 s1 LEFT JOIN students_copy2 s2 ON s1.id = s2.id;
4.5.2、右连接
右表的记录会全部显示出来 , 而左表只会显示符合匹配条件的记录 , 匹配不到的显示为NULL
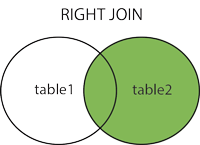
SELECT s2.*, s1.* FROM students_copy2 s2 RIGHT JOIN students_copy1 s1 ON s1.id = s2.id;
4.5.3、内连接
显示左表和右表符合匹配条件的记录
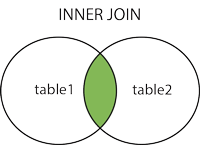
SELECT s2.*, s1.* FROM students_copy2 s2 INNER JOIN students_copy1 s1 ON s1.id = s2.id;
4.5.4、竖表连接
显示表1和表2的所有记录
union : 会删除数据的重复集
union all : 会删除数据的重复集
select * from students_copy1 union all select * from students_copy2
4.6、排序
4.6.1、语法
select 查询列表 from 表 where 筛选条件 order by 排序列表 asc/desc
order by的位置一般放在查询语句的最后(除limit语句之外)
| asc : | 升序,如果不写默认升序 |
| — | — |
| desc: | 降序 |
4.6.2、示例
SELECT`StudentNo`,`StudentName`,`GradeName` FROM student s ORDERBY `StudentNo` DESC;
4.7、分页
4.7.1、语法
select 查询列表 from 表 limit offset,pagesize;
offset代表的是起始的条目索引,默认从0开始
size代表的是显示的条目数
offset=(n-1)*pagesize
-- 第一页 limit 0 5
-- 第二页 limit 5,5
-- 第三页 limit 10,5
-- 第n页 limit (n-1)*pagesize,pagesize
-- 第一页 limit 0 5 -- 第二页 limit 5,5 -- 第三页 limit 10,5 -- 第n页 limit (n-1)*pagesize,pagesize -- pagesize:当前页面大小 -- (n-1)*pagesize:起始值 -- n:当前页面 -- 数据总数/页面大小=总页面数 -- limit n 表示从0到n的页面
4.7.2、示例
SELECT * FROM students LIMIT 0,5
4.8、子查询
本质:在 where子句中嵌套一个子查询语句
4.8.1、示例
-- 查询‘课程设计’的所有考试结果(学号,科目编号,成绩)降序排列 -- 方式一:使用连接查询 SELECT `StudentNo`,r.`SubjectNo`,`StudentResult` FROM result r INNER JOIN `subject` s on r.StudentNo=s.SubjectNo WHERE SubjectName='课程设计' ORDER BY StudentResult DESC; -- 方式二:使用子查询(由里到外) SELECT StudentNo,SubjectNo,StudentResult from result WHERE SubjectNo=( SELECT SubjectNo FROM `subject` WHERE SubjectName='课程设计' )
4.9、DISTINCT 去重
SELECT DISTINCT NAME FROM students_copy1
4.10、BETWEEN AND 范围查询
SELECT DISTINCT NAME FROM students_copy1 WHERE id BETWEEN 1 AND 7
4.11、LIKE模糊查询
select * from students_copy1 WHERE name LIKE '%三%' select * from students_copy1 WHERE name LIKE '李%' select * from students_copy1 WHERE name LIKE '%四' select * from students_copy1 WHERE name LIKE '_三_' select * from students_copy1 WHERE name LIKE '_三' select * from students_copy1 WHERE name LIKE '李_'
4.12、IN 范围查询
select * from students_copy1 where id in ('8','6')