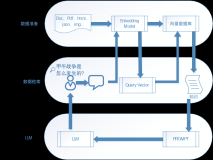
上节课,我带领小伙伴们完成了baichuan2量化模型的本地部署和基本用例测试。没有看过的小伙伴可以点击链接查看,AI大模型私有部署的技术指南
但是仅仅完成模型的部署和启动离通过LangChain来调用模型还差一步。今天这节课我就将带领小伙伴们将这未完成的一步补全,实现私有大模型OpenAI标准接口封装,并完成LangChain对大模型的调用与测试。本次课程提纲如下,今天主要讲适配提供通用OpenAI-API接口的部分。
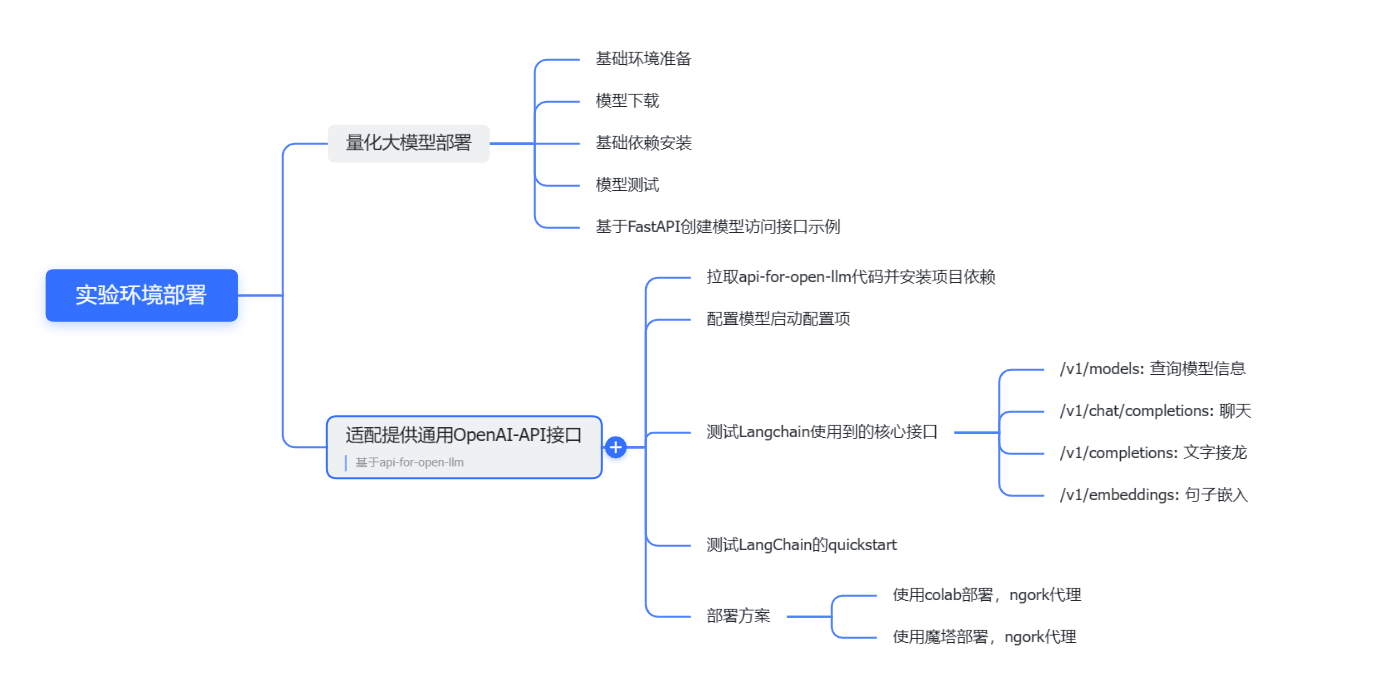
适配提供通用OpenAI-API接口
要让LangChain能够调用我们部署在本地或者私有网络中的AI大模型,我们需要提供一个符合OpenAI-API标准的接口,这样LangChain就可以通过统一的方式来访问我们的模型。为了方便我们实现这个接口,我们可以使用一个开源的项目:api-for-open-llm,它是一个基于FastAPI和transformers的项目,可以快速地将任何基于transformers的语言模型封装成一个OpenAI-API风格的接口。
拉取api-for-open-llm代码并安装项目依赖
要使用api-for-open-llm项目,我们首先需要将它的代码拉取到我们的开发环境中,并安装它的项目依赖。我们可以通过以下步骤来操作:
- 在开发环境中打开一个终端窗口,并执行以下命令:
git clone https://github.com/xusenlinzy/api-for-open-llm.git cd api-for-open-llm pip install -r requirements.txt
这样就完成了api-for-open-llm项目的代码拉取和依赖安装。
配置模型启动配置项
拉取并安装好api-for-open-llm项目后,我们还需要对它进行一些配置,以便于它能够正确地加载我们的baichuan2量化模型,并提供相应的接口。我们可以通过以下步骤来配置:
- 在api-for-open-llm项目中创建
.env文件,并配置以下内容:
# 启动端口 PORT=8000 # model 命名 MODEL_NAME=baichuan2-13b-chat # 将MODEL_PATH改为我们的baichuan2量化模型所在的文件夹路径 MODEL_PATH=/content/baichuan-inc/Baichuan2-13B-Chat-4bits # device related # GPU设备并行化策略 DEVICE_MAP=auto # GPU数量 NUM_GPUs=1 # 开启半精度,可以加快运行速度、减少GPU占用 DTYPE=half # api related # API前缀 API_PREFIX=/v1 # API_KEY,此处随意填一个字符串即可 OPENAI_API_KEY=
这样就完成了api-for-open-llm项目的配置。
测试Langchain使用到的核心接口
配置好api-for-open-llm项目后,我们就可以启动它,并测试它提供的接口是否符合Langchain使用到的核心接口。我们可以通过以下步骤来测试:
- 在终端窗口中执行以下命令:
cp api-for-open-llm/api/server.py api-for-open-llm/ python api-for-open-llm/server.py > server.log 2>&1 &
这样就启动了api-for-open-llm项目,监听在8000端口。
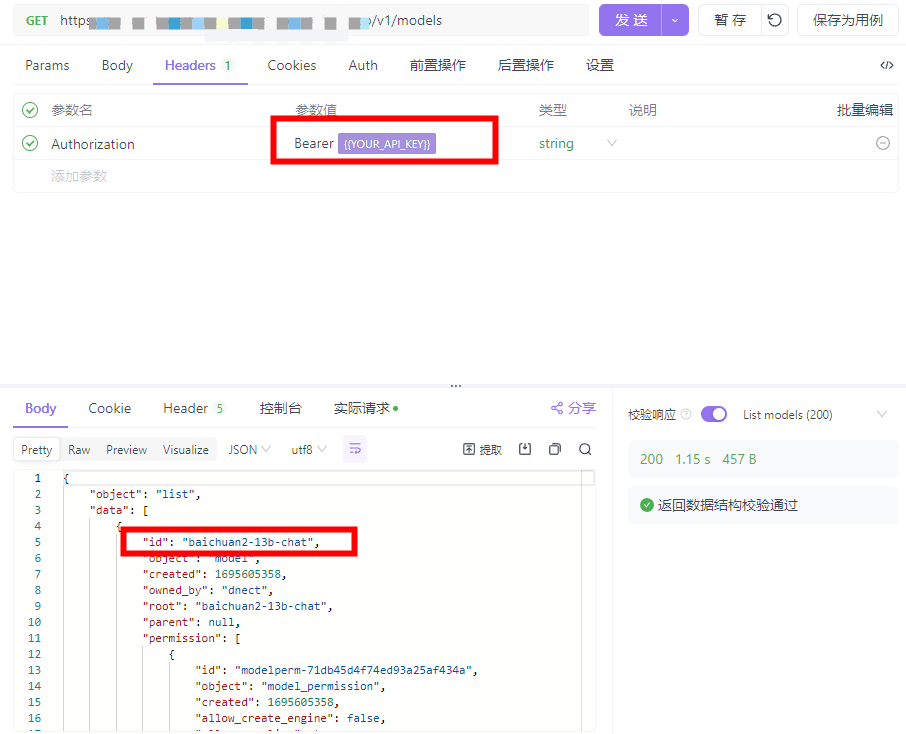
- 接口测试,我们可以通过接口调用工具测试以下几个接口来验证项目的部署情况,请求前需要在请求header中配置Authorization参数,配置内容为Bearer {{YOUR_API_KEY}}
- /v1/models: 查询模型信息,执行结果如下
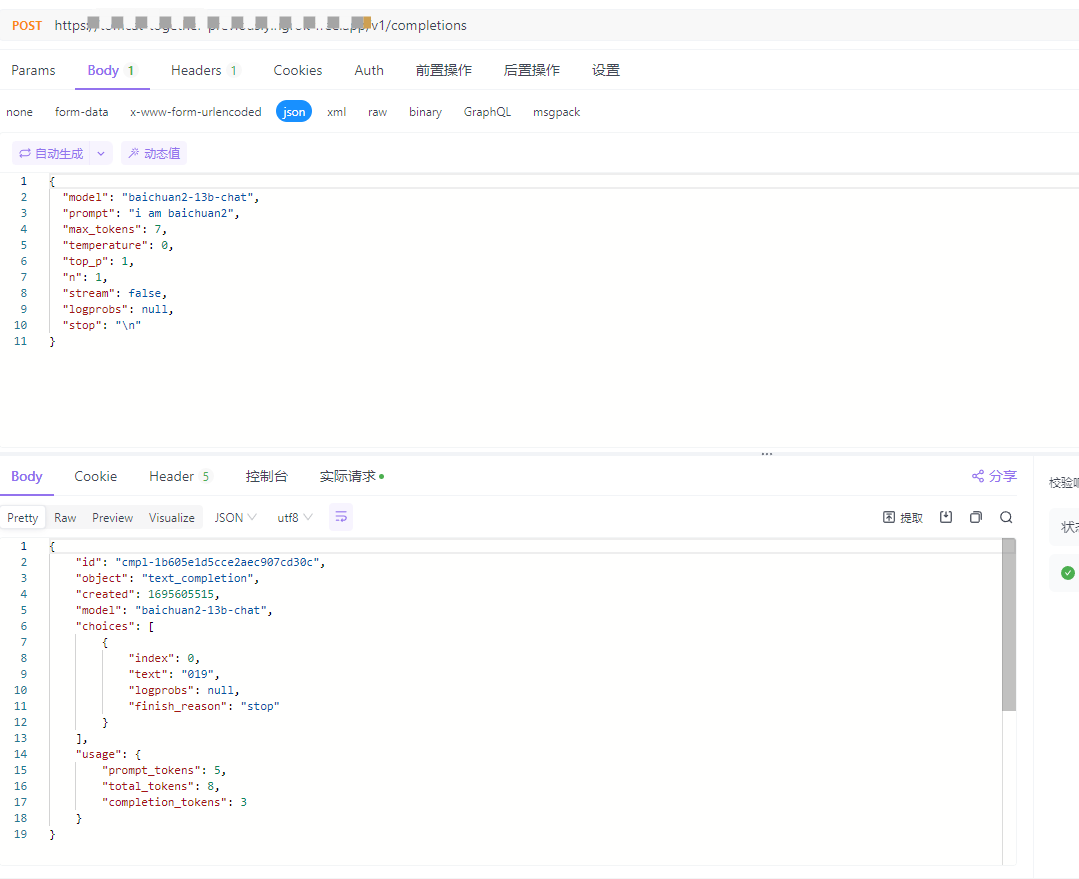
- /v1/completions: 文字接龙,执行结果如下
测试LangChain的quickstart
测试好api-for-open-llm项目提供的核心接口后,我们就可以使用LangChain来调用我们部署在本地或者私有网络中的AI大模型了。以LangChain的quickstart为例,步骤如下:
- 首先安装Langchain包
# 安装Langchain包 pip install langchain # Use OpenAI's model APIs pip install openai
- 执行以下代码
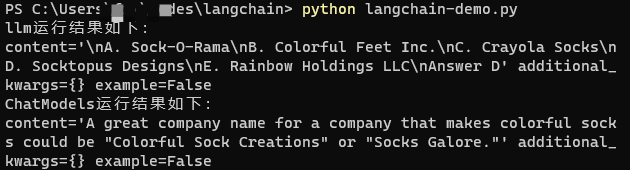
from langchain.llms import OpenAI from langchain.chat_models import ChatOpenAI from langchain.schema import HumanMessage # 修改为你自己配置的OPENAI_API_KEY api_key = "" # 修改为你启动api-for-open-llm项目所在的服务地址和端口 api_url = "https://localhost:8000/v1" modal= "baichuan2-13b-chat" llm = OpenAI(model_name=modal,openai_api_key=api_key,openai_api_base=api_url) chat_model = ChatOpenAI(model_name=modal,openai_api_key=api_key,openai_api_base=api_url) text = "What would be a good company name for a company that makes colorful socks?" messages = [HumanMessage(content=text)] #LLMs: this is a language model which takes a string as input and returns a string print("llm运行结果如下:") print(llm.predict_messages(messages)) #ChatModels: this is a language model which takes a list of messages as input and returns a message print("ChatModels运行结果如下:") print(chat_model.predict_messages(messages))
这样就完成了LangChain对我们部署在本地或者私有网络中的AI大模型的调用与测试。运行结果如下图所示。
部署方案
在本地或者私有网络中部署AI大模型并使用LangChain调用它是一种方便和安全的方式,但是它也有一些局限性,例如需要占用本地或者私有网络中的计算资源和存储空间,以及需要保持网络连接的稳定性。因此,如果我们想要更灵活和高效地部署和使用AI大模型,我们可以考虑以下两种部署方案:
使用ModelScope魔搭部署,ngork代理
魔搭是阿里发布的基于阿里云端资源的AI开发平台,它提供了专业的AI硬件和软件资源,以及丰富的AI应用和服务。新用户注册赠送36小时的GPU使用时长,可以白嫖用来进行大模型部署测试。

我们可以利用魔搭来部署我们的AI大模型,并通过ngork代理来将其暴露给外部网络。这样我们就可以享受魔塔提供的高性能和高质量的AI环境,以及提高网络连接的可靠性。我们可以通过以下步骤来实现这种部署方案:
- 在浏览器中打开魔搭网站(https://www.modelscope.cn/my/mynotebook/preset),并注册一个账号(使用阿里云账号亦可)。
- 点击
我的Notebook菜单,启动GPU示例并创建一个新的笔记本。
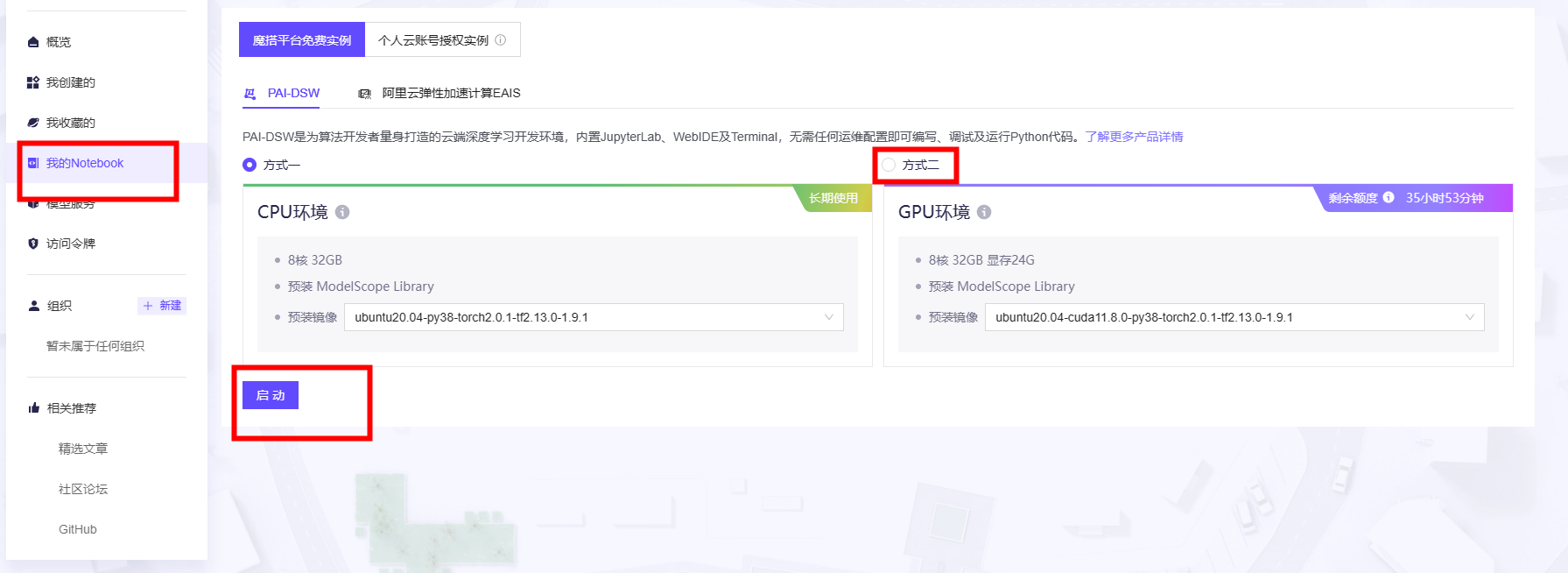
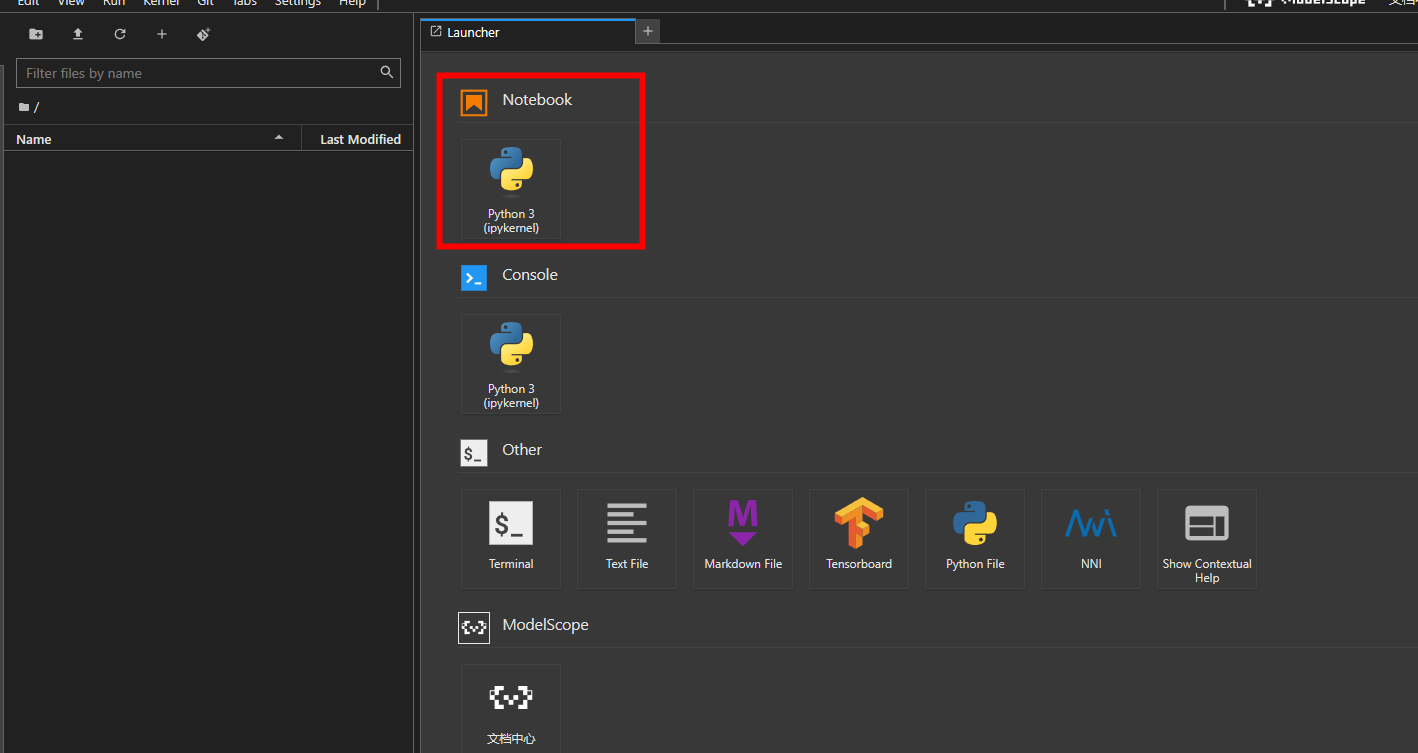
- 按上节课教授的内容下载模型(魔搭内置模型下载缓存加速可通过下图代码快速下载模型),并按这节课的内容启动Open-API接口


- 注册ngork,并获取ngork访问token后配置服务代理,生成ngork访问地址
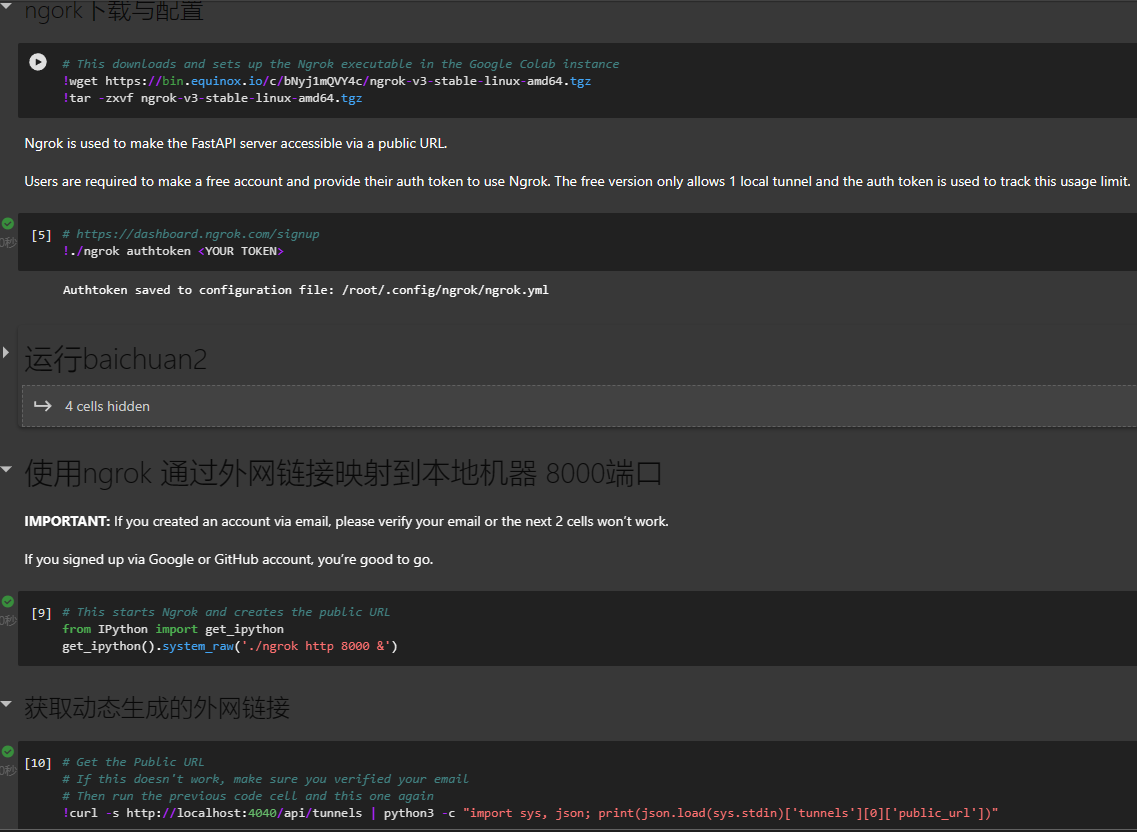
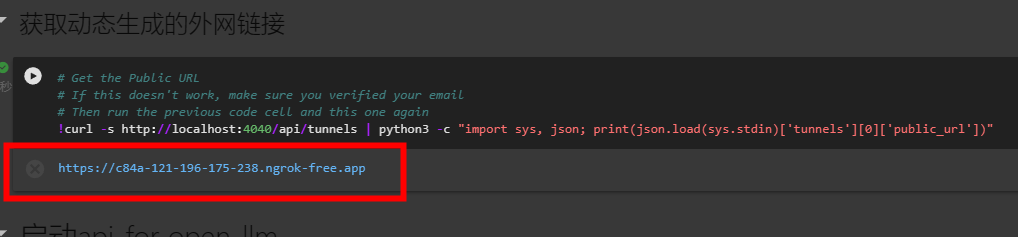
这样就完成了在魔搭中部署AI大模型并通过ngork代理访问它的过程。我们可以使用之前输出的URL来测试我们的模型,或者在LangChain中添加一个新的模型,并使用该URL作为模型地址。魔搭的notebook可以通过文件直接导入,通过如下链接获取导入文件:
使用colab部署,ngork代理
具备网络访问条件的可以考虑使用google的colab部署,它提供了免费的GPU和TPU资源,以及丰富的Python库和工具。我们可以利用colab来部署我们的AI大模型,并通过ngork代理来将其暴露给外部网络。这样我们就可以节省本地或者私有网络中的计算资源和存储空间,以及提高网络连接的可靠性。我们可以通过以下步骤来实现这种部署方案:
- 在浏览器中打开colab网站(https://colab.research.google.com/),并登录一个Google账号。
- 在colab网站中,点击
File菜单下的New notebook选项,创建一个新的笔记本。 - 按上节课的内容下载模型,并按这节课的内容启动Open-API接口
 4. 注册ngork,并获取ngork访问token后配置服务代理,生成ngork访问地址
4. 注册ngork,并获取ngork访问token后配置服务代理,生成ngork访问地址

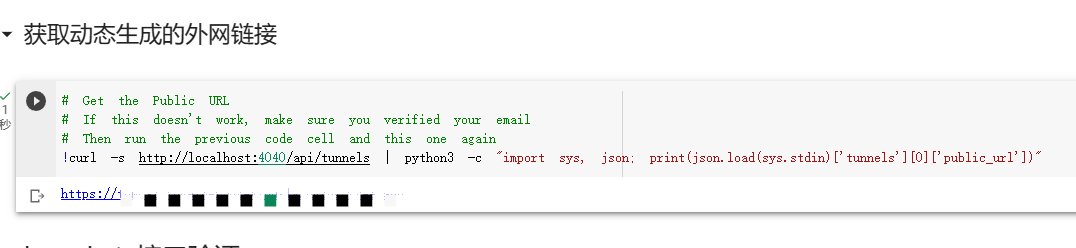
这样就完成了在colab中部署AI大模型并通过ngork代理访问它的过程。我们可以使用之前输出的URL来测试我们的模型,或者在LangChain中添加一个新的模型,并使用该URL作为模型地址。colab的notebook可以通过文件直接导入,通过如下链接获取导入文件:
总结
本文介绍了如何在LangChain开发环境中准备AI大模型私有部署的技术指南,以baichuan2量化模型为例,分别介绍了适配提供通用OpenAI-API接口、测试LangChain的quickstart和部署方案的步骤和代码。通过本文的指导,读者可以在LangChain开发环境中轻松地部署和使用AI大模型,享受AI大模型带来的强大能力和价值。
下一节课我们将正式进入LangChain-AI应用开发的课程,我将给大家讲解LangChain应用架构中6大基础核心组件,请大家持续关注。